- Objective:
- Breadcrumb:
# 概念阐释
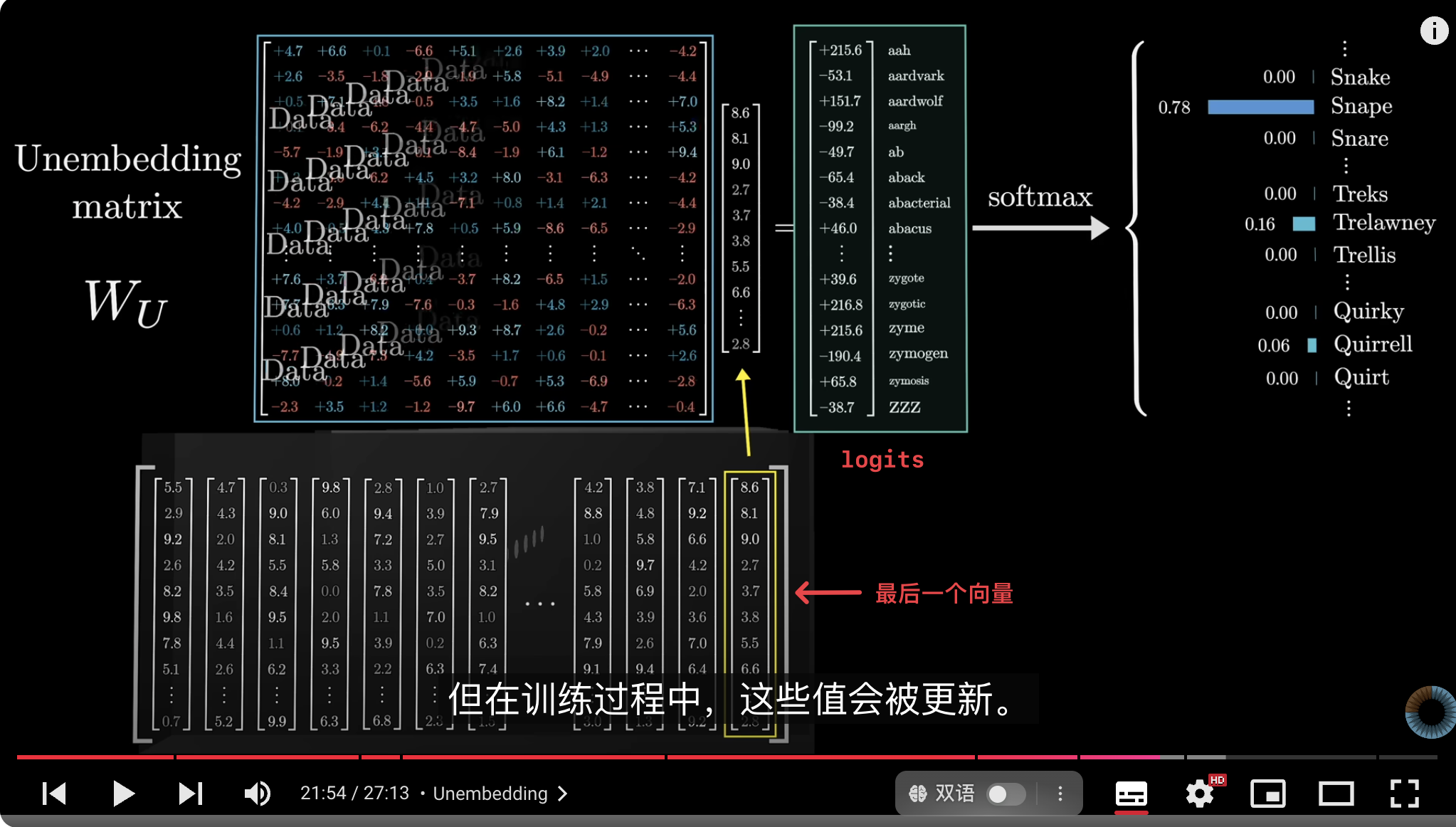
**logits** 是 [[Transformer]]中最后一个隐藏层的输出**向量**与 **[[Unembedding]] Matrix** 相乘得到的结果向量。
## 计算过程
- 在 Transformer 模型的最后一层,模型生成了一个隐藏状态向量 **$h$**,它表示模型对输入上下文的综合理解。
- 将这个隐藏向量映射到词汇表上所有词的可能性,我们会做以下操作:
- **Unembedding Matrix ,$W$**:矩阵类似于[[Embedding]]嵌入矩阵的逆,用于将隐藏向量从模型内部空间映射回到词汇表空间。
- **计算 logits, $z$**:将隐藏状态向量 $h$ 与 $W$ 相乘,得到一个向量$z$:
- $z=h⋅W$
- **Softmax 转换**:这些 logits 经过 [[Softmax]] 转换后,得到词汇表中每个词的概率分布。
# 实例
# 相关内容
# 参考资料
- [3B1B-Chapter 5, Deep Learning - How large language models work, a visual intro to transformers](obsidian://open?vault=Harry%E7%9A%84%E6%91%98%E5%BD%95%E7%B4%A0%E6%9D%90%E5%BA%93&file=%E7%9F%A5%E8%AF%86%E8%A7%86%E9%A2%91%2F3B1B-Chapter%205%2C%20Deep%20Learning%20-%20How%20large%20language%20models%20work%2C%20a%20visual%20intro%20to%20transformers)
- [GPT-softmax/temperature/logits](https://chatgpt.com/share/672824b4-50c4-8002-91f6-b8fd4cd6e130)