- Objective:
- Breadcrumb:
# 概念阐释
在[[Transformer]]架构中,softmax 有两个主要用途:
1. 在自注意力[[Attention]]中:
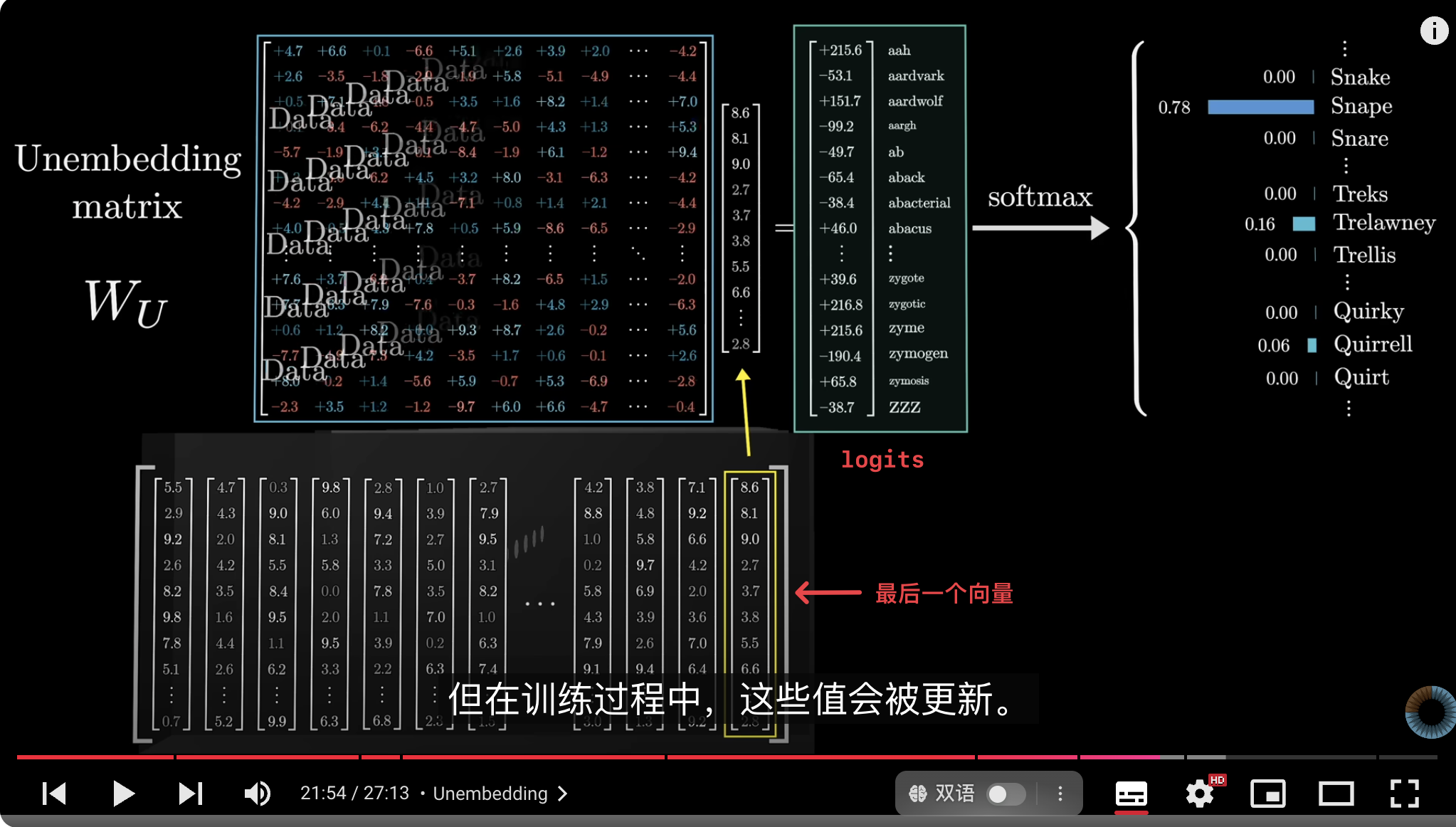
2. 在输出层中[[Unembedding]]: 在 Transformer 的输出层中,Softmax函数用来将模型的输出转化为一个 0-1 之间的概率分布,最终获得**词汇表**中每一个词的概率,其中下一个可能出现的词会非常接近于 1,最小值会非常接近于 0。
## 计算过程
Softmax 函数的计算过程是先将权重与数据的矩阵乘法结果转换为正数,然后取得正数的和,再用向量中的每个数除以总和,最终得到一组总和为 1的列表。
给定一组输入值 $z_1, z_2, \dots, z_n$(例如一组分数),Softmax 的计算步骤如下:
1. **指数运算**:首先,将每个输入值 $z_i$进行指数运算,转换成正数:
$
e^{z_i}
$
这样做是为了将所有数值放大到**正数**范围内,因为指数函数总是大于 0。
2. **计算总和**:对所有指数结果求和,得到**分母**,这个分母用来归一化各个指数值:
$
\text{Sum} = \sum_{j=1}^n e^{z_j}
$
3. **归一化计算**:然后将每个指数结果除以这个总和,得到最终的 Softmax 输出:
$
\text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^n e^{z_j}}
$
这样,所有输出值的和为 1,形成一个概率分布。
# 实例
假设输入是 $z = [2.0, 1.0, 0.1]$:
1. 先进行指数运算:
$
e^{2.0} \approx 7.39, \quad e^{1.0} \approx 2.72, \quad e^{0.1} \approx 1.11
$
2. 求和:
$
\text{Sum} = 7.39 + 2.72 + 1.11 = 11.22
$
3. 归一化得到 Softmax 输出:
$
\text{Softmax}(2.0) = \frac{7.39}{11.22} \approx 0.66, \quad \text{Softmax}(1.0) = \frac{2.72}{11.22} \approx 0.24, \quad \text{Softmax}(0.1) = \frac{1.11}{11.22} \approx 0.10
$
最终的 Softmax 输出为一个概率分布 $[0.66, 0.24, 0.10]$,其中所有值相加等于 1。这种方法帮助模型在输出层时确定不同类别或词的概率。
# 相关内容
在生成模型中,可以在最终的概率分布中添加一个[[Temperature 超参数]],用于控制输出结果的“不确定性”或多样性。通过调整 Temperature 值,可以让模型生成的结果更加随机或更加确定。
# 参考资料
- [3B1B-Chapter 5, Deep Learning - How large language models work, a visual intro to transformers](obsidian://open?vault=Harry%E7%9A%84%E6%91%98%E5%BD%95%E7%B4%A0%E6%9D%90%E5%BA%93&file=%E7%9F%A5%E8%AF%86%E8%A7%86%E9%A2%91%2F3B1B-Chapter%205%2C%20Deep%20Learning%20-%20How%20large%20language%20models%20work%2C%20a%20visual%20intro%20to%20transformers)
- [GPT-softmax/temperature/logits](https://chatgpt.com/share/672824b4-50c4-8002-91f6-b8fd4cd6e130)