- Objective:
- Breadcrumb:
# 概念阐释
知识图谱(knowledge graph)是一种用于存储实体之间关系的图形数据库。知识图谱通常由节点(node)代表**实体**(人物、地点、事物)和**边**(关系)组成。知识图谱是 AI 的知识体系。
# 实例
## 搜索引擎
- 我们每天使用的搜索引擎,背后运用的就是知识图谱。百度和[Google的知识图谱](https://en.wikipedia.org/wiki/Google_Knowledge_Graph),由50亿个实体和5000亿条知识构成,平均来看每个实体都有100个关联。这个大型知识库需要用到搜索引擎公司大量的人力和物力
- 如何从实体到一条[[事实性知识 factual knowledge#^be85d1|事实性知识]]?(也叫做“语义网”)
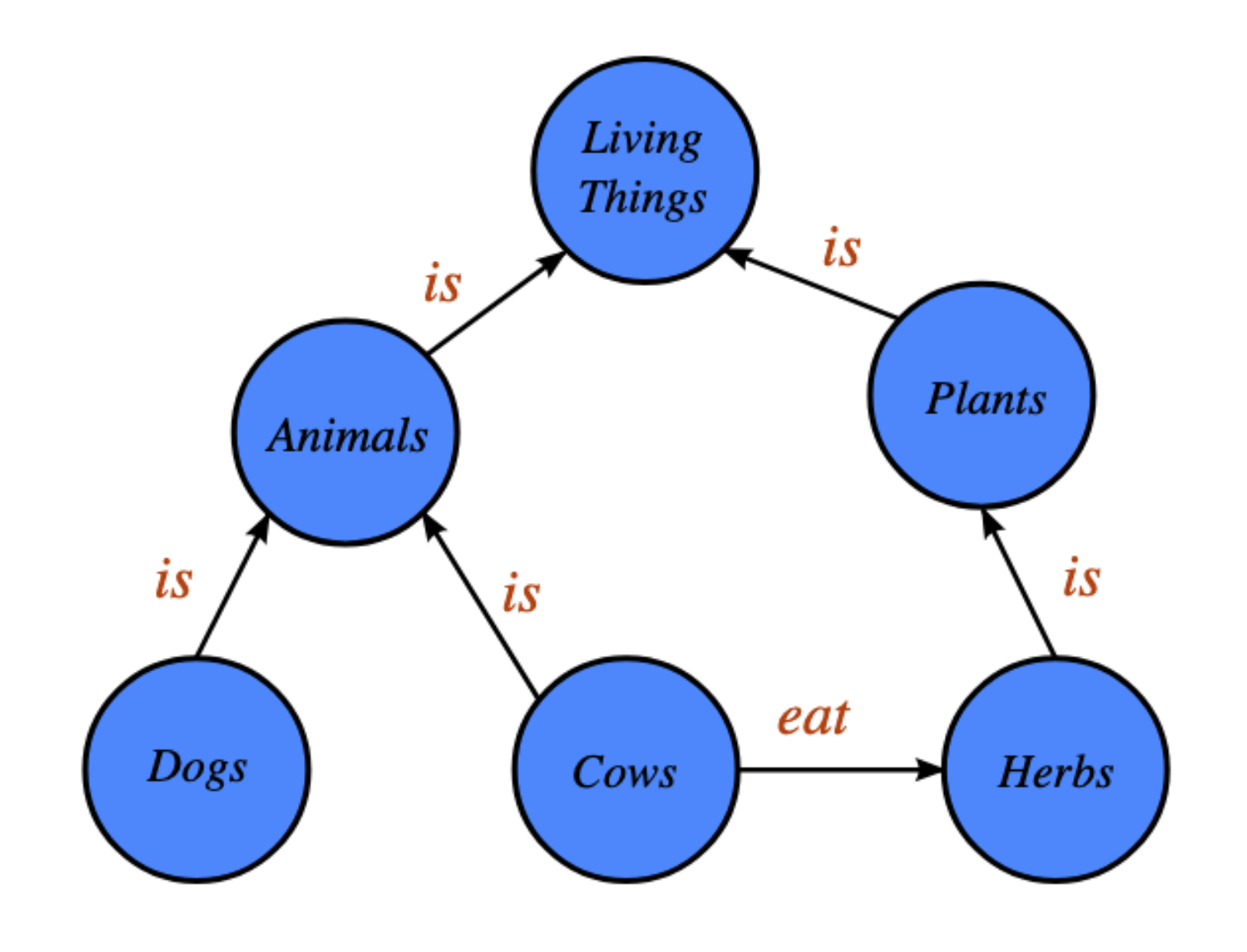
- **实体**:living things, animals, plants, dogs, cows, herbs
- 事实性知识:
- living things is animals
- animals is dogs
- cows eat herbs
- 当我们提出一个搜索请求时,搜索引擎会在这个50亿实体的网络上快速搜索,调用到相关概念和事实并进行加工,提供更高质量、更结构化的结果。
把实体(包括事实性知识和抽象概念)以及实体之间的关系结构化,来改善搜索结果,这就类似于学习者个人投入大量时间和注意力,通过长期学习构建出个人知识库,来改善学习效果。Obsidian 和 Logseq 这样的个人知识库软件,引入了知识图谱概念,通过图谱可以看到[[BOK 知识网络]]的生长过程。
# 相关内容
## 知识图谱与[[ANN 人工神经网络]]的区别
- 知识图谱存储着实体之间的事实性知识,明确地从“知识库”中提取答案
- 人工神经网络并不依赖预先定义的、硬编码的实体和关系,而是从海量文本中学习语言模式、概念和知识,相当于对人类所有知识进行了理解和概括。然后根据用户输入的提示([[prompt]])、问题,基于学习过的知识来生成答案。这也意味着生成知识的准确性和可靠性也面临着挑战。
# 参考资料
- [知识图谱-Wikipedia](https://zh.wikipedia.org/wiki/%E7%9F%A5%E8%AD%98%E5%9C%96%E8%AD%9C)
- [你一生的笔记系统](https://mp.weixin.qq.com/s/m_asDyCHR19UO6cUfHIjOw)
- [1.3 从学习科学视角的解释](https://www.candobear.com/p/t_pc/course_pc_detail/image_text/i_65b63adbe4b064a8cb1e53b7?community_id=c_65b634d2dd106_nhCXKYc72308&product_id=course_2ba4aSp8cPi3TjgH1xc2GxANJHL)