- # why
- ## LLM(GPT)模型为什么要用 token?
- 之所以需要词元化是因为计算机无法读取人类语言的字符或单词,所以我们要将互联网上抓取的原生数据转换成机器能够理解的数字。
- 所以在数据集进入大模型前,需要对自然语言的文本进行编码,但为什么不使用现有的编码方式?
- **节省计算资源**:神经网络的训练资源极其宝贵,所以要尽可能地节省计算资源:
- 单单英语单词就有 100 多万个,如果支持成百上千种语言就需要千万量级的词汇量。而且人类语言的词汇也是不断更新的,模型的**[[词汇表]]**则不能;
- 词汇表决定了 [[Embedding]]嵌入环节的 token embedding matrix 的矩阵大小,矩阵越大,计算资源越高。
- **不能实时更新**:
- LLM 训练不是实时的:[[Unicode 字符编码]] 有 15 万之多,而且还在不断发生变化,但是大语言模型的训练不是实时变化的,所以词汇表也不能随时更新;但是拆解成单词片段就可以进行组合,发明新单词。
- **总体原则**
- 把`01`组成的 2symbol, but long sequence的编码转换为more symbol, short sequence的词汇表
- 词汇表数量比较适合的范围是 10 万左右。GPT-3:50257 token;GPT-4:100277个 token 可能性(*经过测试发现的一个比较适合的词汇表大小*);
- # what
- 将文本转换成 token 的过程叫做Tokenization词元化,过程可以说是一种无损翻译。
- **Tokenization**:词元化,转换过程;
- **Token**:词元,文本的最小不可分割单位,词元可以是某个单词的一部分,也可以单词、标点、数字、符号、空格; 1token≈4个字符≈0.75 word、0.5汉字(对于中英文的区别,GPT中文下的认知能力大概是英文认知能力的80%左右,不影响认知,而占用的内存和花费是重要影响);
- **[[词汇表]] vocabulary size**:
- # how
- ## 分词算法
- **BPE(Byte-Pair Encoding)**
- **原理**:BPE 通过不断合并频率最高的字符对来生成新的token,直到产生一个词汇表。它是基于子词的分词方法,可以有效地覆盖常用词和词片段。
- **应用**:BPE 是许多基础模型(如 **GPT-2**、**GPT-3**、和一些机器翻译模型)的主要分词算法。它能灵活地处理拼写变体、词根和词缀等。
- **优点**:能够平衡词汇表大小和模型的泛化能力,有效减少 OOV(超出词汇表)的情况。
- **WordPiece**
- **原理**:类似于 BPE,WordPiece 也是基于子词单元的分词方法,但在合并子词时采用的是基于最大似然估计的策略,从而更适合语言建模任务。
- **应用**:WordPiece 是 Google 的 **BERT** 和其他 Transformer 模型的主要分词方法,擅长处理更复杂的词语和短语。
- **优点**:在处理词义多样性和罕见词方面表现较好,适合在需要高精度语言理解的任务中使用。
- **SentencePiece**
- **原理**:SentencePiece 不是依赖于单词的分词算法,而是将整个句子作为一个字符串来处理。它使用的是一种统一的分词策略,可以生成独立于语言的 token。
- **应用**:SentencePiece 常被用于 **LLaMA、T5、XLNet** 等模型中,特别适用于多语言场景和多任务学习。
- **优点**:可以直接处理未经分词的文本,包括非空格分隔语言(如中文、日文等),在多语言场景下具有优势。

- # 实例
- 5000 个文本≈40,000bits≈5000byte≈1300 gpt-4 token(4o 更短)
- ## text - token ID
- raw text: 从互联网上抓取的数据,但是神经网络不能识别 text
- 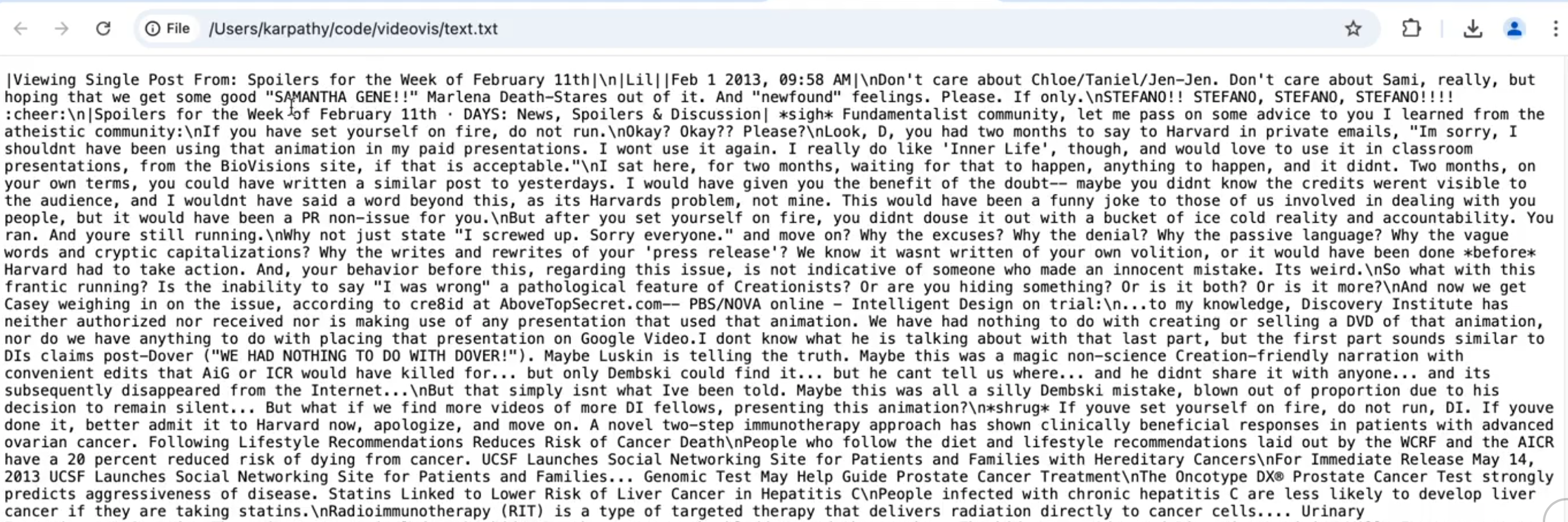
- text turn to bit :每一个字母、符号在计算机中都被转换为 8 个 bit 的表示,但是有 2 个 symbol 表示的文字会太长,神经网络的训练资源极其宝贵
- 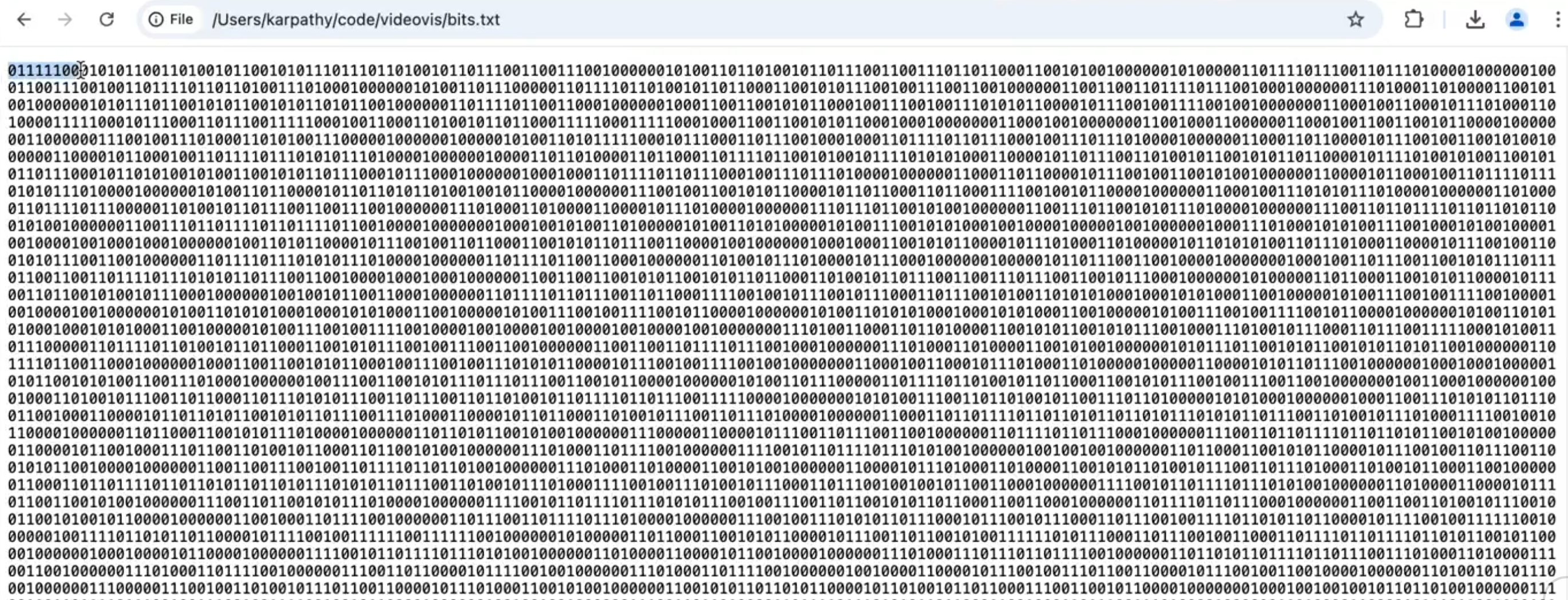
- bit turn to byte: 将 8 个 bit 组合成 1 个字节,这样的组合有$2^8=256$种可能性,给种可能性都有一个唯一序列号,从 1-256(十进制表示的序列号 )
- 
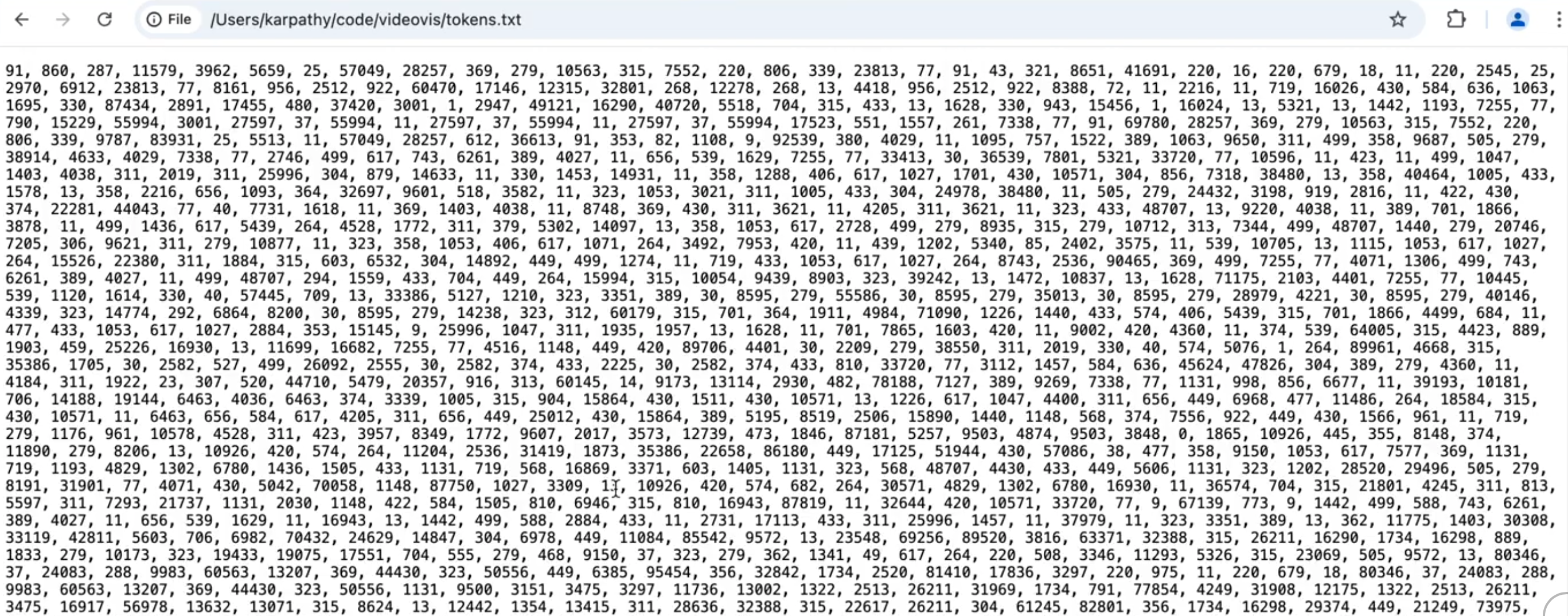
- byte to token:即便是转换成字节,数据的长度还是太长,因为会有很多重复的组合,因此再通过字节编码对算法,将字节转换成 token,跟进实际测试,10 万种可能的组合是最佳方案,所以 token 是一系列从 1-100000 的整数序列
- 
- ## BPE 实例
假如我们的数据集里有下面这些词,并且出现频率为:
`("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)`
当前的 vocabulary为:
`["b", "g", "h", "n", "p", "s", "u"] `
我们将每个单词分割成字符:
`("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)`
合并频次最高的字词对,这里是`"u","g"`,出现了 20 次,合并后的结果为:
```
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug"]
Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
```
再次合并频次最高的字词对,`"u","n"`,出现了 16 次,合并后的结果为:
```
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)
```
`"h","ug"`出现了 15 次,合并后的结果为:
```
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
Corpus: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
```
...
最终合并完成的 token 及词汇表,例如 GPT-3 的词汇表为 50257 个 token,每一个 token 都会分配一个唯一的 token ID。
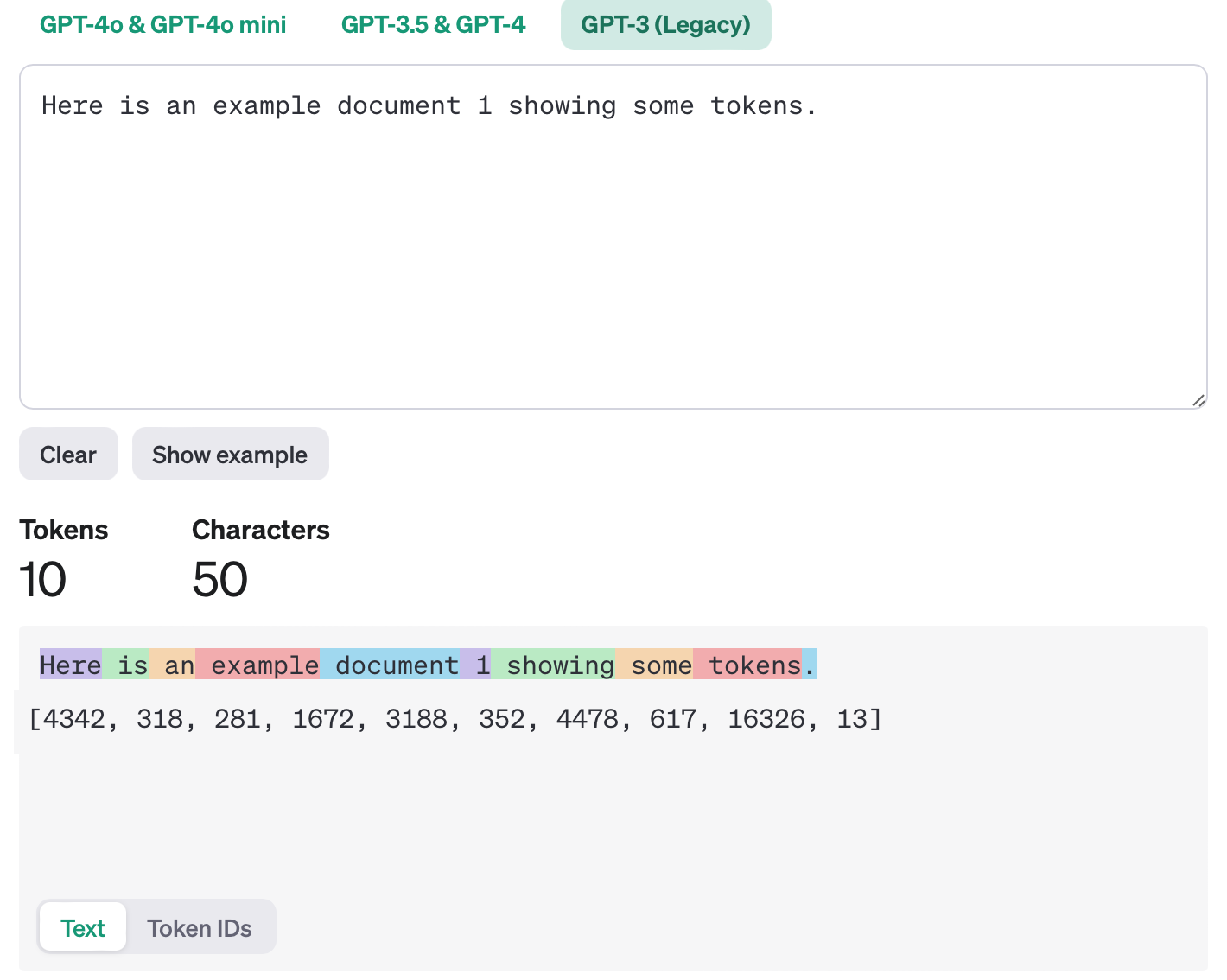{:height 564, :width 696}
- # how good
- [[为什么 AI 数不清 strawberry 里有几个 r?]]
- ## token与人类学习的关系
- 首先人类语言不过是载体、媒介,人类文明的知识大厦才是语言中的本质,所以我们不靠单独的汉字、英文字母来理解世界,而是靠[[知识砖块]];
- 所以token 之于大语言模型就像知识砖块之于人类,都是 chunk 层面的;
- token 就是大语言模型的最小知识单位。
- # Ref.
- [token](https://btcml.xet.tech/s/3qzAey)
- [BPE - hugging face](https://readwise.io/reader/shared/01jaxzsa86z6rx4w1fxwpmd6rd)
- [ ] 《这就是ChatGPT》p63
- [ ] [# Let's build the GPT Tokenizer](https://www.youtube.com/watch?v=zduSFxRajkE&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=9&t=2s)
- [3.6 费曼大法 - 上:知识砖块](https://readwise.io/reader/shared/01je4nmdpzpkdb954k0wvf0q7d)
- [playground-tokenizer](https://platform.openai.com/tokenizer)
- [[Deep Dive into LLMs like ChatGPT]]