- Objective:
- Breadcrumb:
# 概念阐释
大语言模型的最终的目标是产生一个概率分布,预测下一个可能出现的 Token。大模型的最后一步unembedding具体步骤包括:
1. 将上下文中的最后一个向量映射到词汇表中,通过权重和 weight sum算出词汇表中的每个 token 对应的一个值;
2. 通过[[Softmax]]函数,得到所有词汇表token的概率分布,这些概率之和为 1,模型一般会选择概率最高的 token 作为下一个生成的 token。
## Unembedding matrix
- 这个矩阵被称为 unembedding matrix ($W_U$)。
- 参数的初始值是随机的,这些值会随着数据的输入而更新。
- 权重数量:unembedding 矩阵为词汇表($V$)中的每个单词都分配了一行,每一行包含与嵌入维度相同数量的元素$D$,这与嵌入([[Embedding]])矩阵非常相似,只不过是把顺序倒过来了。例如:GPT-3,V=50257,D=12288,$W_U = V*D ≈ 6.17$ 亿权重
# 实例
# 相关内容
## 为什么只用最后一个向量?
这是因为在训练过程中,如果我们利用最终层的每一个向量来预测其后可能出现的内容,被证明是更高效的方法。
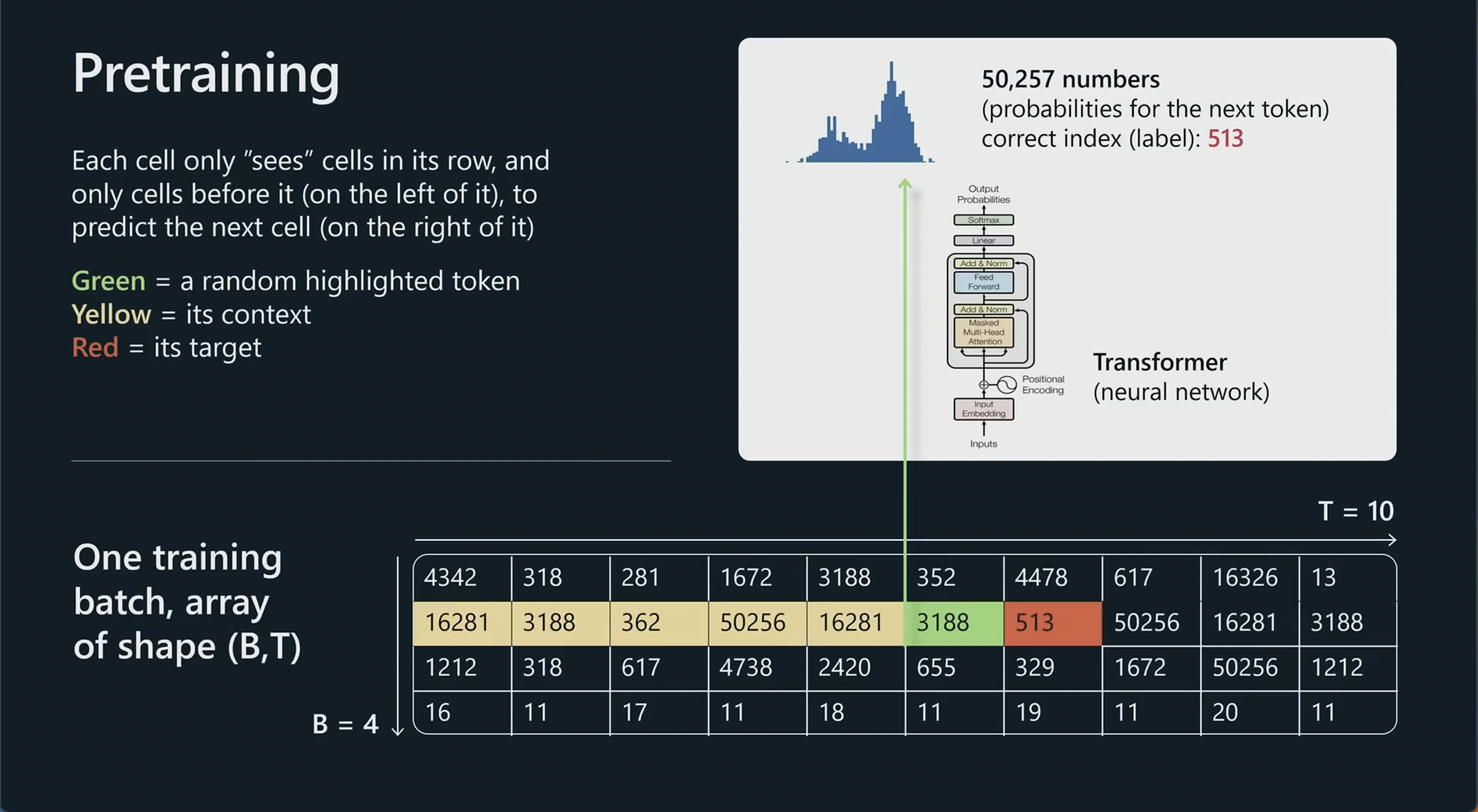
## 预训练阶段
[[GPT 训练过程(archive)]]的预训练阶段的主要目的是计算模型的预测误差,从而对模型的[[parameters 参数]]进行优化。
1. **生成预测词**:Transformer 模型会尝试预测目标词(即掩盖的词或下一个词,target),并通过 Softmax 将输出向量转化为词汇表上每个词的概率分布。
2. **计算预测误差**:通过 Softmax 生成的概率分布,模型可以计算出它预测的目标词的概率,并将其与实际的目标词的概率(通常是 1,对应于目标词的标签)进行比较。这样,可以得到预测误差或损失值(通常使用交叉熵损失)。
3. **指导参数更新**:基于预测误差,模型使用[[Backpropagation 反向传播算法]]更新参数,以便在未来的预测中提高对目标词的预测准确性。
## 实际使用(推理)阶段
1. **输入数据**:例如在 ChatGPT 页面上键入的指令会被模型通过嵌入层(Embedding Layer)转化为词向量,然后传递到 Transformer 的自注意力层和前馈网络中进行一系列计算。
2. **通过 Unembedding 层生成词分布**:经过模型的编码和解码后,输出结果会通过 Unembedding 层,即将解码的最后一个输出向量与词汇表的权重矩阵相乘([[矩阵向量乘法]])。这一矩阵乘积生成了词汇表上每个词的分数,即[[logits]]。
3. **Softmax 计算概率分布**:这些分数通过 [[Softmax]] 转换为概率分布,表示词汇表中每个词的可能性。概率最大的词就是模型认为最有可能的下一个词。
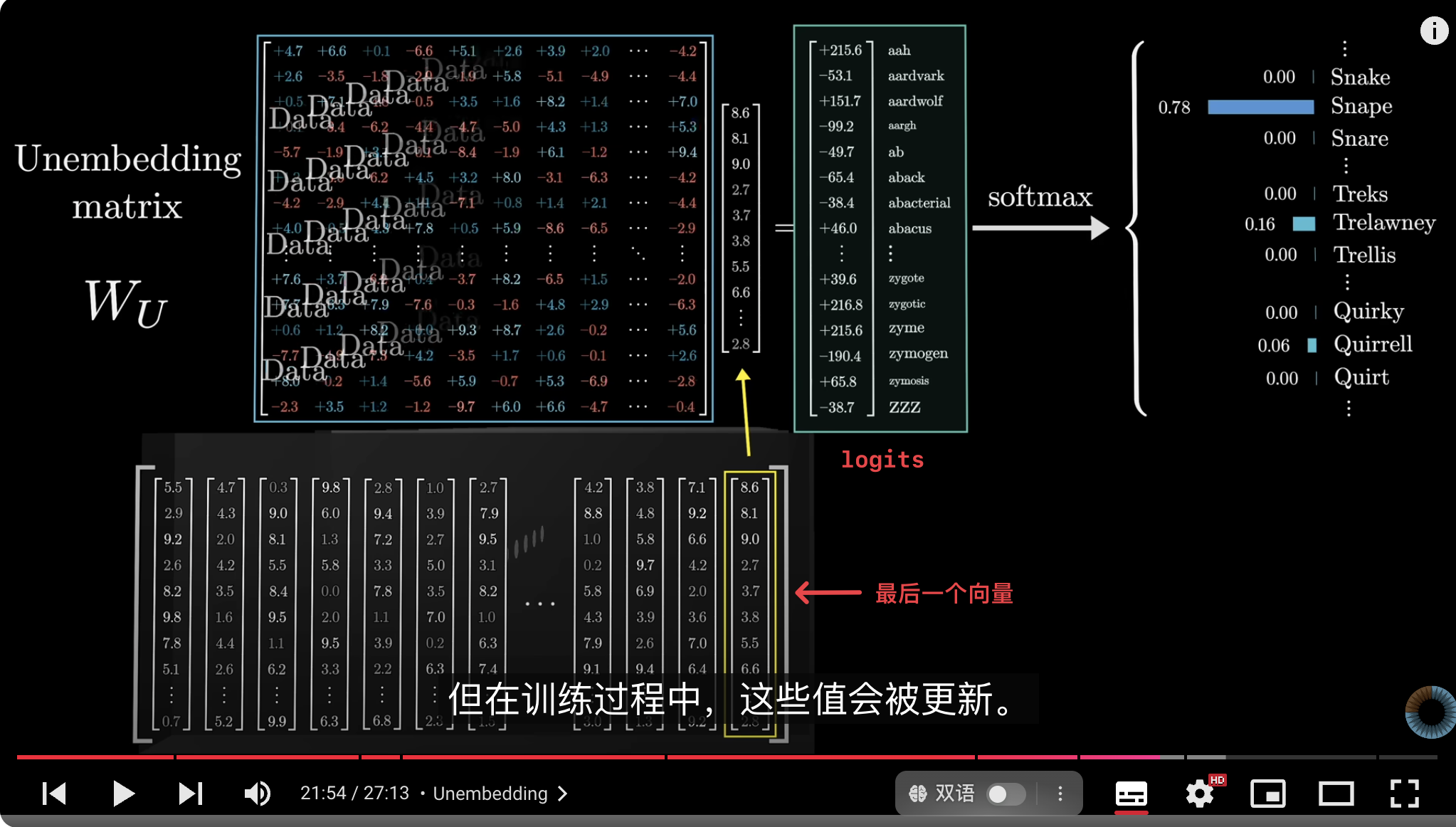
举例来说,一段文本的最后一个词是 **“教授”**,上下文中包含了“**哈利·波特**”等词语,紧接着出现的是“**最不喜欢的老师**”,那么,一个经过良好训练并对哈利·波特世界有所了解的网络,会很可能给“**斯内普**”这个词赋予一个较高的权重。
# 参考资料
- [3B1B-Chapter 5, Deep Learning - How large language models work, a visual intro to transformers](obsidian://open?vault=Harry%E7%9A%84%E6%91%98%E5%BD%95%E7%B4%A0%E6%9D%90%E5%BA%93&file=%E7%9F%A5%E8%AF%86%E8%A7%86%E9%A2%91%2F3B1B-Chapter%205%2C%20Deep%20Learning%20-%20How%20large%20language%20models%20work%2C%20a%20visual%20intro%20to%20transformers)
- [GPT-softmax/temperature/logits](https://chatgpt.com/share/672824b4-50c4-8002-91f6-b8fd4cd6e130)