- # why
- # what
- Train-time Compute(训练时计算)指的是**机器学习模型在[[LLM 预训练|训练阶段]]中所消耗的计算资源**。
- 这个阶段的主要任务是不断地优化和调整参数,最终得到一个在[[推理阶段]]能够准确预测并生成下一个 token的模型。
- 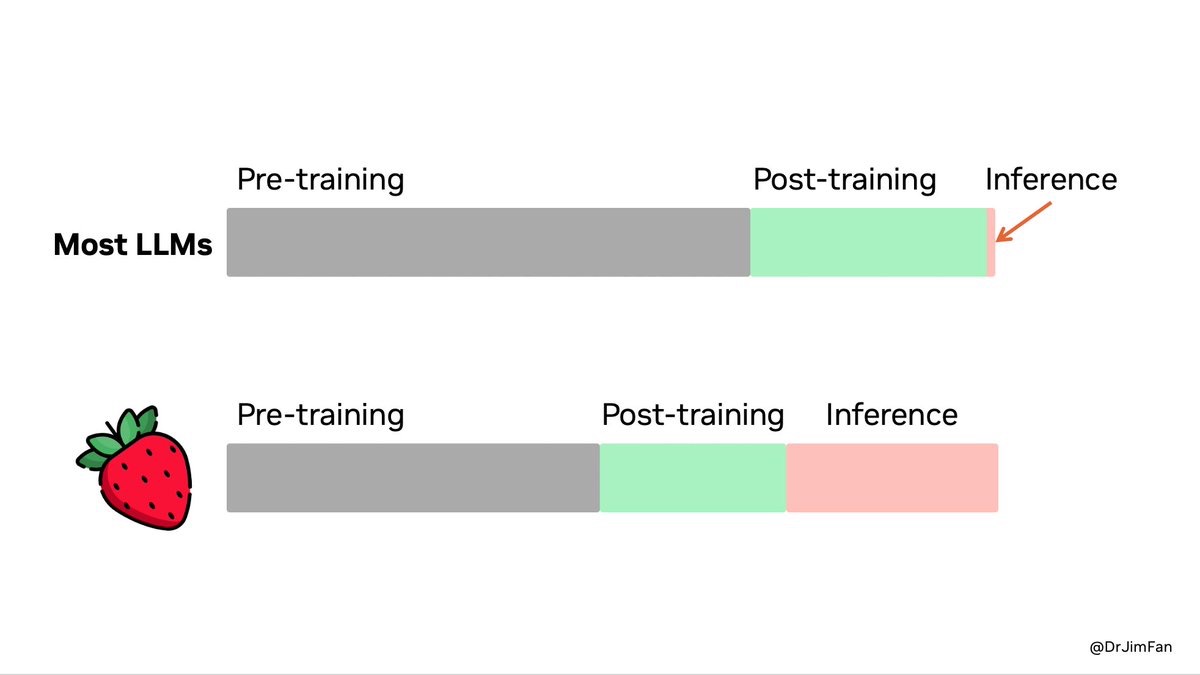
- # how
- ## **Train-time Compute vs. Test-time Compute**
|**维度**|**Train-time Compute**|**Test-time Compute**|
|---|---|---|
|**阶段**|训练(Training)|推理(Inference)|
|**计算目标**|学习模型参数|生成预测结果|
|**计算量**|大,通常是推理的**千倍到百万倍**|相对较小(但依赖模型优化)|
|**优化方式**|混合精度训练、数据并行、模型并行|量化、剪枝、MoE|
|**主要瓶颈**|计算资源、显存、时间|低延迟、低功耗|
**直观类比**:
- **Train-time Compute**:就像大学学习,需要花很多时间学习和训练。
- **Test-time Compute**:就像参加考试,用学过的知识快速解题。
- ## train-time compute主要用于模型训练的以下几个方面
- 模型大小和参数数量:模型越大、参数越多,需要的计算量越大,因为在训练过程中需要对这些**参数**进行反复更新和优化。
- 数据量:数据量越大,计算需求越高。在训练开始前,必须对数据进行清洗、增强以及切分,确保能够以合适的批量大小([[batch size]])和格式输入到模型中。
- 训练轮次[[epochs]]:多轮训练,每一轮都要进行一次完整的[[向前传播]]和[[Backpropagation 反向传播算法|反向传播]]来更新**权重**。轮次越多,计算要求越高。
- 优化算法:模型通过[[gradient descent 梯度下降]]在优化参数,也是 train-time compute 计算的一部分。
- # how good
- # Ref.
- [ChatGPT-train-time compute](https://readwise.io/reader/shared/01jjkjeawjt6cyexc2gdyt0qft)