## 什么是什么?
**chat**:聊天,AI的特定应用
**G:generative AI 生成式AI** 一种人工智能算法。生成式AI可以通过学习现有数据的规律来创建全新的数据,所以非常适合于创造性任务。例如通过生成式AI的算法可以生成绘画、音乐、文学作品、电影剧本等等。对比于搜索引擎的[[BOK 知识图谱]]
对应人类的学习,学习者自己生成的知识,相对于**费曼式学习**,必须是基于理解的知识才能更加牢固。并且在我们可以有创造性的输出之前,我们需要通过curious阶段和serious阶段的大量输入积累。
**P:pre-trained 预训练**
海量数据训练神经网络。对应人类的学习,练习。
**T:[[Transformer]] 变形器,一种神经网络**
多层的自注意力机制,更好的捕捉文本、概念之间的关系,识别模式。模拟人脑的神经网络。
# 实例
# 类比、比较与对比
## 关系
**OpenAI ChatGPT GPT-3 的关系**
- OpenAI是一个人工智能研究机构。
- GPT-3 是基于transformer模型的自然语言处理模型,用大量数据训练出的模型,具有很强的理解力和语言生成能力。对比于人类相当于人类的大脑,GPT-3是ChatGPT的大脑。
- ChatGPT是GPT-3的应用场景
**ChatGPT与AI的关系**
- 如果把AI比作硅基生命,ChatGPT是AI下的一个“物种”(类型)。AI下还有其他类型,比如人脸识别、相机美颜、物体检测,图像分类。
- 同一类型的GPT AI还有 GPT-1 GPT-2 CPT-3。
- 如果把AI比做“人科”,chatGPT也许属于“智人”,还有尼安德特人、大猩猩等等其他物种,之后还会有各种各样,层出不穷的“chatGPT"。
**GPT是基于什么数据训练出来的?**
GPT-3,2020通过哪些数据来训练?Google的LaMDa2训练数据量更大。数据质量决定了AI的质量。
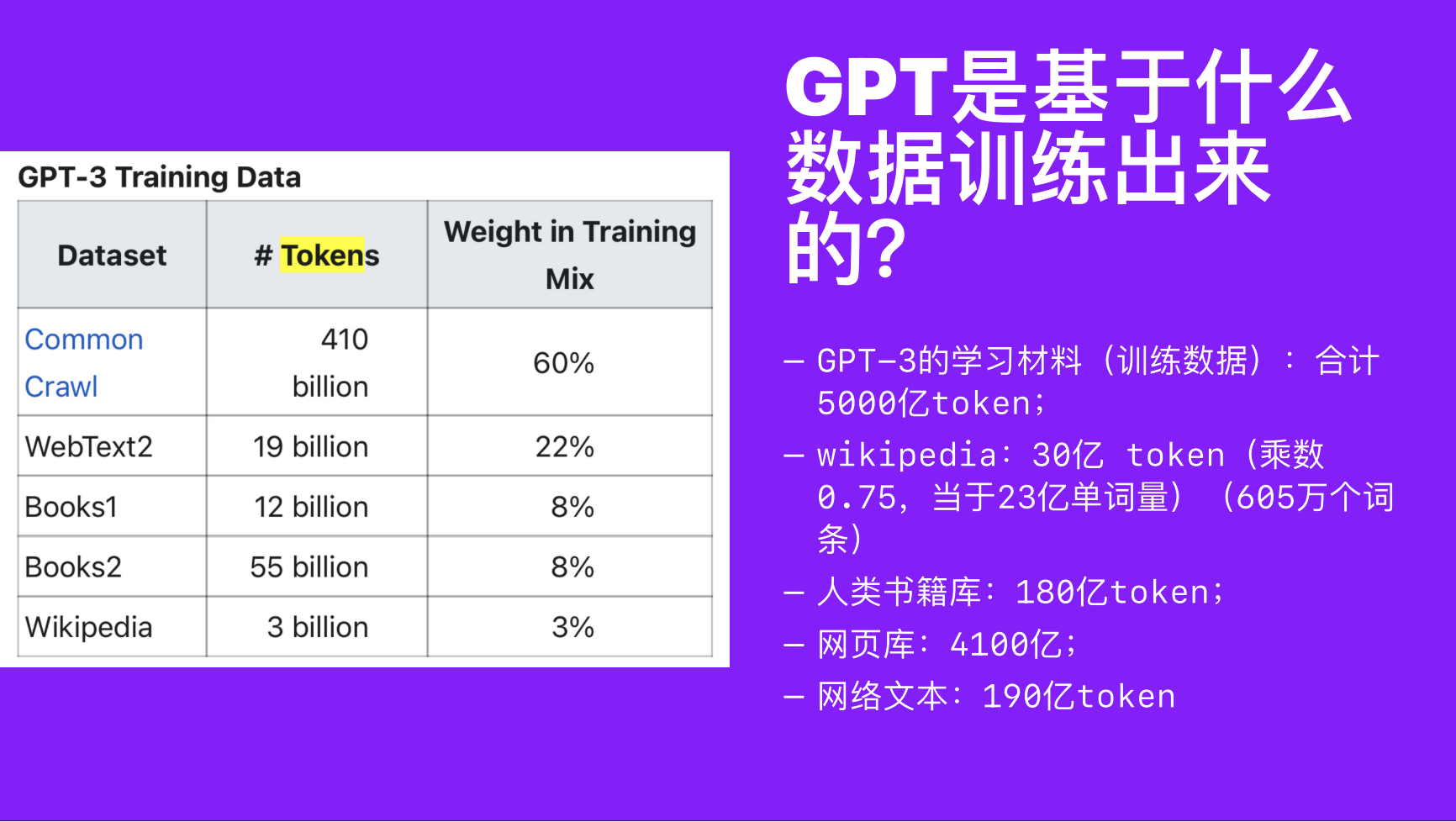
信息流质量决定了生命的质量,训练AI的数据决定了AI是否真的“只能”,不能只看数据量大多少,更要看质量。在GPT-3的训练数据中,全人类的书籍和全部维基百科的词条它都学完了,但加起来却只占GPT-3训练数据的19%。
**AI是不是比谁的数据量大?那岂不是越没底线的公司越强大?** 信息流质量决定生命质量。
# 与我何干
**我们与AI的关系** 人机共生的关系。AI是可以帮助我们更好地学习的强大工具。比如可以让chatGPT帮助我们做主题研究,辅助阅读。
# 备注
- readwise
- bing搜索引擎
- openai网站
- [厘清概念](https://www.candobear.com/p/t_pc/course_pc_detail/video/v_63eb3bbae4b0fc5d1231907f)