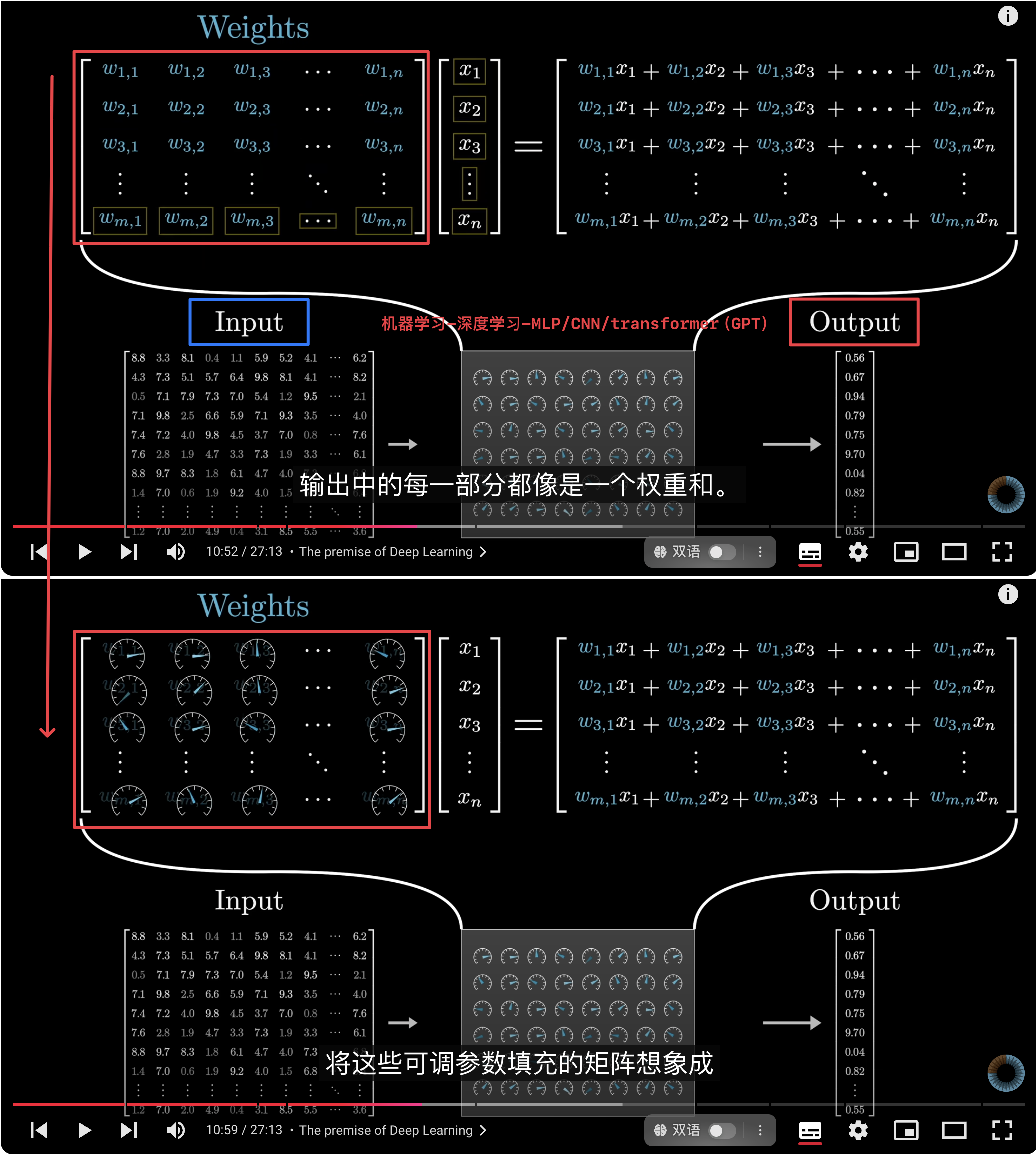
- Objective: 机器学习内部的可调节旋钮,让模型能够自我学习来优化预测性。
- Breadcrumb:
# 概念阐释
参数是大语言**模型**中的可调节旋钮,通过大量的数据(世界知识)和期望输出的学习来调整和微调这些参数,最终获得一个可以准确预测下一个词的[[LLM 大语言模型]]。参数就像是人类的大脑,它决定了模型的行为模式,因此参数是决定大语言模型质量高低的重要因素之一。获得参数的过程也是训练模型过程中成本最高的一步。
## 为什么参数叫做权重?
在深度学习中,参数之所以被称作权重是因为这些**参数**与正在处理的**数据**之间的唯一交互方式是通过权重和weight sum。虽然模型中也会穿插一些非线性函数$f$,但它们并不依赖于这些参数。计算公式为(与[[矩阵向量乘法]]是同一概念):
$ f(w_1x_1+w_2x_2+w_3x_3+...+w_nx_n) $
- $f$: [[activation function 激活函数]] ,激活函数使得模型能够学习到更复杂的模式和特征。如果没有激活函数,整个模型会变成一个线性模型,无法处理非线性问题。
- **[[ReLU]]**(Rectified Linear Unit):输出 $f(x) = \max(0, x)$。
- **[[Sigmoid]]**:输出范围在(0, 1)之间,适用于二分类问题。
- **Tanh**:输出范围在(-1, 1)之间,适用于对称分布的输出。
- $w$: 参数:一开始是随机的,使用[[gradient descent 梯度下降]]来最小化[[Loss function 损失函数]],从而更新参数。
- $x$: 数据
- 结果:一组新的数据,权重在训练过程中用这些数据来优化;
- 如果是训练阶段,这组数据的output 与 target data进行比较,计算损失,[[Loss function 损失函数]]会衡量输出与目标的差距,通过[[Backpropagation 反向传播算法]],损失的梯度会从输出层逐层返回 transformer 模型,以更新参数;这个说明参数之所以叫做权重是因为参数的重要性选择是通过数据来训练的。
- 如果是使用阶段,这组数据将通过[[Softmax]]进行转换,成为下一个词的概率分布。[[GPT的生成过程]]
# 实例
## GPT-3的参数分布
- 权重总数:1750 亿 个
- 矩阵总数:27,938个
- 矩阵类别:8 个
| | 矩阵数 | 权重数 |
| ---------------------- | --- | ---------------------------------------------------------------------------------- |
| [[Embedding]]层:[[词嵌入]] | 1 | `d_embed(D) * n_vocab(V) = 12,288 x 50257 = 617,588,016<br>` |
| Key | | `d_key * d_embed * n_heads * n_layers = 128 * 12,288 * 96 * 96 = 14,495,514,624` |
| Query | | `d_query * d_embed * n_heads * n_layers = 128 * 12,288 * 96 * 96 = 14,495,514,624` |
| Value | | `d_value * d_embed * n_heads * n_layers = 128 * 12,288 * 96 * 96 = 14,495,514,624` |
| Output | | `d_embed * d_query * n_heads * n_layers = 12,288 * 128 * 96 * 96 = 14,495,514,624` |
| Up-projection | | `n_neurons * d_embed * n_layers= 12,288 * 4 * 12288 * 96 = 57,982,058,496` |
| Down-projection | | `d_embed * n_neurons * n_layers= 12288 * 49152 * 96 = 57,982,058,496` |
| [[Unembedding]] | 1 | `n_vocab(V) * d_embed(D) = 12,288 x 50257 = 617,588,016` |
| total | | `175,181,291,520` |
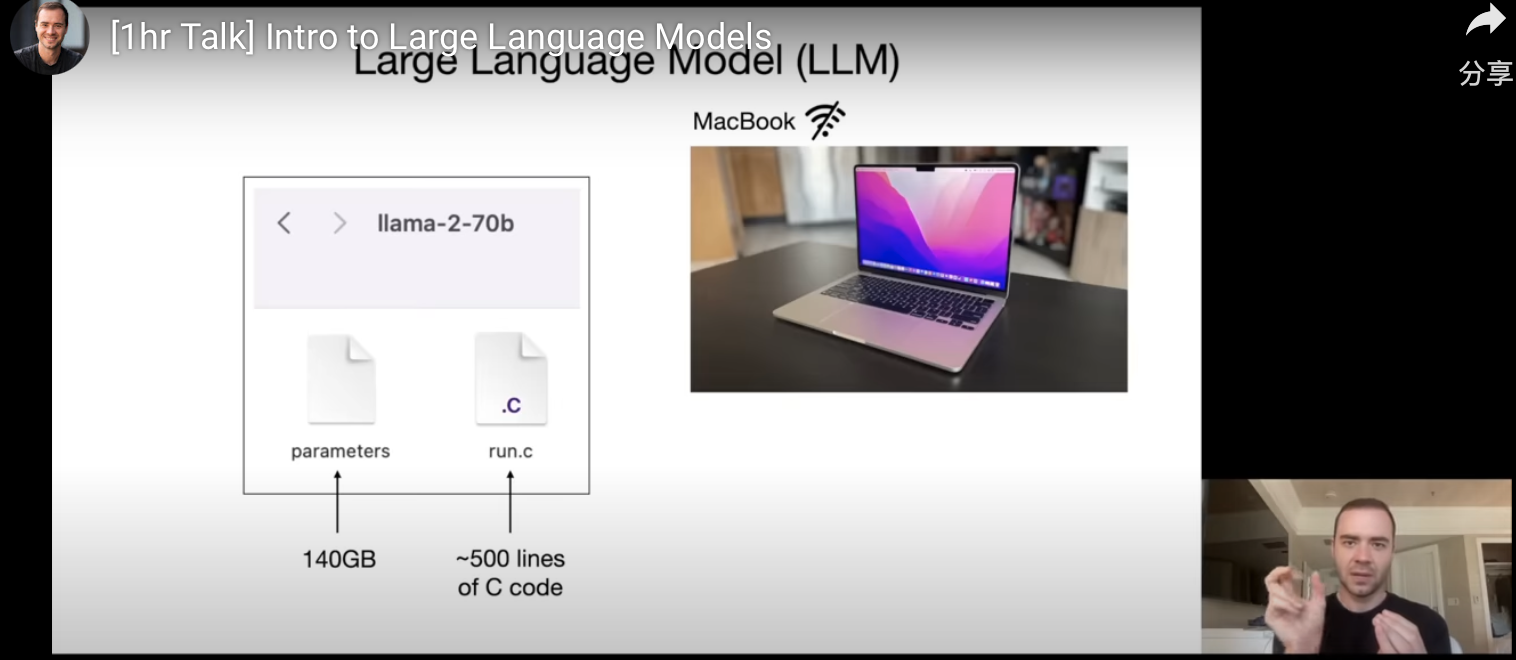
模型的参数是如何获得的?以llama 270b 为例,Llama 有 700 亿参数,文件大小为 140GB参数。
- 首先,从互联网获得数据,Llama 从互联网搜集了 10 兆兆字节的文本。
- 然后,购买 GPU 集群对这些数据进行训练,粗略可以理解为把这 10 兆兆(TB)字节的数据压缩成一个zip 文件,相当于那个 140GB 的参数文件,大概压缩了 100 倍。训练llama 270b大概需要 6000 个 GPU,运行 12 天,花费 200 万美元。
- 700 亿只是一个小模型,GPT3.5 有 1750 亿,GPT4 有万亿参数。训练模型是造价极高的,但是运行模型就相当便宜了。
ChatGPT的神经网络最终由数十亿项的$f[w \cdot x + b]$数学函数组成。人脑有 150 万亿个突触联结,GPT-4 有万亿的参数(权重)。
# 相关内容
## 类比数学模型
最容易理解参数与模型的例子,例如[[Liner Regression 线性回归]],通过过往数据模拟出一个大概的线性走向,在通过调节$x,y$轴的值来微调这个参数,让公式更加拟合真实的情况,最终可以用于预测未来的结果。
## 权重相当于人类大脑的突触
受[[认知神经科学 cognitive neuroscience]]启发,[[孩子天生爱学习 突触|突触]]是神经元之间的连接点,突触将沿着轴突传递过来的电信号转化为化学信号传递给下一个神经元的树突。突触的强度可以**决定**(传递效果强或弱)信号传递的效果。这类似于权重在神经网络中的决策权。[[孩子天生爱学习 神经元构造|神经元]] = [[人工神经元 neuron]]
| | 突触 | 权重 |
| --- | -------------------------------- | --------------------------------------------------------------- |
| | 150 万亿突触联结 | GPT-3.5:1750 亿;GPT-4 万亿; |
| | 通过每天思考,内化、实践、反馈来修剪突触冗余,形成低密度突触联结 | 通过样本自主学习和递增学习得到一组正确的权重 |
| | 密度低,传输速度快,传输信号强 | 权重影响模型的准确率,高权重影响力大,一组正确的权重获得一个能够解决问题的模型。否则会[[overfitting 过度拟合]] |
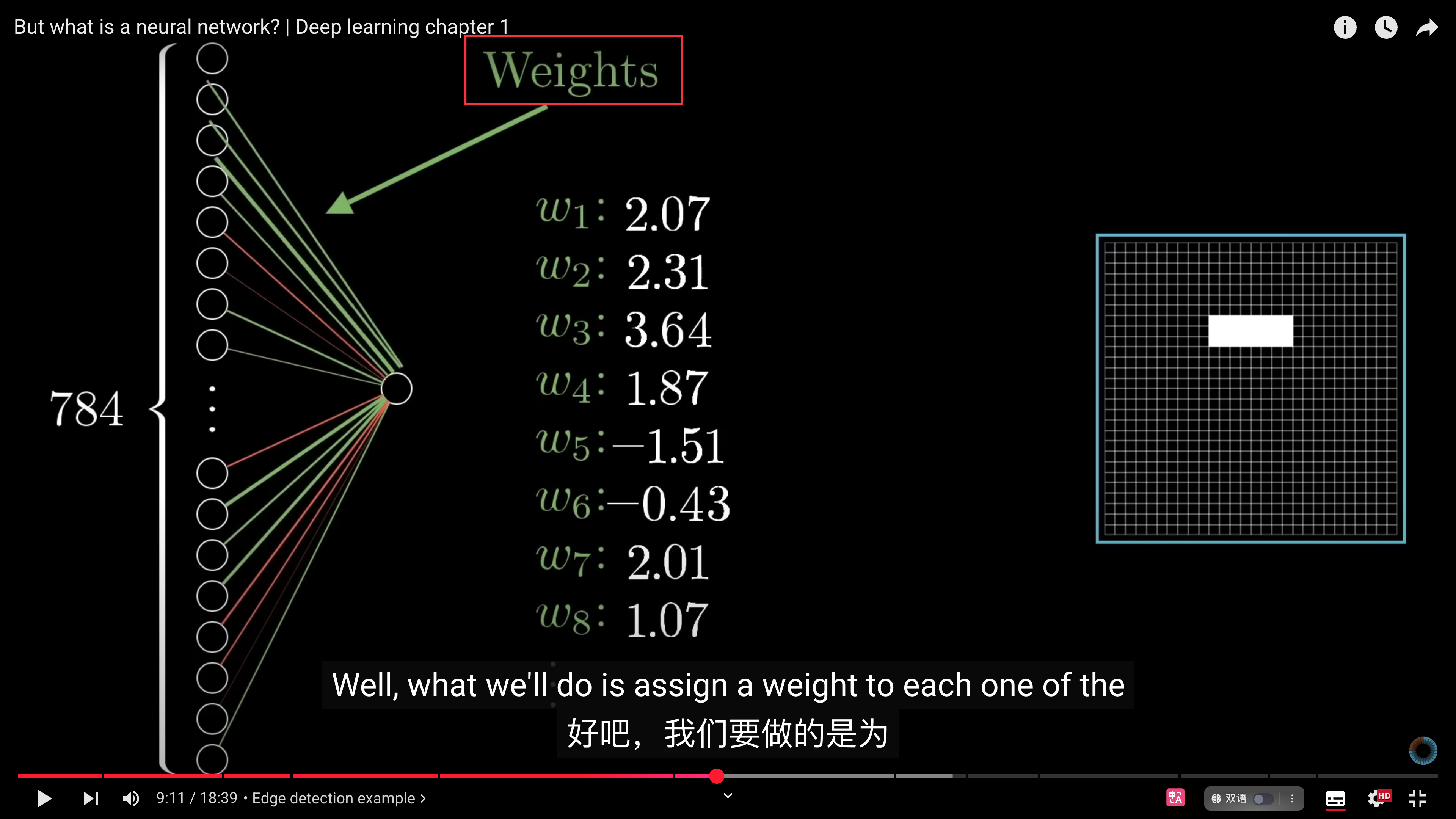
## 权重在神经网络训练过程中的作用
- 神经网络的训练,如何起效?
- 如果神经网络能够成功复现给定的样例就说明起效了。
- 如何复现?
- **找到能够复现样例的权重**
- 然后依靠神经网络在这些样例之间进行合理的泛化或插值
- **泛化Generalization**:模型对新的,未见过的数据的处理能力。模型的泛化能力越强,表现越好,即能够准确预测或分类未经训练的数据。
- **插值Interpolation**:根据已知的数据点预测未知的数据点。强调在已知数据的基础上做出准确预测的能力。(**外插值Extrapolation**:在已知数据范围外进行预测。)
- 如何找到权重?
- 通过大量的学习资料,1万、10万、1亿的样例的训练结果会完全不同
- 这里可以类比于人类的学习,通过大量的练习可以理解和掌握新的知识和技能
- 如何调整权重?
- 在每个阶段看下离我们想要的结果有多远,然后朝更近的方向重新调整
- 离目标有多远如何计算?
- 通过[[Loss function 损失函数]]或者叫成本函数:计算的值与真实函数之间的差的平方和,不断地减小损失函数直到模型复现出我们想要的结果。
## 权重让复杂问题更容易解决
> “深度学习”在2012年左右的重大突破与如下发现有关:与权重相对较少时相比,在涉及许多权重时,进行最小化(至少近似)可能会更容易。换句话说,有时候用神经网络解决复杂问题比解决简单问题更容易—这似乎有些违反直觉。大致原因在于,当有很多“权重变量”时,高维空间中有“很多不同的方向”可以引导我们到达最小值;而当变量较少时,很容易陷入局部最小值的“山湖”,无法找到“出去的方向”。
# 参考资料
- [[Intro to LLM]]
- 《这就是ChatGPT》p27-28
- 《这就是ChatGPT》机器学习和神经网络的训练 p35-41
- [GPT:深度学习感知器学习](https://chatgpt.com/share/0c9f2096-6b0f-488f-a607-6086e35ca5ad)
- [3B1B-Chapter 5, Deep Learning - How large language models work, a visual intro to transformers](obsidian://open?vault=Harry%E7%9A%84%E6%91%98%E5%BD%95%E7%B4%A0%E6%9D%90%E5%BA%93&file=%E7%9F%A5%E8%AF%86%E8%A7%86%E9%A2%91%2F3B1B-Chapter%205%2C%20Deep%20Learning%20-%20How%20large%20language%20models%20work%2C%20a%20visual%20intro%20to%20transformers)