- # why
- # what
collapsed:: true
- [[Pre-training 预训练]]是基于 [[Transformer]]神经网络架构,采用[[端到端]](无需人工干预)的学习范式进行的[[LLM 大语言模型]]训练的核心技术。
- # how
- ### 数据批次处理
- 数据经过嵌入层后会被整理成一批一批,分批次进入transformer,可以相信成一个==立方体==, 这个立方体的长宽高分别为==上下文长度(2048)x 维度(12288) x 批次==。
collapsed:: true
- B [[batch size]]批次大小:例如 8
- T [[context length 上下文长度]]:
collapsed:: true
- 例如 GPT-3 为 2048
- o1: 20 万,输出 10 万
- o3: 40 万,输出 20 万
- V 维度:例如 GPT-3 为 12288 维度
- 
- ### Transformer 模型,向前传播,生成下一个词的概率分布
- 在神经网络的内部,[[LLM本质]]上只做一件事,==生成下一个 token==。在预测下一个token 时,每个 token 只看本行之内的和前一个 token 来进行预测。
collapsed:: true
- 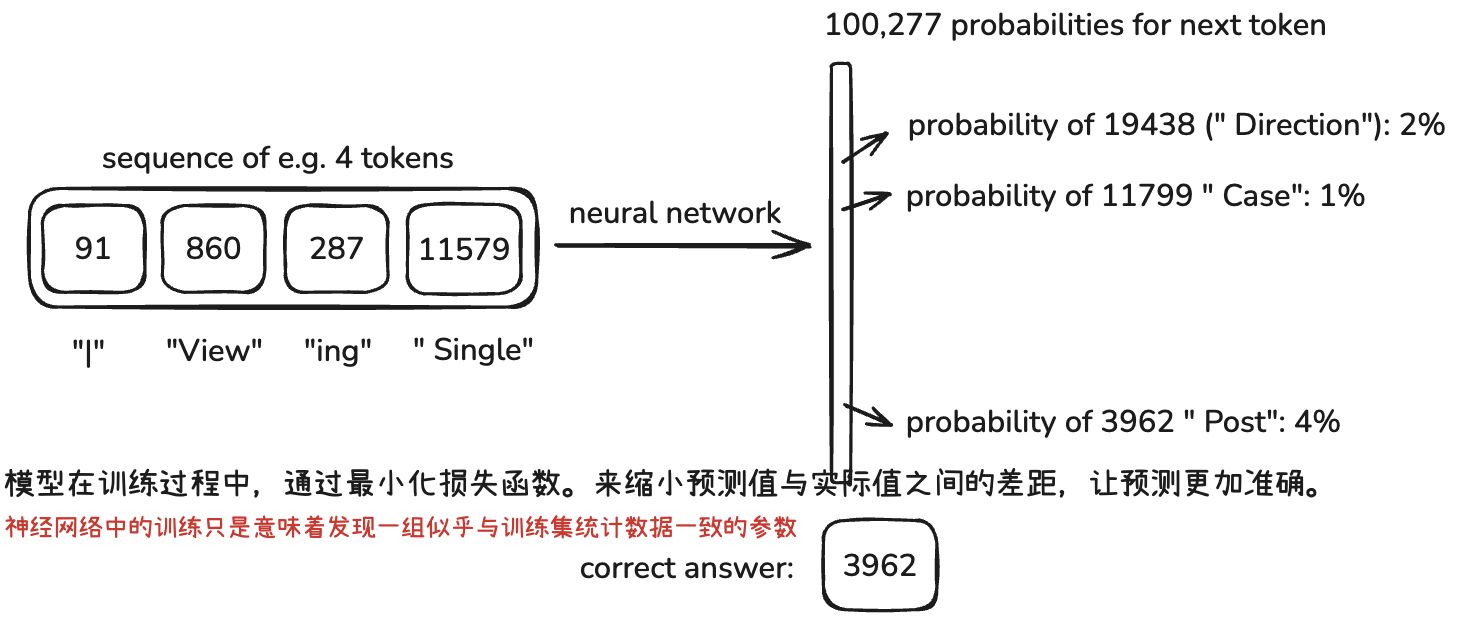
- 这些数据向量与模型内部的权重进行[[矩阵向量乘法]]运算,每生成一个 token 都会有所有词汇表的概率分布,然后取最大概率的那个 token。
collapsed:: true
- {:height 273, :width 527}
- [[Embedding]]
- [[Transformer]]
- [[Layer Norm]]
- [[Self Attention]] [[自注意力机制]]
- [[Projection]]
- [[MLP 多层感知器]]
- [[output]]
collapsed:: true
- layer norm
- [[linear]]
- [[Softmax]]
collapsed:: true
- 通过 softmax 函数,会给词汇表中的每一个 token 分配一个概率,加总等于 100%,生成的下一个词会是概率最高的那个。
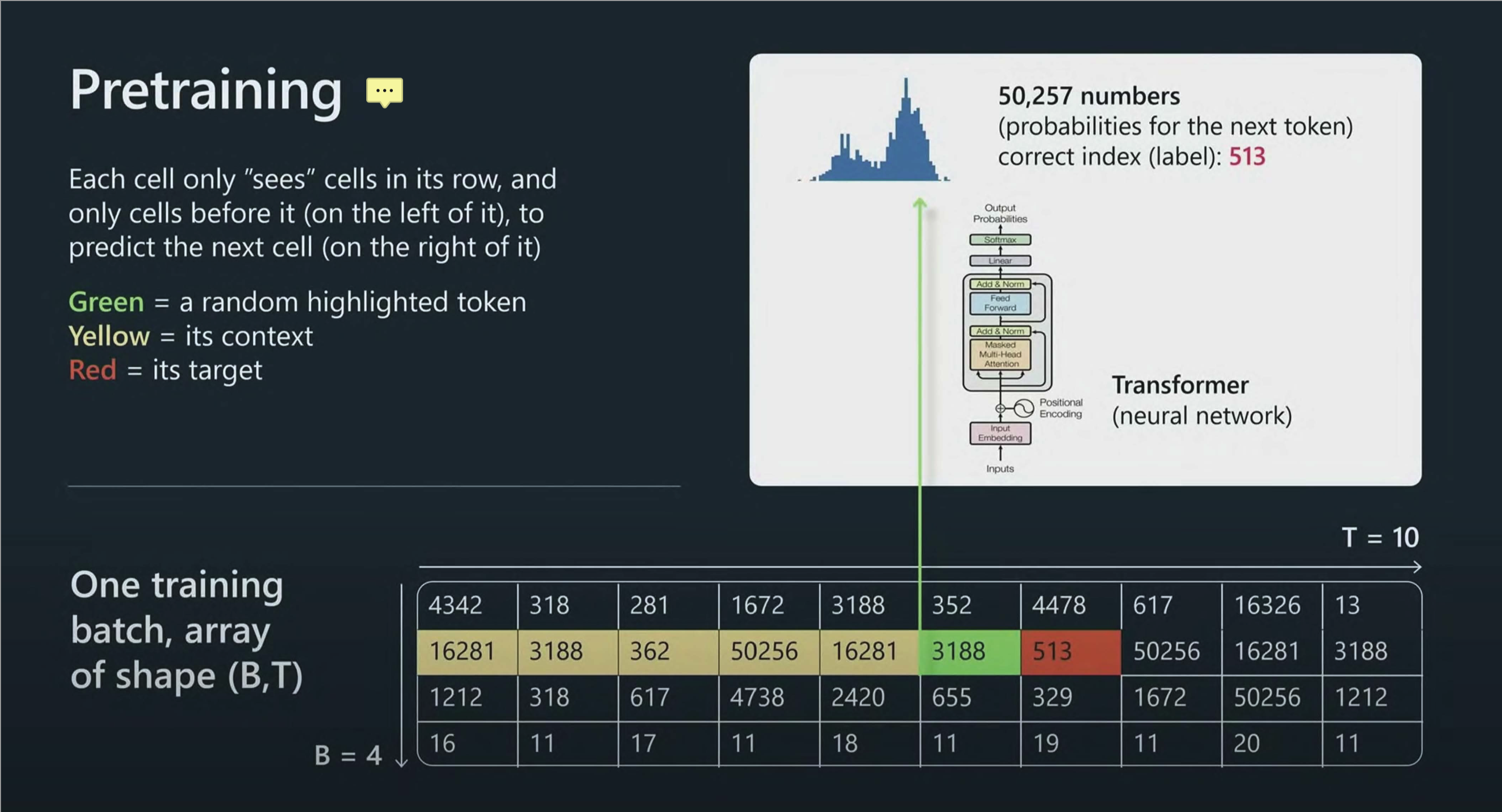
- ### 计算[[Loss function 损失函数]]
- 计算[[Loss function 损失函数]]是为了看生成的下一个词与实际词的差距。就好像我们学一个难懂的概念,要经过抽象理解、实践、应用多次才能越来越趋于准确地理解。笔记的迭代次数。
- Transformer模型的预测结果与真实的标签Token ID进行对比。
- 
- ### [[Backpropagation 反向传播算法]] 计算梯度
- 直觉上:
collapsed:: true
- 从输出层(从可预知的结果出发)往输入层反向逐层计算损失函数关于网络中每个参数(权重和偏置)的**梯度**。
- 随机梯度下降会更快
- 微积分
collapsed:: true
- 本质上就是通过[[链式法则]]求偏[[导数]],避免做冗余的重复运算。
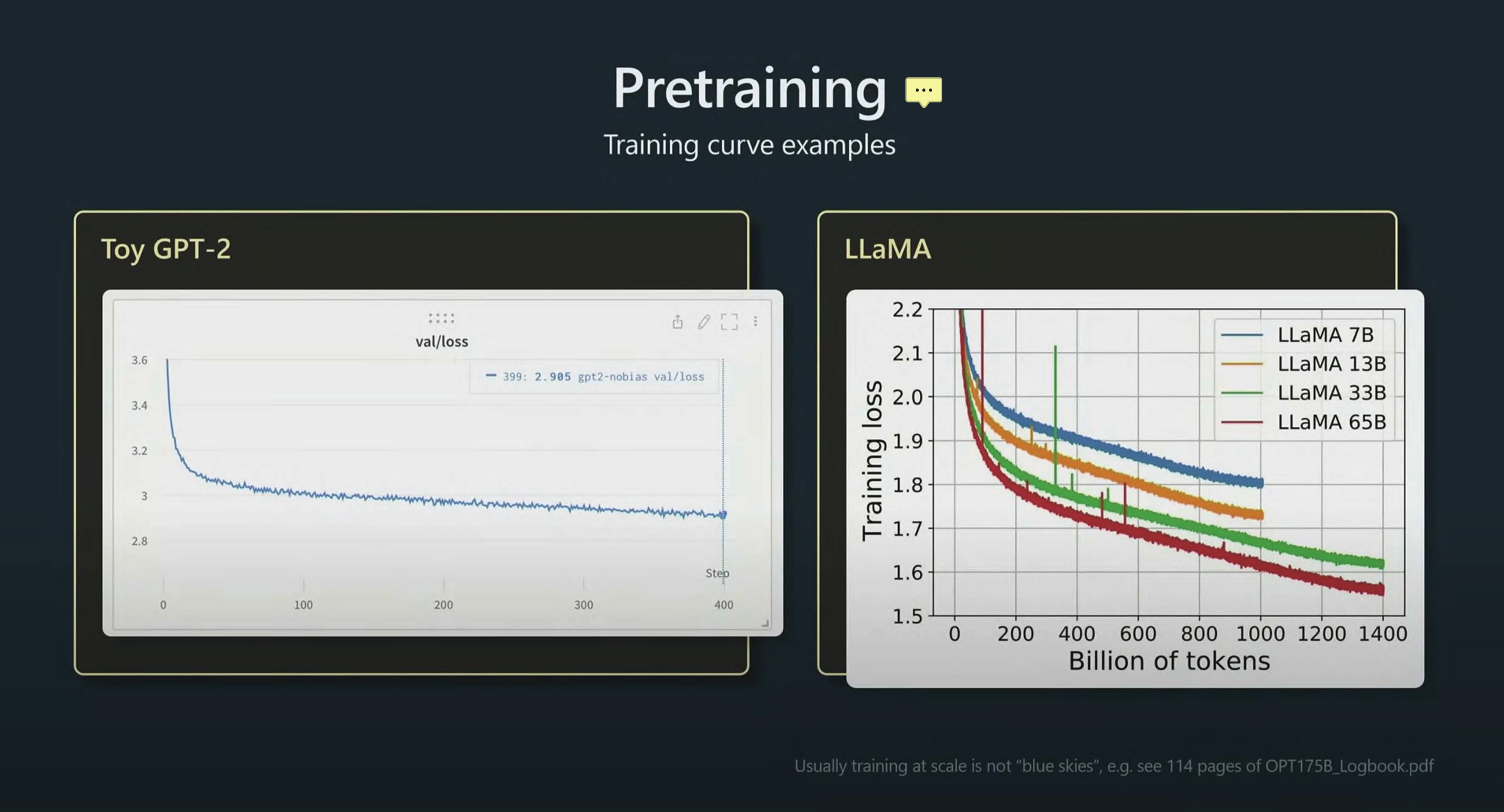
- 模型在训练过程中的更新至少经过 3000 次以上。
- ### 更新参数,[[gradient descent 梯度下降]]算法
- 根据计算得到的梯度,以学习率(learning rate)为步长,更新参数:
- 参数更新公式:$w_{new} \leftarrow w_{old} - \eta \frac{\partial L}{\partial w}$
- 
- 更多的训练数据与迭代次数意味着更低的 loss,意味着更准确的预测
collapsed:: true
- 
- ### 结果
- 一份不再更新参数的基础模型 base model,可以发布或者不发布。
- 如果部署到服务器中,供人在[[推理阶段]]使用或者进行后训练。
- ### 总结
collapsed:: true
- 基础模型是一个词元单位级别的==网页文档模拟器==
collapsed:: true
- 非常随机的,每次运行的结果都不太一样
- dream internet documents:梦境版的互联网文档,一样却又不太一样。更好的解释是类比于人类的输出,不是完全背诵,但又是基于理解的输出
- 可能会逐字背诵互联网文档
- **模型的参数可以类比于人类大脑的神经元突触链接,从随机参数开始,经过多次数据的迭代学习并理解了人类的语言,获得了人类的知识。**
- 利用模型的本质:根据提示 prompt 生成下一个词,可以将模拟器训练成一个有用的助理,但更好的方式是后训练
- # how good 预训练引发的思考
collapsed:: true
- ### 知识不是靠上传,而是靠学习
collapsed:: true
- 大语言模型并不是把互联网上的所有信息硬存储在服务器上,而是将==信息作为学习的素材==,像人类一样,通过==识别数据中特征和模式==,形成自己的理解。
- 例如我们在认识一个事物的时候,通过它的数量、关系、动作、等等来理解,而大语言模型通过==精度更高的维度。==
- **并且信息不仅学一遍,要学几万遍**。大模型的每一次迭代都是对万亿参数的一次更新,以此来调整输出质量。就像我们的学习一样,全新的概念只看一遍是不能准确掌握和运用的,都要经过长期的实践和理解。
- 
- 
- ### 理解了人类的自然语言
collapsed:: true
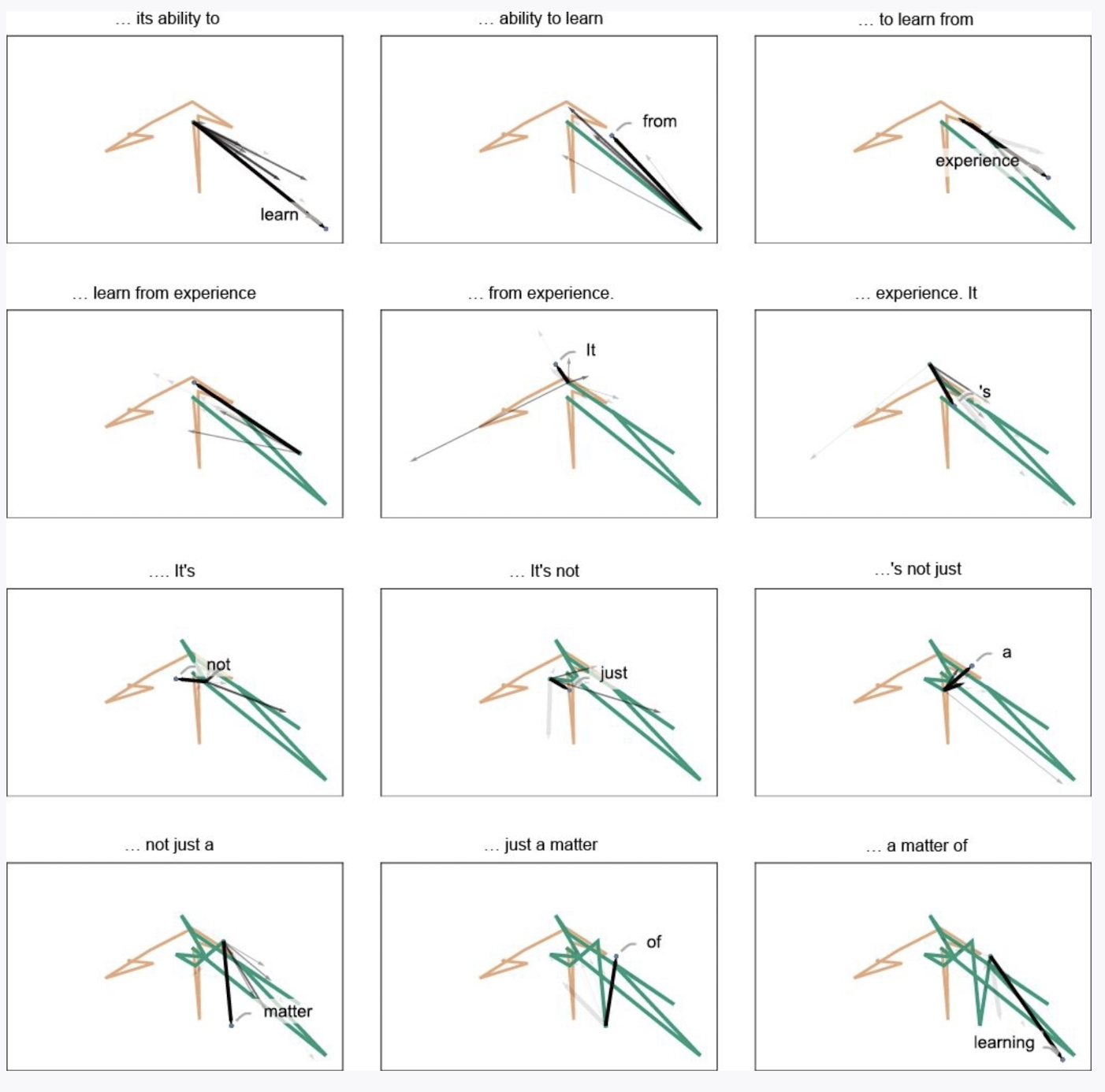
- 在嵌入 embedding环节,我们看到了 token 被转换成高维向量,通过不同于人类的理解方式,LLM能够捕捉到输入信息中的复杂性和细微差别(nuance),形成了自己的[[语义空间]]。生成的过程是在这个空间中进行的一种语义运动。
- 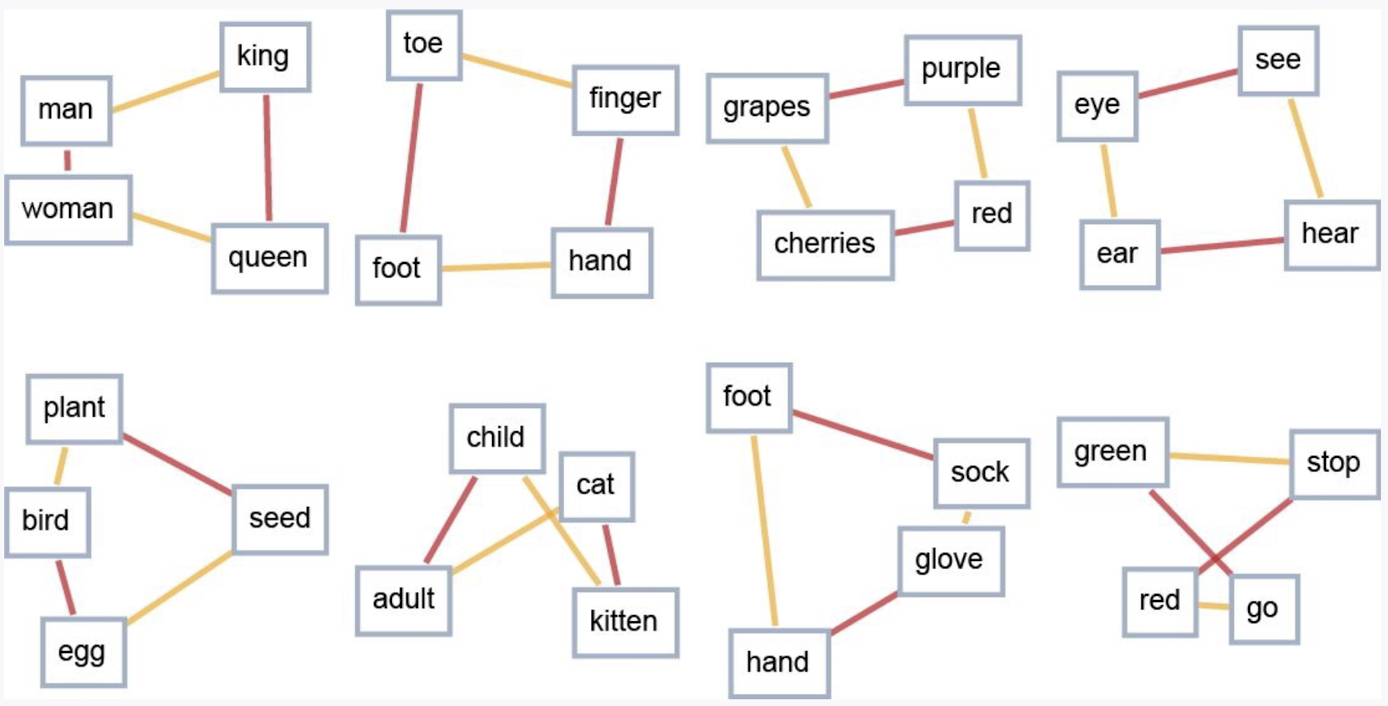{:height 357, :width 687}
- 
- ### 生成式 AI
collapsed:: true
- **输出不是靠提取,而是靠生成**:每生成一个 token,是万亿参数的一次运输。而不是直接提取数据。
- ==生成 generative==这个概念乍一听好像没什么了不起。但仔细想想,能够==准确地生成下一个词==的前提必须是==理解==,而且还要理解的很透彻才能生成。
collapsed:: true
- 大家都学过英语,知道==听力、阅读==和==口语、写作==的区别。看得懂说不出、写不出是常态,因为输出需要更多的训练和理解。
- 另一个例子是我们在==阅读==和==对话==的时候其实也在进行预测。
- **副作用**
collapsed:: true
- 随机性强,可能会得到一个和互联网上的数据一模一样的回答。也有可能相近。但同时也会有出现**幻觉**的时候。不过这个问题在[[gpt-4.5]]中得到了改善。
- ### 模型的通用能力 - 知识大模型
collapsed:: true
- 所以为了做到生成下一个词,就迫使模型掌握全世界的知识,而不是在一个==狭窄的领域==进行训练。所以大语言模型也可以成为==知识大模型==。
- ### 快思考
collapsed:: true
- 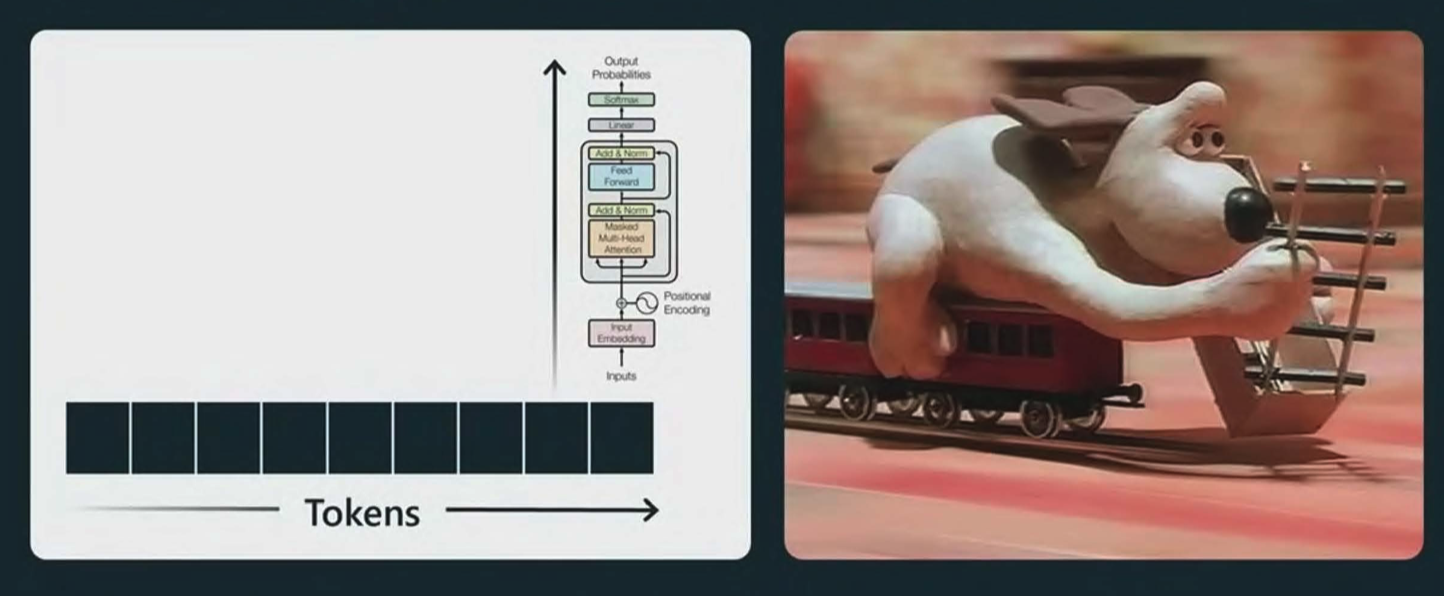
- 大语言模型基于预训练的这种方式和 transformer 的本质==预测下一个词==,决定了大语言模型使用的是一种快思考的思维方式。类似于人类的==本能反应==。图中的小狗,一边搭建轨道,一边快速向前跑,不会思考方向、目的地。
- **快思考**:但是某些问题在解决时需要进行思考,思考时间可以是几分钟、几小时、几天,甚至几年。这就有了后面的[[推理模型]]
- # todo
collapsed:: true
- [[batch size]]
- [[epochs]]轮次
- [[向前传播]]
- [[Backpropagation 反向传播算法]]
- [[gradient descent 梯度下降]]
- [[Loss function 损失函数]]
- 怎么做到?为什么能做到?步骤流程?
- # Ref.
collapsed:: true
- [训练阶段表](https://docs.google.com/spreadsheets/d/1OtALkJzgRvhuTMjAcWGw_L46GtNY5jDTl25w3ZndimY/edit?gid=0#gid=0)