- Objective: 深度学习工作原理的雏形
- Breadcrumb: 人工神经网络
# 概念阐释
感知器是人工智能历史上最早的人工神经网络之一,由康奈尔大学的弗兰克·罗森布拉特Frank Rosenblatt在 1957 年发明。罗森布拉特借鉴人工神经元、人工神经网络的概念提出机器可以模拟人类的感知,所以称为「感知机」。感知器是具有单一人造神经元的网络。它被发明用来解决的问题是,能够**学习**如何将图案进行分类的学习[[algorithm 算法]]。
## 学习算法
- 感知机学习
- [[最小二乘法]]
- [[梯度下降 SGD]]
## 工作原理
感知器作为一种单层神经网络(只有一个神经元细胞),是最简单的[[前馈神经网络]](从输入到输出的单向传播),包括多个输入和1个输出,并且是一种二元线性分类,即输出结果只有 0 或 1。这也是为什么感知器不能解决[[异或 XOR]]问题。
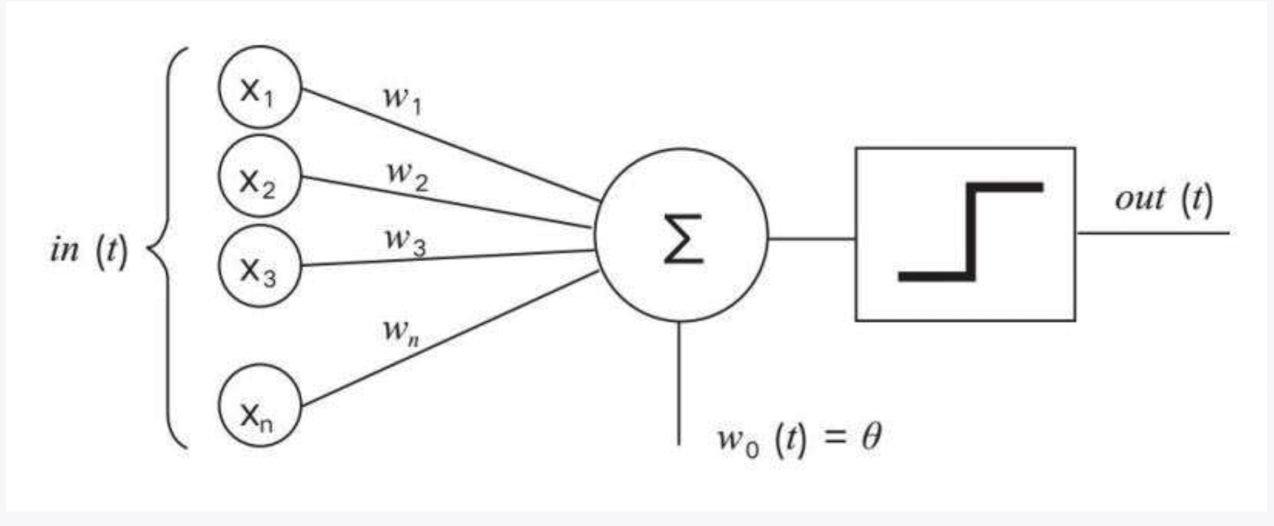
1. **阶跃函数**:[[activation function 激活函数]]](如示意图中的方块形状),神经元。这个函数的作用是根据求和的结果决定输出是0或是 1。这一函数决定了感知器可以将结果分成两类。
2. **输入(in(t))**:每个输入($x_1$, $x_2$, ..., $x_n$)可能**代表了图片的不同特征**,这是用来训练感知器的**样本**。比如颜色、形状、大小等。对于猫和狗的图案分类,这些输入可能包括图像的边缘信息、特定的纹理信息等。
3. **[[weights 权重]]($w_1$, $w_2$, ..., $w_n$)**:每个输入特征都有一个相应的权重(weights),**这些权重决定了相应特征在最终决策中的重要性**。例如,如果形状对于区分猫和狗是一个关键因素,那么形状特征对应的权重就会较高。在感知器模型中,"权重"(weights)是用来衡量每个输入特征对模型输出决策的重要性或贡献的参数。
4. **求和单元(Σ)**:这个单元将每个输入乘以其相应的权重,并加总起来。$∑i=1,…,n wi xi$ 与阈值`θ`进行比较后的结果被传递给阶跃函数。
5. **输出(out(t))**:如果总和超过阈值`θ`,阶跃函数输出 1,图像处于类别中;如果总和未超过阈值`θ`,阶跃函数输出 0,图像不在类别中。
表达式:$f[w \cdot x + b]$
- $f$ 表示激活函数
- $w$ 表示权重
- $x$ 表示前一层神经元的值
- $b$ 表示常量
- 结果为输出而计算的求和函数是n维空间中的一个**超平面**。感知器这种神经网络“分类”的本质就是这个超平面将空间分成了两部分,即[[perceptron 感知器#^a8c3f3|线性分类器]]。
# 实例
- 1957年在IBM704完成了感知机仿真
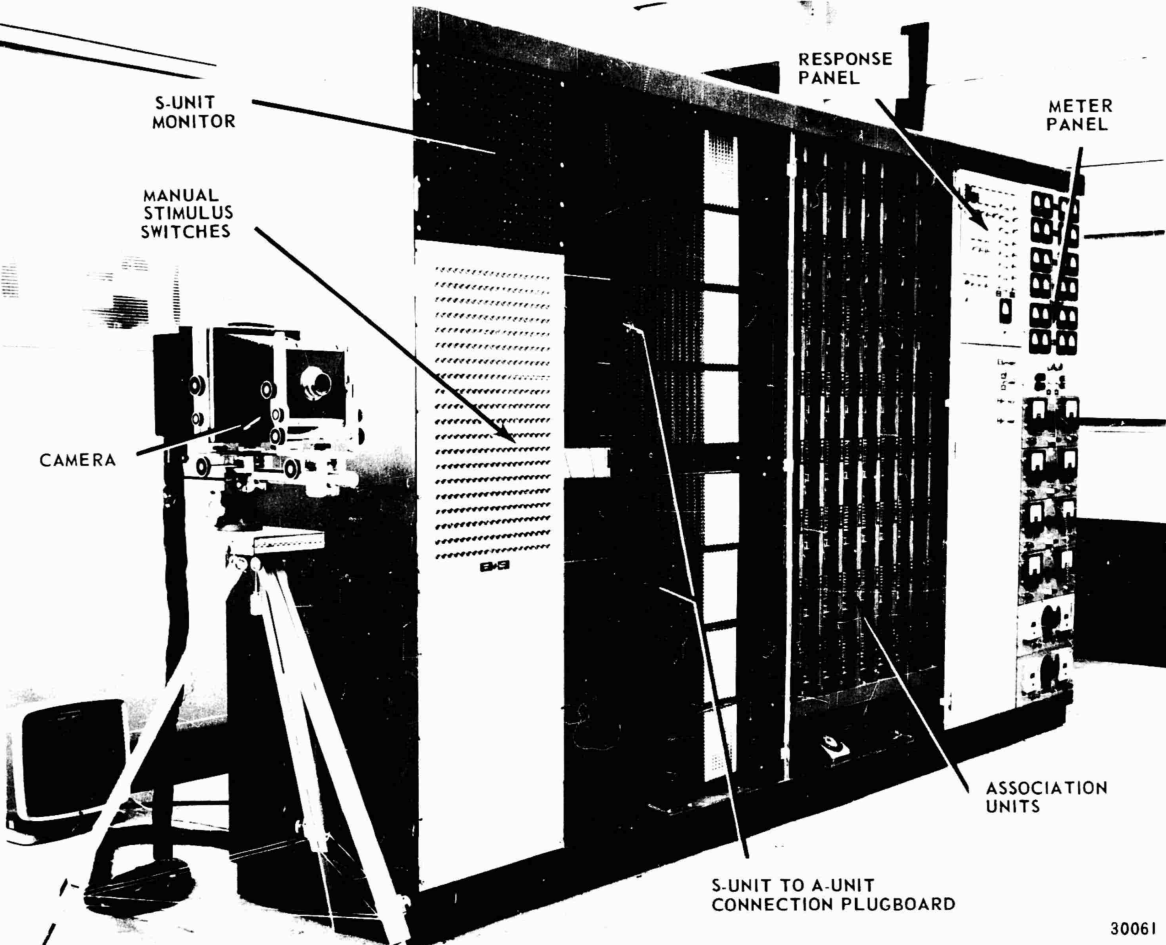
- 1960 年完成了==Mark I Perceptron==
- 
- 识别英文字幕
- 识别字母表中的不同字母
- 识别猫
- 区分性别
- 谢诺夫斯基实验室的研究院训练感知器识别性别的准确度达到 81% 和 88%。
- 比阿特丽斯训练了多层感知器,准确度达到了 92%。
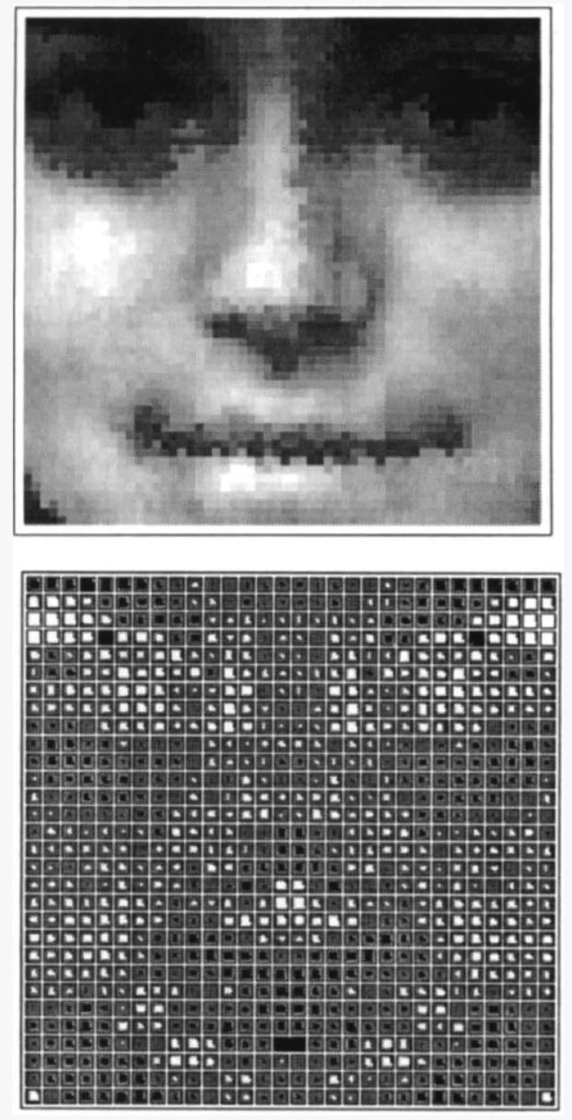
> 人们通过训练感知器来辨别男性和女性的面孔。来自面部图像(上图)的像素乘以相应的权重(下图),并将该乘积的总和与阈值进行比较。每个权重的大小被描绘为不同颜色像素的面积。正值的权重(白色)表现为男性,负值的权重(黑色)倾向于女性。鼻子宽度,鼻子和嘴之间区域的大小,以及眼睛区域周围的图像强度对于区分男性很重要,而嘴和颧骨周围的图像强度对于区分女性更重要。
# 相关内容
## 历史
- 1943 年由麦卡洛克和皮茨合作的论文中提出了[[ANN 人工神经网络]]、人工神经元的概念。
- *罗森布拉特的研究工作不仅实现了麦卡洛克和皮茨的想法,还结合了哈佛大学心理学家斯金纳(B. F.Skinner)提出的补充假设,对神经元的基本模型进行了扩展。斯金纳认为,==有些输入对神经元行为的影响更大,这就好比不同的读者可能会对阅读的内容产生不同程度的信任和怀疑。==如果允许这些影响随着时间的推移而变化,随着任务的成功或失败而增强或减弱,那么从本质上看,神经元网络本质上就可以进行学习了。==罗森布拉特运用相关原理,设计了一个由400个光传感器组成的像素为20的摄像头。他把每个传感器的输出连接到感知机上,让感知机学会识别视觉模式,比如识别面前的索引卡上绘制的形状。由于每个传感器的初始影响权重是随机设置的,因此系统对所见图像的分类也是随机的。而罗森布拉特就是感知机的老师,他会用开关来告诉感知机哪些行为是正确的,哪些是错误的。通过这种方式,系统就能确定每个传感器的输入对答案的影响,并相应地增强或减弱这一影响。随着这个过程的重复进行,感知机就逐渐获得了形状识别的可靠能力。 ==* ——[[《我看见的世界》]]
## 如何找到一组正确的权重?
### 样本学习
感知器的目标是确定输入的图案是否属于图像中的某一类别,这就需要一组正确的权重来判断。但如何找到一组正确的权重?
工程师们再次模仿了人类的学习方式:**通过大量的输入样本进行自动学习**。这包括正面样本和反面样本。如果出现错误,感知器[[algorithm 算法]]会自动调整权重。
这种感知器学习算法的美妙之处在于,如果已经存在一组权重,并且有足够多的样本,它肯定可以自动找到一组合适的权重。
### 递增学习
渐进式学习。在提供了训练集中的每个样本,并且将输出与正确答案进行比较后,感知器会进行递进式的学习。类似于人类的考试抽查。如果答案正确,权重则不发生变化,如果答案错误,权重进行略微调整,如果下次收到同样的输入(考题)时,它会更接近正确答案。这样的好处是,权重会接收所有训练样本的影响,而不仅仅是最后一个。
类比于考试。在考试中,每一题的答案都会即时反馈,帮助学生理解哪些部分掌握得好,哪些部分还需要改进。这与感知器在每次接收输入后调整权重的过程相似,通过逐步调整来优化模型,以应对未来的输入。
## 线性分类器
^a8c3f3
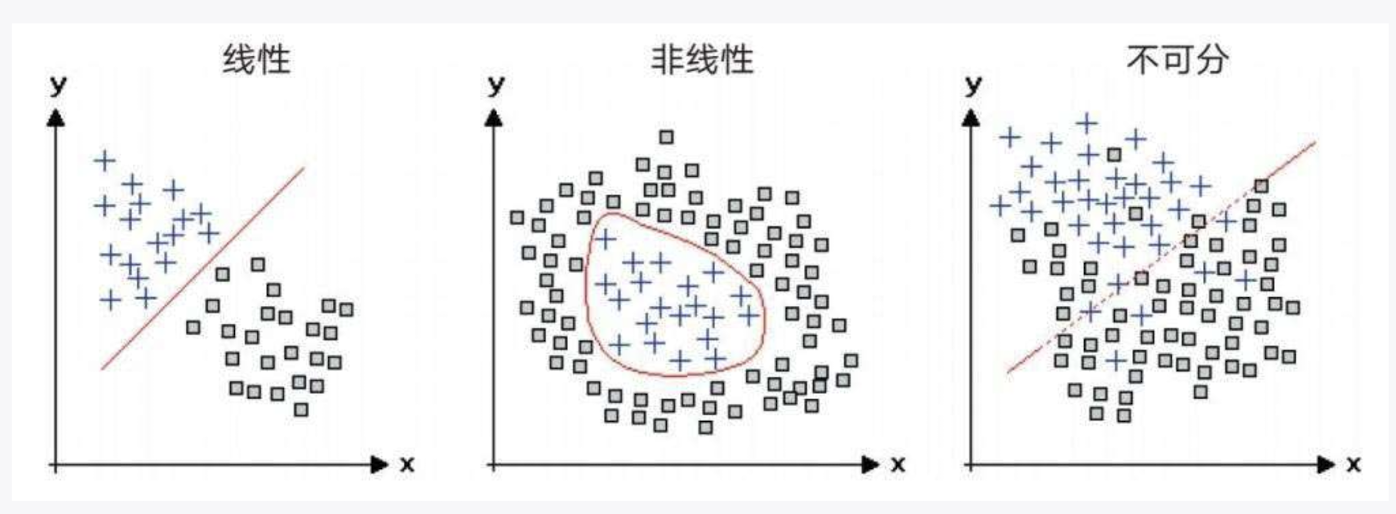
单层感知器是一种线性分量方式,只有 0 和 1 两种状态。只要是遵循线性原则,无论输入空间是二维、三维还是多维的,都可以解决。所以它的本质缺陷是不能处理**线性不可分**问题。比如著名的[[异或 XOR]]问题。
## 类比于[[孩子天生爱学习 神经元构造|神经元细胞]]
- 单个神经元细胞有 2 种状态:活跃,产生电脉冲(1)与不活跃(0);
- 神经元细胞的状态取决于:1)从其它的神经细胞收到的输入信号量;2)突触的强度;
- 当信号量的总值超过阈值,细胞体活跃;未超过则不活跃;
- 电脉冲从神经元细胞体沿着轴突,通过突触传递给其它的神经元。
- 感知器与神经元的对应概念:
- [[weights 权重]]=[[孩子天生爱学习 突触|突触]]:
- 偏置=阈值
- 激活函数=细胞体
## 感知器遭到行业反对
马文·明斯基和西摩尔·帕普特在1969年发表的数学专著《感知器》(Perceptrons)证明了感知器无法解决非线性不可分的问题,所以感知器渐渐被 AI 研究领域遗忘,知道 20 世纪 80 年代,新一代的神经网络研究员才开始重新审视这个问题。
线性不可分问题之一:感知器无法处理[[异或 XOR]]问题。举个例子:当纸板上有两个点时,感知机可以告诉你两个点是否都是黑色,或者是否都是白色,但是不能告诉你“它们是不同的颜色吗?”
# 参考资料
- 《深度学习:智能时代的核心驱动力量》
- [GPT:深度学习感知器学习](https://chatgpt.com/share/0c9f2096-6b0f-488f-a607-6086e35ca5ad)
- [感知器-维基百科](https://readwise.io/reader/shared/01hyet0ysn9ndzdxpvezyw8181)
- [Mark I Perceptron](https://en.wikipedia.org/wiki/Mark_I_Perceptron)