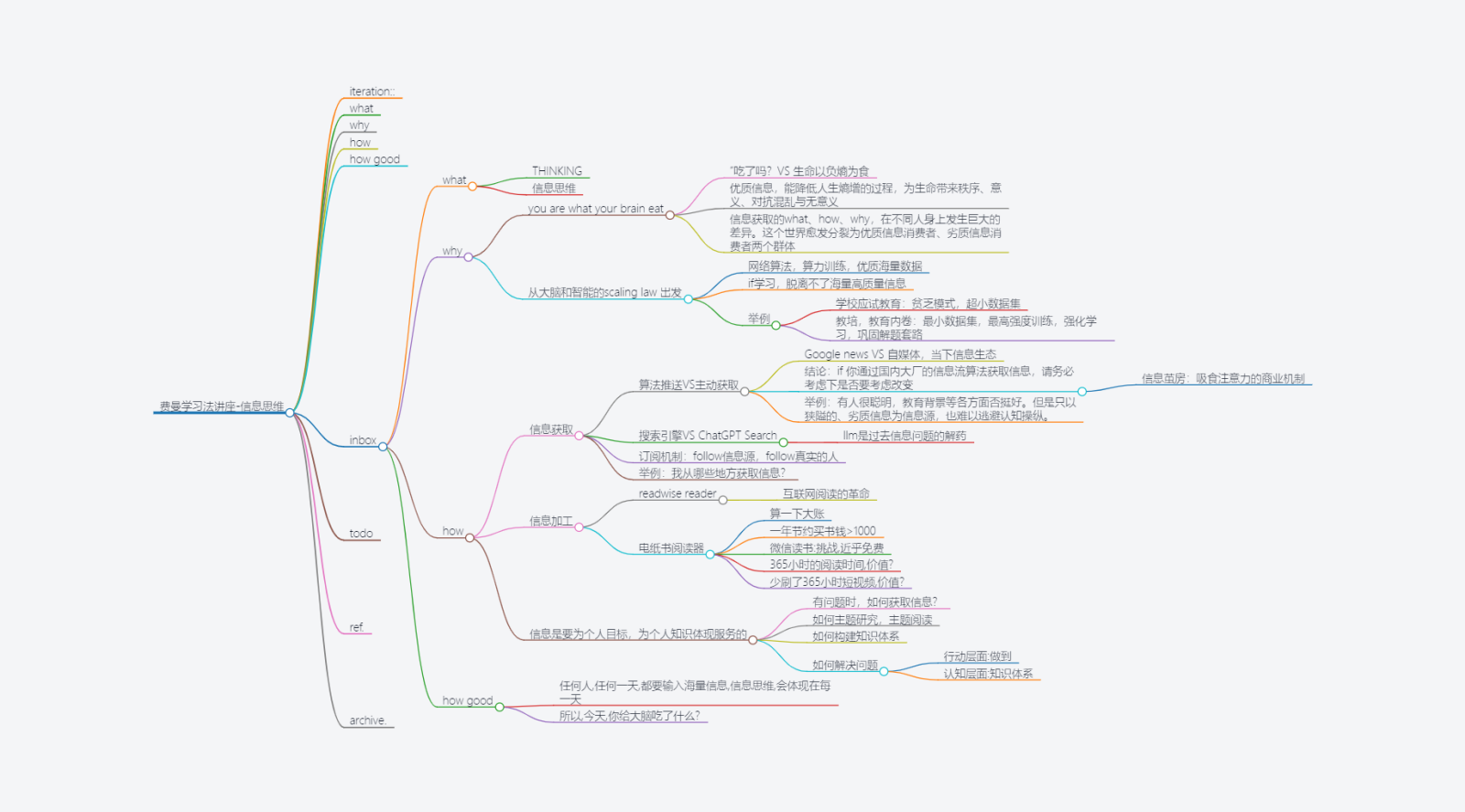
# what
- 信息思维
# why
- you are what your brain eats
- 生命以负熵为食
- [[优质信息 vs 劣质信息|优质信息]]能够降低人生熵增的过程
- 信息获取的what why how在不同人身上会有巨大的差异,这个世界愈发分裂为优质信息消费和劣质信息消费的两个群体
- 从大脑和智能的 scaling law 出发
- [[规模法则 scaling laws]],训练大模型使用的是高质量的海量数据
- if 学习,离不开海量高质量信息
# how
## 信息获取
- 算法推送 vs 主动获取
- 费曼日报
- follow 人 [[Howie.serious]],[[MzSavage]]
- 搜索引擎 vs [[SearchGPT]]
- 订阅机制:follow 信息源,follow 真实的人
- YouTube 和 x 的收集是我目前可能会用到的
## 信息加工
- Readwise reader
- **[[标签 tags]]**:听完直播后我发现还可以再继续添加细分的 tags,读完后添加笔记,然后在用的时候,在标签里进行筛选,就不用每周在 logseq 里整理了。
- [[电纸书阅读器]]
## 信息服务于人的目标
- **关键在用**:搜集信息不是为了搜集而搜集,而是为了做自己的主题研究、主题阅读、构建自己的知识体系,解决问题
- 平时积累关注领域的相关信息,创建自己的「信息时空」,用的时候通过标签检索调用
# how good
- 解决了什么问题?
- 解决了我对于信息、笔记记不全的焦虑。我们不是为了搜集信息而搜集信息,我们是为了构建个人知识体系来解决问题,所以才去搜集信息。因此不管是笔记还是信息,当我要用到的时候,主动搜索和加工的过程自然会把我牵引回去,因此不用为了笔记记不全、信息收集的不够而焦虑。只要记住,以“构建个人知识体系,解释世界,解决问题”。
# Ref.
- [信息思维讲座-follow 展示](https://readwise.io/reader/shared/01jer3eyyvhxqmk5qna33mt0m7)
- [原视频](https://www.candobear.com/p/t_pc/course_pc_detail/video/v_6736f9cee4b023c058a4ffa7?community_id=c_65b634d2dd106_nhCXKYc72308&product_id=course_2oES9sPVnM5lAGuFT4GYoxAPSW5)