- # why
- turn base model(internet document simulator) into assistant;将一个[[LLM 预训练]]的基础模型,一个网络数据模拟器变成一个可以用于回答世界问题的理想助理,即模型模仿人类的响应方式。
- # what
- 监督微调(Supervised Fine-Tuning, SFT),通常是指人类标注员human labelers 给模型提供大量的问题和对应的标准答案,经过预训练的模型在这部分小数据集上继续训练,最终得到一个理想的回应助理。
- **本质上**与预训练阶段没有区别,只是将预训练用的全互联网的大量数据换成了人类标注员提供的小数据量。
- **特征**
- 由人类标注员撰写的成败上千份 prompt, response
- 模型的任务仍然是:预测下一个词
- 1-100 块 GPU,几天的训练时间
- 可以发布的模型
- **虽然标注员不可能把所有的问题和未来的问题都考虑到,但正是因为 LLM 的自主学习能力,它可以内化你的回答方式并进行模拟➕它具备全人类知识的大型知识库。**
- # how
- **如何训练**
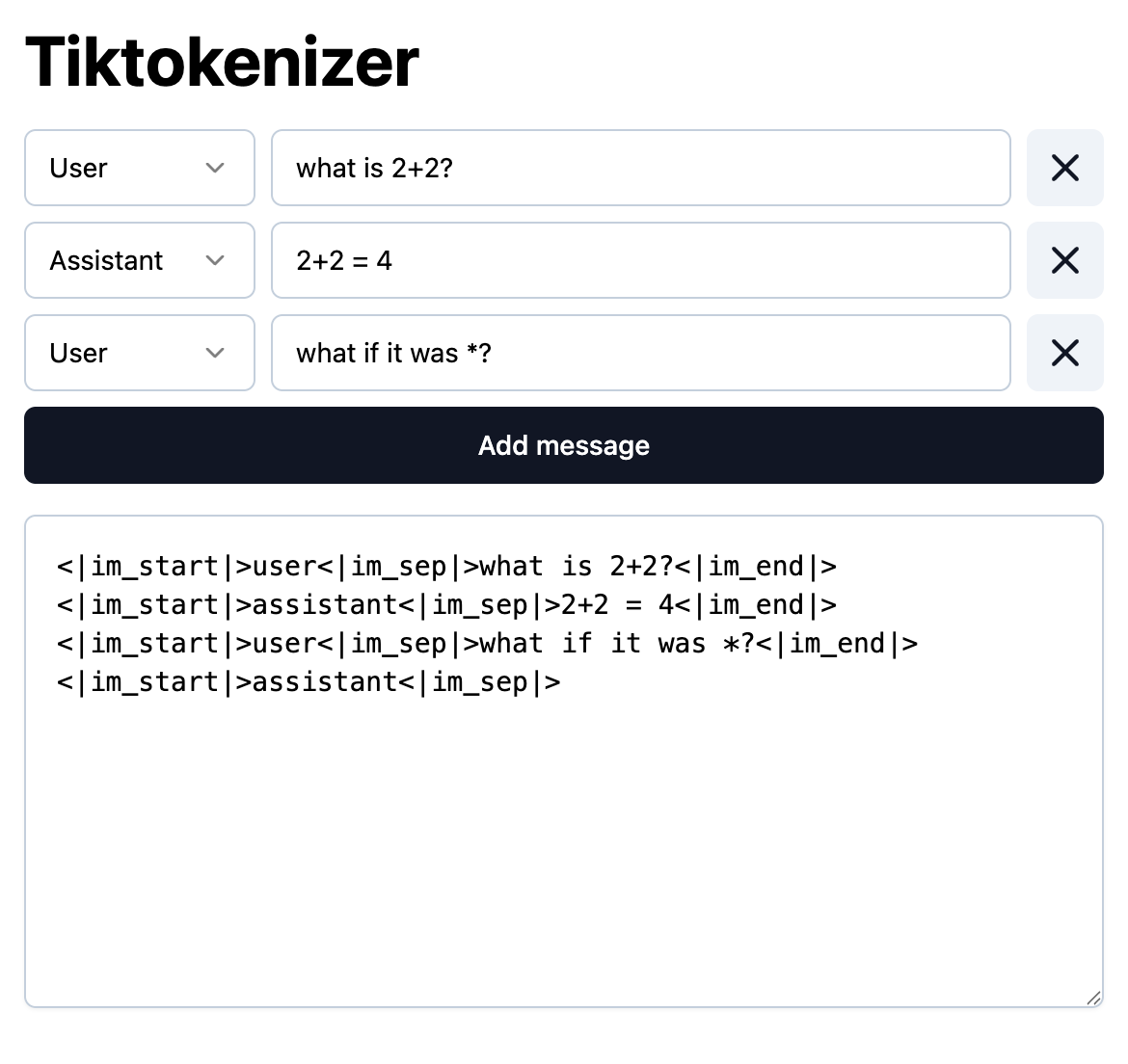
- 在 LLM 中,一切都是词元化的,所以第一步要将人类撰写的 Q&A 转换成 token。但如何让模型知道这是对话而不只是互联网上的 raw text?
- 通过创建一种架构 conversation protocol,这有点像[[TCPIP]] packet,专门用来分割名字、内容、结束,并且这些 token 是从未在预训练阶段出现过的。
- 
- **推理阶段 inference**
- 当用户在使用时,服务器端有点像这样。最后停留在`<|im_start|assistant<|im_sep|>`,模型会给出下一个词的预测。每次的生成内容不一定是人类标注员写的那版,可能都不太一样。
- 
- **人类交互数据的最初想法**
- 这个方法最早出现在[[InstructGPT]](*[Training language models to follow instructions with human feedback](https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf)2022*)论文中。论文中提到可以通过提供人类对话数据集的方式对 LLM 进行微调。
- 
- 这些人类标注员都经过专业的训练,保证提供的信息是 helpful,truthful,harmless的。
- **open 的 conversation dataset**
- 虽然 OpenAI 没有公布他们的训练方式,但是人们试图模仿 OpenAI 的训练方式。(*[huggingface openassistant dataset](https://huggingface.co/datasets/OpenAssistant/oasst1/viewer?views%5B%5D=train)*)
- **LLM 提供数据,人类更多是进行修改**
- 现在的对话数据集已经不是完全由人类编写了,因为我们有了 LLM,更多的是人类进行修改。(*[UltraChat GitHub](https://github.com/thunlp/UltraChat),[ultrachat-map](https://atlas.nomic.ai/data/stingning/ultrachat-1/map)*)
- **模型的认知效应**
- [[幻觉 Hallucinations]]
- # how good
- ## 如何将 SFT 的方法迁移到训练售前助理?
- 人工收集最常见的 Q&A,通过渠道和个人经验
- 把产品资料作给 LLM,然后生成问答题
- *generate 3 specfic, factual questions based on the paragraph below. In addition to the question, also generate the correct answer.*
- # Ref.