# why
- 不同于有明确标准答案的可验证问题,像诗歌、笑话这类不可验证的回答无法判断哪个更好。理论上讲,如果我们有无限时间,我们也可以用强化学习,但是这不太可能,例如 1 个笑话,模型做 1000 次更新,每次更新提供 1000 次指令,最终一个人要评估一个笑话 10 亿次。我们不想这样做,因此我们训练一个“**模仿人类偏好**”的神经网络,叫做 **[[RM 奖励模型]]**,再运行强化学习,用奖励模型代替人类进行评判。
# what
- RLHF是基于人类反馈的强化学习,指利用人类的价值观和偏好来指导机器学习模型的训练。先通过人类反馈来训练一个“奖励模型”,再进行强化学习。[[1](https://en.wikipedia.org/wiki/Reinforcement_learning_from_human_feedback)]。
# how
- ## RLHF 与 RL 的区别
- **RL方法:**
- 按照通常的方式运行强化学习,进行1,000次更新,每次更新使用1,000个提示和1,000次回合。 (成本:1,000,000,000次来自人类的评分)
- **RLHF方法:**
- **步骤1:** 选择1,000个提示,获取5个回合,并根据从最好到最差的**顺序**排列它们。 (成本:5,000次来自人类的评分)
- **步骤2:** 训练一个模拟人类偏好的神经网络(即“**奖励模型**”)。
- **步骤3:** 像往常一样运行强化学习,但使用模拟器(即奖励模型)来代替实际的人类评分。
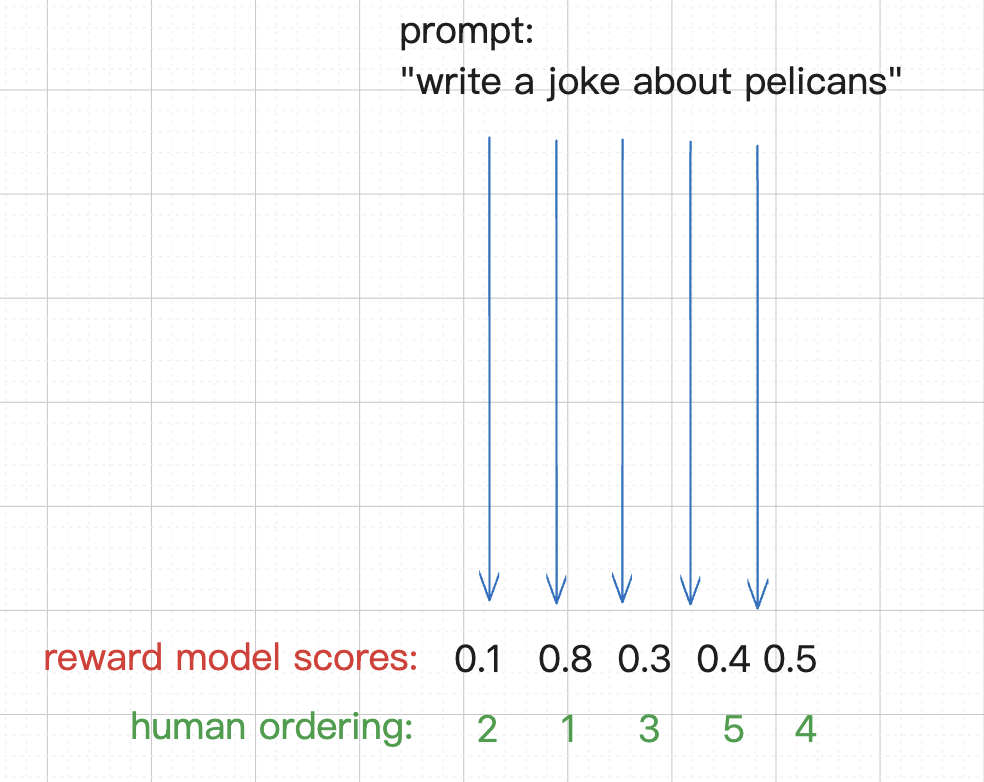
- 奖励模型训练
- 对于一个 prompt,奖励模型给出 0-1 的排序,最高为 1,最差为 0
- 人类给出自己的排序
- 模型根据人类的排序调整参数,最终的输出更加符合人类的价值观和偏好
- 
| | 本质 | 思维链 | 举例子 | |
| ---- | ------------------------- | ---------------------------- | ------------------------------------------------------------------------- | ---------------- |
| RLHF | **奖励函数**本身是人为设定的,即并不是自我博弈 | 并不是真正的 RL,没有思考过程。 | 做练习题,给出问题和答案,让模型去想解题思路,但是是基于人类反馈的结果。好比会获得奖励的目标并不是出于内驱力,而是外界环境设定的,例如父母的目标。 | 不可验证的问题,例如诗歌、笑话。 |
| RLFT | 真正的强化学习 | 产生了类似于人类的思考过程[[CoT]]、[[ToT]] | 专业训练/考前集训+内驱力 | 可验证的问题,有明确的标准答案。 |
- **应用场景**:
- RLHF被广泛应用于自然语言处理(NLP)领域,特别是在如OpenAI的ChatGPT和InstructGPT等语言模型的训练中。这些模型通过RLHF能够更好地反映人类的价值标准和偏好[[3](https://atmarkit.itmedia.co.jp/ait/articles/2306/07/news025.html)]。
# how good
- **启发**
- 就像人类的解题经验集,对练习题进行分类,每类问题寻找到一种最佳解决方案
- 也像是[[思维模型]],解决问题的工具
- **人类偏好和价值观的反馈也会带有人类的其实和偏见**
# Ref.
- [Fine-Tuning Language Models from Human Preferences](https://readwise.io/reader/shared/01jsx75r4mjxqdv08vhfhepade)