- Objective: 机器、大脑的奖励学习
- Breadcrumb:
# 概念阐释
时序差分学习(Temporal difference learning,TD learning)是强化学习中,在最终结果出现之前预测未来奖励的方法。
最大化折扣奖励
$ R(t) = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \ldots $
- $r_{t+1}$: 在时间 t+1 时的奖励;
- $R(t)$: 多个时刻的累计奖励之和;
- 0<$\gamma
lt;1:[[认知神经科学 折现因子|折扣系数]],接近于 1 时关注未来奖励,接近于 0 时关注当下奖励;
# 实例
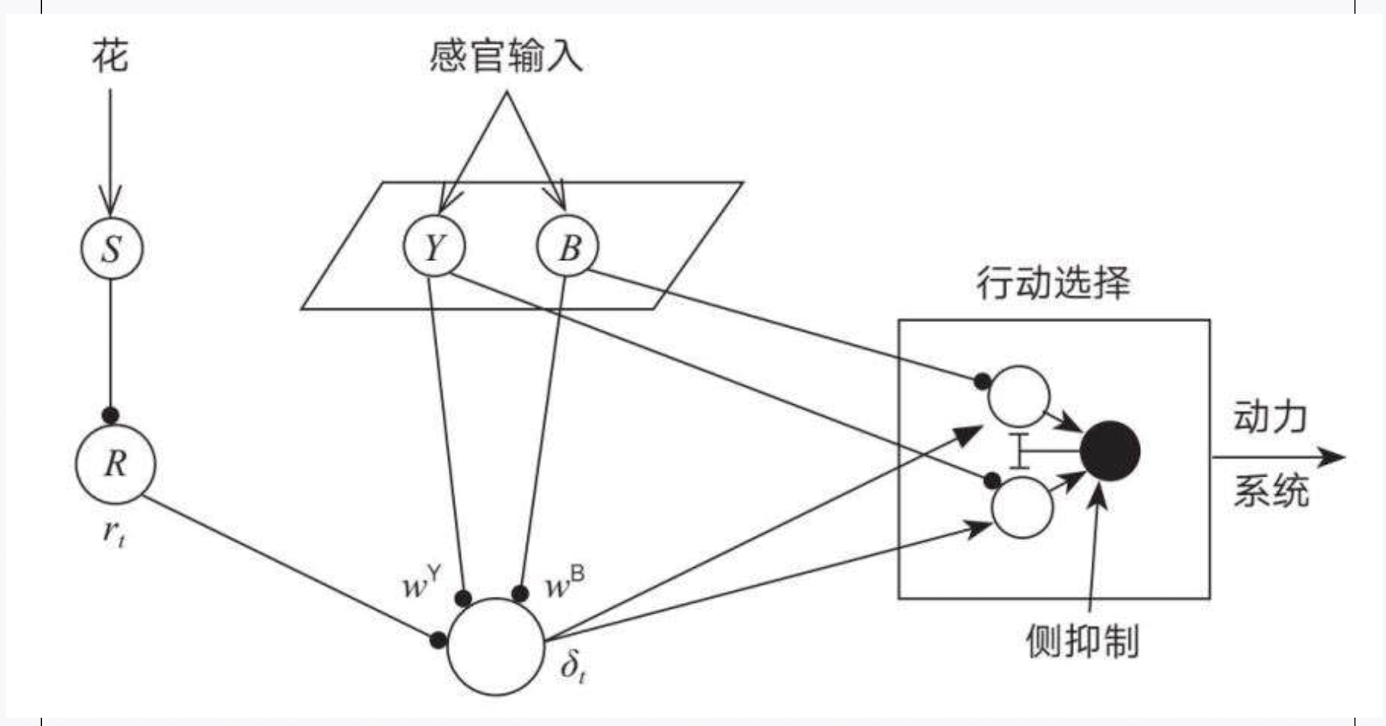
蜜蜂的奖励模型:
**图片中的角色**
1. 花朵:在图片的左边,有一朵花,小蜜想知道从这朵花能得到多少花蜜。
2. 感官输入:当小蜜飞到花丛中,她用眼睛和鼻子(感官输入)来看看花的颜色和闻闻花的香味。
3. 黄色感官(Y) 和 蓝色感官(B):小蜜的眼睛能看到黄色的花和蓝色的花,所以她的系统有两个部分,一个专门看黄色花,一个专门看蓝色花。
4. 奖励(R):当小蜜采蜜时,她会知道这朵花给了她多少花蜜,这就是她的奖励。
**图片中的过程**
1. **感官输入**:小蜜飞到花丛中,用眼睛和鼻子感知到花的颜色和香味。假设她看到一朵黄色的花 ( s(t) )。
2. **预测奖励**:小蜜的系统会根据她之前学到的经验(像是之前看到黄色花得到的花蜜)来预测这次她会得到多少花蜜。这个预测由一个叫 ( P ) 的神经元来计算,公式是:
$ P_t(s) = w^Y \cdot s_Y + w^B \cdot s_B $
这里,( $w^Y$ ) 和 ( $w^B$ ) 是系统根据黄色花和蓝色花学到的经验(权重)。
3. **实际奖励**:当小蜜采蜜后,她得到一个**实际的奖励** $r_t$ (比如这次她得到的花蜜数量)。
4. **预测误差**:然后,小蜜的系统会计算一个叫 $\delta_t$ 的数字,这个数字告诉她这次的**实际奖励和之前的预测有多大的差别**。公式是:
$\delta_t = r_t + \gamma P_t(s_t) - P_t(s_{t-1})$
这里, $\gamma$ [[认知神经科学 折现因子|折现因子]]是一个用来衡量未来奖励重要性的数字。
5. **调整经验**:如果这次小蜜得到的奖励比她预期的多,那么系统会增加对这朵花的信任(权重增加)。如果奖励比预期的少,那么系统会减少对这朵花的信任(权重减少)。权重的调整公式是:
$\Delta w_t = \alpha \delta_t s_{t-1} $
这里,$\alpha$ 是**学习速率**,表示小蜜学得有多快。
总结
通过不断地飞到不同的花朵,感知颜色和香味,得到花蜜的奖励,小蜜的系统会越来越聪明,能更准确地预测哪朵花能给她最多的花蜜,从而帮助她做出更好的选择。
# 相关内容
## 大脑的奖励机制
[[多巴胺]]回路与奖励学习有关,但人们始终不清楚传递到前额叶的信号是什么。直到 20 世纪 90 年代发现,多巴胺神经元可以实现时间差分学习。
# 参考资料
- [时序差分学习-维基百科](https://zh.wikipedia.org/wiki/时序差分学习)
- 《深度学习》谢诺夫斯基 10