- Objective:
- Breadcrumb: 机器学习 - 强化学习
# 概念阐释
- 强化学习(reinforcement learning)[[machine learning 机器学习]]研究的分支领域,最早由 DeepMind 发现([mastering the game of go without human knowledge](https://www.nature.com/articles/nature24270))。模型通过自我博弈来找到最佳解题思路,而非根据人类价值观偏好来回答([[RLHF 基于人类反馈的强化学习]])。
- 这一模型受动物实验中的“**关联学习**”的启发,动物会观察周围的环境,并从每一次的结果中学习,奖励多的结果会被记住和放大。**基本过程**:在强化学习模型中,agent(智能体,动物或人)与环境不断发生交互,agent采取一个行为,环境给出一个反馈:奖励或惩罚,然后智能体根据反馈来改变他下一轮的学习的状态。
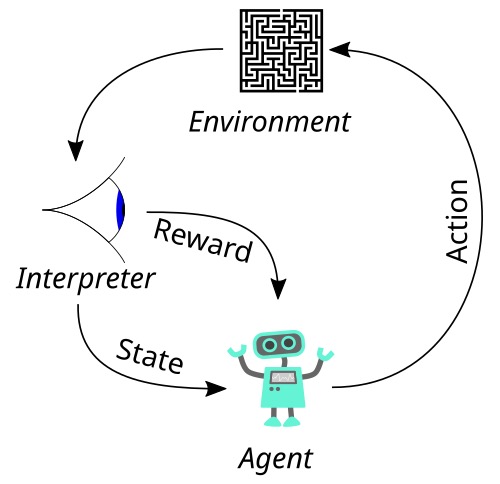
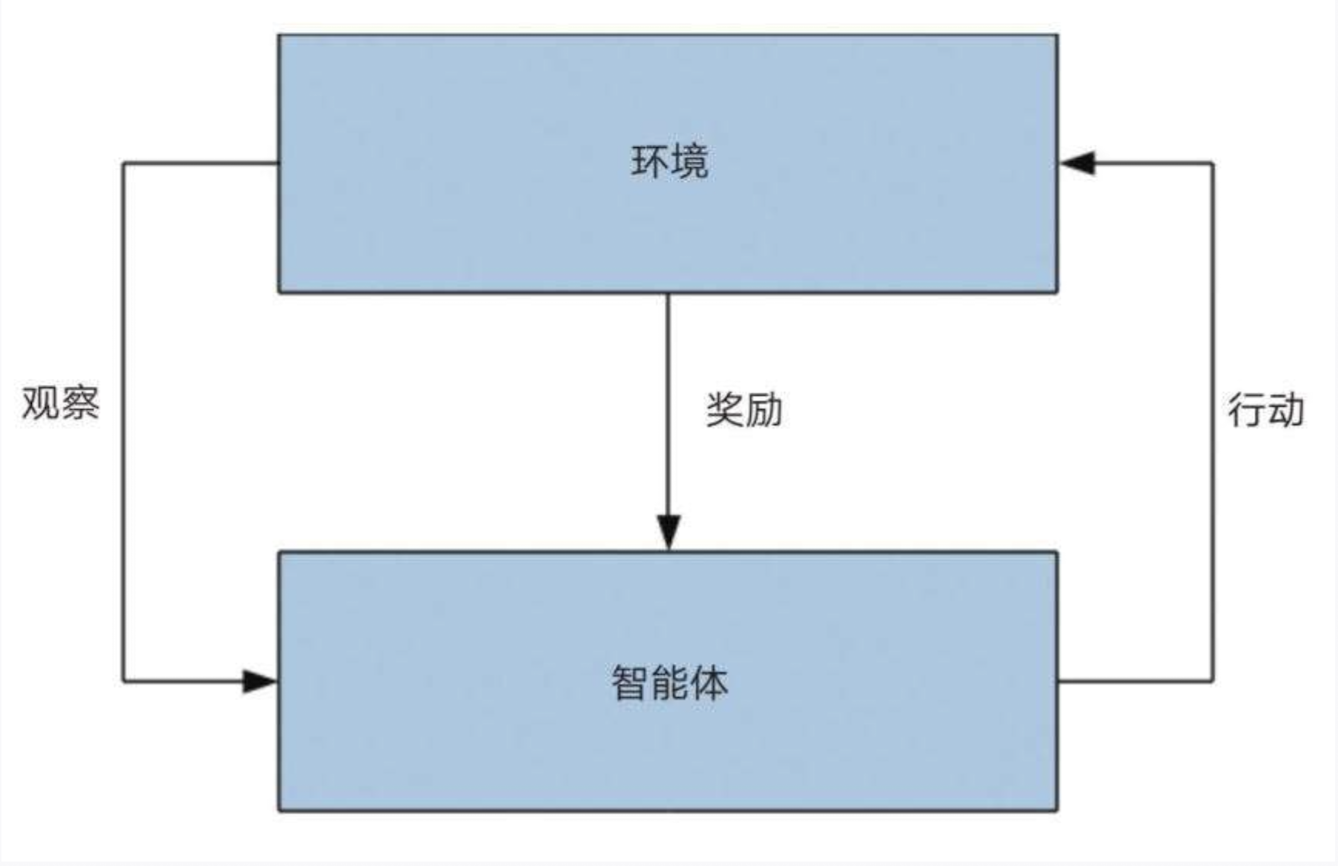
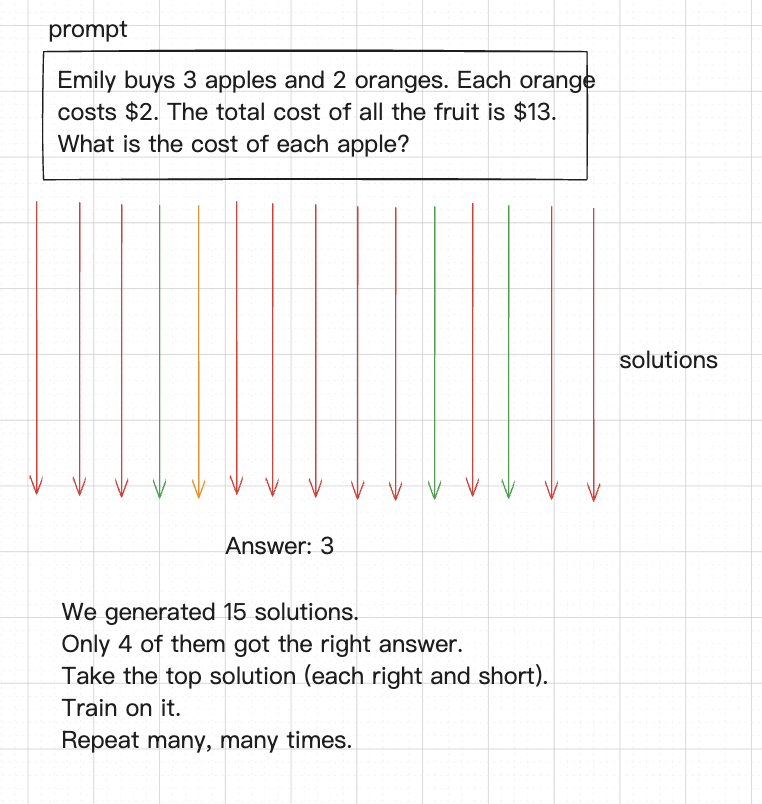
- **实现方法**
- 人类给出问题和标准答案,就像教科书中的「练习题」一样
- 模型生成不同的解题过程
- 从中选出最好的(不仅正确而且简洁)
- 训练这种解题思路
- 重复以上成千上万遍,并且真正的训练是成千上万个问题覆盖多个领域同时进行训练
- 
# 实例
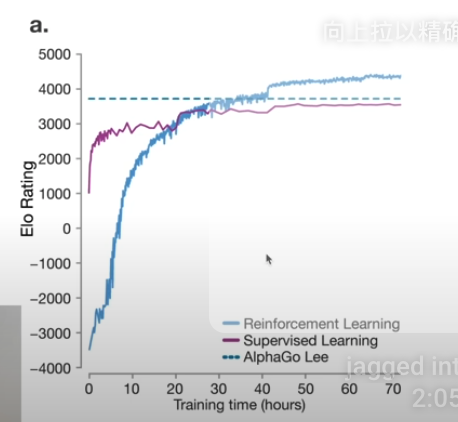
- AlphaGo 基于强化学习算法,必须在比宇宙中的星球数量还要庞大的摆法中走出最佳策略
- AlphaGo 通过自我博弈,水平超过了模仿人类专家下的监督学习所能达到的最高水平
- 
- [[o1]]的[[深度解读“强化微调”,o1模型训练的关键|强化微调]]使用了类似 AlphaGo 的强化学习算法,[[CoT]]
- [[o3]]使用的是[[ToT]]
- [[DeepSeek-R1]]
- ❌ GPT系列训练的最后一步虽然是 [[RLHF 基于人类反馈的强化学习]],但不算真正的强化学习。
# 相关内容
- 与[[Deep Learning 深度学习]]不同的是,深度学习的唯一工作是将输入转换为输出,而强化学习是与环境进行交互。
- 在预测未来奖励的评估中使用[[TD 时序差分学习]]。
- 在人类和动物身上,对于**未来奖励的折现率**是强化学习的关键产物,[[认知神经科学 折现因子]]决定了智能体会关注即时奖励还是未来奖励。
# 参考资料
- [0.3 人,为什么要学习?](https://www.candobear.com/p/t_pc/course_pc_detail/image_text/i_65c07cebe4b064a83b933e07?community_id=c_65b634d2dd106_nhCXKYc72308&product_id=course_2ba4aSp8cPi3TjgH1xc2GxANJHL)
- [强化学习-维基百科](https://zh.wikipedia.org/wiki/强化学习)
- [围棋摆法的数量-GPT](https://chatgpt.com/share/b4b00dde-daec-4c92-b2c2-86b9c1b6dce9)
- 《深度学习》谢诺夫斯基 10