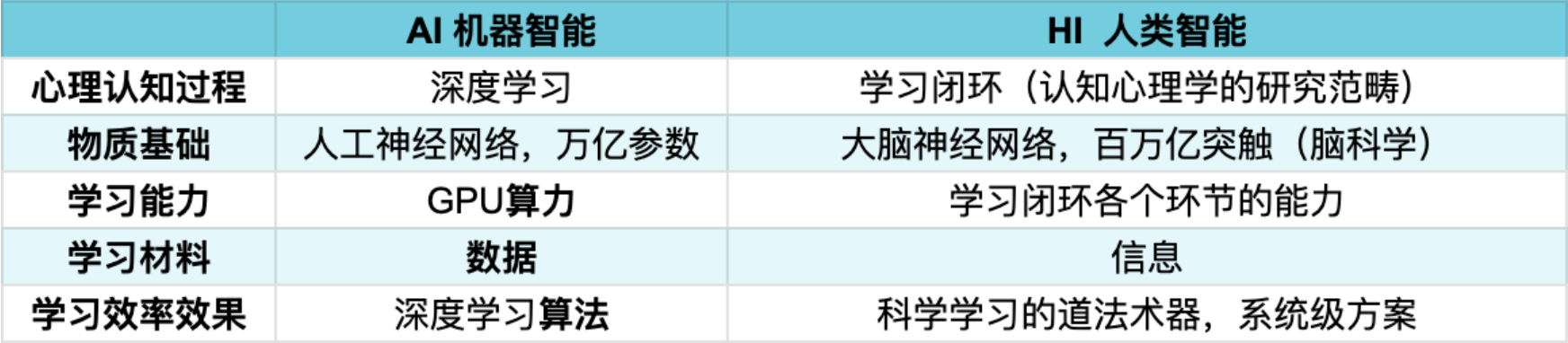
为什么学习效率效果是算法?
| | 大脑神经网络 | 大语言模型/人工神经网络 | o1 | [[BOK 知识图谱]] |
| ---------- | --------------------------------------------------------- | ------------------------------------------------------------------------- | ---------- | --------------------------------------------------------------------- |
| **硬件基础** | 1000 亿个[[孩子天生爱学习 神经元构造\|神经元]],150 万亿个[[孩子天生爱学习 突触\|突触]]联接 | 通过海量互联网文本的自主学习后获得的「参数」(GPT-3 1750 亿,GPT-4据估计 1.8 万亿),参数相当于是对人类互联网文本的有损压缩。 | | 50 亿个实体,5000 亿条关系 |
| **工作原理** | 生成:每生成一次概念时,是大脑神经网络中数千个**突触联结**的一次放电。 | 生成:每生成一个 token 时是万亿[[parameters 参数]]构成的神经网络的一次激活。 | [[CoT]]思维链 | 调用:当我们提出一个搜索请求时,搜索引擎会在这个50亿实体的网络上快速搜索,调用到相关概念和事实并进行加工,提供更高质量、更结构化的结果。 |
| **心理认知过程** | [[人,是如何学习的#^62da6f\|学习闭环]] | 机器学习:[[Deep Learning 深度学习]]+人类微调 | | 搜索引擎公司投入人力物力构建的知识库 |
| **学习能力** | 学习闭环各个环节的能力 | GPU 算力 | | CPU |
| **学习材料** | [[信息]] | 数据:从海量文本中学习语言模式、概念、知识。模型并不存储数据,而是通过学习获得这些知识并存储在「参数」中。 | | |
| **学习效率效果** | 科学学习的道法术器,系统级方案 | 深度学习算法[[Transformer]] | | |
| **结果** | 回答是基于平时学习的知识的理解和概括。 | 基于神经网络对人类文本的理解和概括。并非基于硬编码、验证过的事实,所以在生成的准确性和可靠性方面还面临挑战,会存在幻觉。 | | 调用时依赖于硬编码的实体和关系。 |
| **心理认知过程** | 长时记忆 | LLM 的[[parameters 参数\|参数]],2/3 的参数都存储在[[MLP 多层感知器]]中 | | |
| **心理认知过程** | 工作记忆 | [[context length 上下文长度]]、[[自注意力机制]]模块 | | |
| | system1+system2 | system1 | system2 | |
## 对比学习过程
| 训练过程 | [[GPT的训练过程(archive)]] | 人类的学习过程 | o1 |
| -------------------- | -------------------------------------------------------------------------------- | ------------------------------------- | --------------------------------------------------- |
| [[Pre-training 预训练]] | - 互联网上的海量文本,万亿 token;<br>- 预测下一个 token[[预测即压缩压缩即智能,智能即具备理解力]];<br>- 训练占比 99% 以上; | - 学校教育之外的大量课外阅读;<br>- 边阅读边在脑子里预测下一个词; | |
| [[SFT 监督微调]] | - 用人类的反馈对原始网络进行微调;<br>- 少而精,只占训练的百分之几; | - 课堂教育、主题阅读<br>- 有正确答案的反馈,是教育中的「教」; | [[深度解读“强化微调”,o1模型训练的关键\|强化微调]] |
| [[RM 奖励模型]] | 针对一个问题提供多种答案,不同答案对应不同的奖励; | - 相当于学习者的“三观”建设;<br>- 奖励建模就类似教育的「育」; | |
| [[RLHF 基于人类反馈的强化学习]] | 基于外部反馈来调整自己的学习行为;小样本的推理训练。 | 基于外部环境导向,调整学习行为。考前做题训练。 | [[深度解读“强化微调”,o1模型训练的关键\|强化微调]],思维链训练;解题元技能、推理能力。 |
- - [2.6 信息素养与学习成绩](https://readwise.io/reader/shared/01jdjqcax8yvn3y2sqnxgg1wrp)
## 人类擅长 vs GPT 擅长
- 人类擅长
- 创造性思考
- 对情境的深度理解:人,人的问题,生活
- 价值判断的能力:信仰、信念
- 人类情感:同情心、理解力
- GPT 擅长
- 世界知识模型
- 推理模型:强悍的推理能力
- 信息处理能力:数据处理、高速计算、外部的信息获取
# ref.
- [人类学习分两种:模仿学习 GPT和试错学习o1](https://btcml.xetslk.com/s/18VpIf)