- Objective: ChatGPT的内部原理
- Breadcrumb:
# 概念阐释
- transformer 是一种特殊的[[Deep Learning 深度学习|深度学习]]神经网络架构,在2017 年由Google Brain 团队的 Vaswani 等人在论文"attention is all your need"中提出,起初是为了翻译语言。而现在是用于处理文本的语音、图片、视频,甚至是自动驾驶和蛋白质[[生成式 AI]]的主流神经网络架构,由于这个特征也被称为“大一统 AI 架构”。2020 年之后,基于 transformer 架构的[[生成式 AI]]开启了 AI 盛夏;
- 这篇论文的主要贡献在于提出了注意力机制,**不再依赖于传统的循环神经网络(RNN)** 或 **长短时记忆网络(LSTM)**[^1]。
- **并行处理序列**:解决计算的处理速度
- 在处理序列数据时(比如文本),早期的模型如[[RNN 循环神经网络]]和[[LSTM 长短期记忆]]网络有一个问题:它们处理序列时是**顺序的**,意味着每个词的生成都要依赖前一个词的结果。比如,你需要先知道“今天”才能生成“天气”,然后才能生成“很好”。这样一来,计算过程非常慢,且难以捕捉到很远距离(长时间)的依赖关系。
- 而Transformer则通过一种**并行化**的方式来解决这个问题,不需要一步一步地按顺序生成,能够同时处理整个序列,**提高效率**,并且能够更好地理解长距离的关系。
- **[[自注意力机制]]**: Transformer的核心思想,通过上下文语境来理解单个 token
- transformer 本质上就是一个庞大的[[语义空间]]。
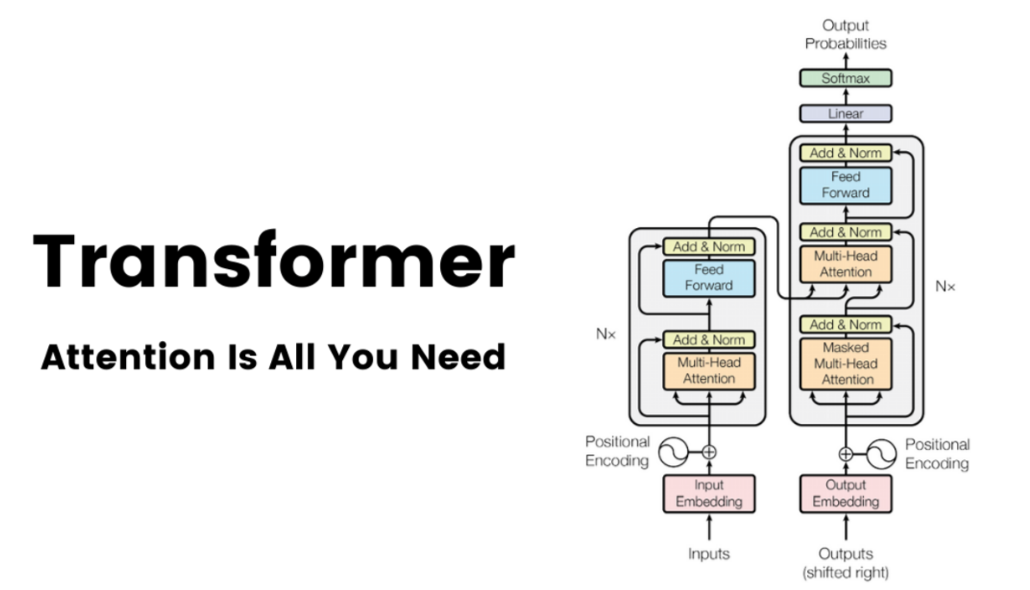
# 实例
## transformet 的应用领域
- text to text
- [[GPT]]
- video to text
- whisper
- text to video
- [[sora]]
- text to image
- DALL·E
- 蛋白质结构
- [[AlphaFold2]]
- 自动驾驶
- [[FSD]]
# 相关内容
- [[how transformer work]] #todo
## Transformer 的核心组件
- [[LLM Visualization nano-gpt]]
- [[tokenization]]
- [[Embedding]]
- transformer
- layer norm
- Embedding矩阵进入 transformer 模型,第一步回来到 **归一化矩阵 normalization** 。
- 归一化是非常重要的一步,因为它能够改进模型在训练时的稳定性。
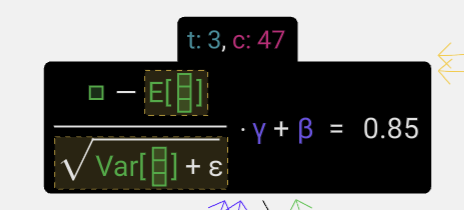
- **目标**:使列中的平均值等于 0,标准差等于 1。为了实现这个目标,我们需要先计算出列的平均值(μ)和标准差(σ),然后用每个数值减去平均值,再除以标准差。
- 求归一化值:
- 我们在这里使用的符号是 $E[x]$ 表示平均值,$Var[x]$ 表示方差(长度为 C 的列的方差)。方差简单来说就是标准差的平方。ε(ε = 1×10⁻⁵)这个项是用来防止除以零出现的问题。我们在聚合层中计算并存储这些值,因为我们要将它们应用到该列的所有数值上。最后,当我们得到归一化后的数值后,会将该列的每个元素乘以一个可学习的权重(γ),然后再加上一个偏置值(β),最终得到归一化后的结果。
- 
- 批量操作:我们对每一列嵌入执行归一化操作,结果得到归一化输入嵌入normalized input embedding,传入下一层。
- **[[自注意力机制]]
- layer norm
- **[[MLP 多层感知器]]**::feed forward,相当于人类的[[认知心理学 长时记忆]],后皮质
- layer norm
- linear
- softmax
## 人类的理解vsAI智能体的理解
- [[罗塞塔石牌 rosetta stone]]:
- **基于规则的理解**,人类大脑最擅长的是从复杂的信息中提取模式和规律;
- 例如:当我们在做翻译的时候,我们会先去寻找规律,总结语法规则,制作出一本翻译手册,然后基于语法规则再做语言映射。
- [[transformer]](说的其实就是[[语义空间]]):**通过高维空间的几何关系进行理解** ^3e83c5
- 在 transformer 中,人类语言的词([[tokenization|token]])会被转换为一系列的数字向量;
- “这些向量会被嵌入到一个高维向量空间(语义空间)中,通过高维向量中的数千个**维度特征**来识别和关联人类语言中蕴含的语法和语义规律(GPT-4 3072个维度)。”通过不同于人类的理解方式,似乎 AI 更能够捕捉到输入信息中的复杂性和细微差别(nuance),从而达到人类无法学习到的程度;—— [4.2 生成式AI对人类学习的启示](https://readwise.io/reader/shared/01jew2fq0hyg572cnk85wsypx8)
- 如果把这个高维空间进行二维化或者三维化就会发现,意思相近的词会离得很“近”。
- [[《这就是 ChatGPT》]]的例子:cranberry、blueberry 、grape 等浆果自动聚成一团,apple、banana、melon 等肉果也自动聚成一团,cat、dog、bear 等动物又自动聚成一团;
- 词与词之间的关系:king-queen=man-woman;
- 跨语言的:不论何种语言,也神奇地在高维空间中聚成一团!“我是一名学生”,“i am a student”,“je suis etudiant”……不同语言等翻译;
- **阅读上下文**:==“transformer 架构会关注到这种高维向量的上下文关系,通过动态的、受上下文影响的嵌入向量来更好地理解文本中的含义。GPT 每生成下一个词都取决于之前的词,基于前面的内容来预测下一个词。”== —— [4.2 生成式AI对人类学习的启示](https://readwise.io/reader/shared/01jew2fq0hyg572cnk85wsypx8)
- **翻译学不存在了**:翻译是 transformer 出发的地方,transformer 不是用人类规则导向的方式进行翻译,而是在高维空间中**以人类无法理解的方式找到了人类语言中的规律。**
## 大语言模型本质上是知识大模型
- 像 GPT 这样的大语言模型以人类无法理解的方式在高维空间中找到了人类语言的规律,形成了对人类知识的“深刻理解”,所以它才能够进行翻译、写作、变成、图片转换、音频转换等一系列任务。
- transformer 的理解方式揭示了“理解”上的一个重要方面:**关联**,在高维空间中向量之间的位置关系;
- 这种关系在人类的理解中是知识砖块在语义和语境之间的关联。
- 例如:羽毛,在自然科学中的理解,和在《哈利波特》中的理解会有差异;类似的还有 model;
- 从大模型引发的思考:人类的语言是人类知识的载体(对于其他生物来说,语言是沟通的工具):
- 大模型将人类的知识作为原生数据来学习,然后将从文本中提取的模式和规律压缩到神经网络(类似于人类的大脑)的万亿参数中,所以说[[parameters 参数|参数]]决定了模型的==行为和模式==。
# 参考资料
- [Attention Is All You Need论文](https://arxiv.org/pdf/1706.03762.pdf)
- [日报461 变形金刚6周年](https://www.huxiu.com/article/1678642.html)
- 《这就是ChatGPT》ChatGPT的内部原理 p64
- [attention is all you need - 维基百科](https://en.wikipedia.org/wiki/Attention_Is_All_You_Need)
- [transformer - 维基百科](https://en.wikipedia.org/wiki/Transformer_(deep_learning_architecture))
- [3.2 什么是编码?](https://readwise.io/reader/shared/01jdtexe0qt0f70tmv48wkgdj3)
[^1]: RNN循环神经网络:强调上下文顺序、前后文逻辑关系,但无法实现并行计算,所以速度十分缓慢,难以扩大规模。LSTM:长短期记忆模型,在Transformer提出之前,广泛用于自然语言处理,但问题是对输入内容的前后顺序敏感,无法实现大规模的并行计算。