- Objective:
- Breadcrumb: 自然语言处理、算法

# 概念阐释
- **定义**:基于理解、预测和生成人类语言的计算机算法。
- 本质:
- 基于深度神经网络(通常是[[Transformer]]结构)的**统计模型**。在海量文本数据上学到了一整套复杂的**语义分布和模式**。
- 目标:预测下一个词
- 原理:结合上下文,找到出现频率最高的词
- 关键特点:
- **预训练**:先在大规模无标签文本上训练,学习通用的语言表示。
- **微调/指令微调**:在下游任务或对话场景进行有监督微调,提高在特定任务上的表现。
- **多用途**:LLM 属于[[生成式 AI]]的一种形式。通过获取输入文本并重复预测下一个标记或单词。可广泛应用于文本生成、摘要、翻译、代码生成等多种场景。
# 实例
## 最受关注的LLM
- OpenAI的[[GPT]]系列模型
- GPT3.5
- GPT4
- GPT4o
- ChatGPT
- Copilot
- Google 的Gemini
- Meta 的 LLaMA
- Antrropic 的 Claude
# 相关内容
## 之所以叫做大语言模型有 3 点原因:
- **大规模预训练数据**
- 深度学习技术在自然语言处理领域的缺点是需要使用大量标注数据,这会导致标注大规模语料库时间过长,人力成本高,语料库不够充足。即便是[[Pre-training 预训练]]中的**原任务**也需要人工标注。解决这一问题的方法是:**将文本自身的顺序性视作一种天然的标注数据,通过若干出现的词语预测下一个词语**。从网页和电子书中可以获得几乎无限的超大规模预训练数据。
- 这种方式常被称作“无监督学习”,其实这种说法并不准确,因为学习的过程仍然是有监督的,因此应该叫做“[[self-supervised 自监督学习]]”。
- **大模型**
- 有了足够多的数据,就需要一个足以容纳这些数据的模型。LLM 使用的是[[Transformer]]架构,该架构于 2017 发明。基于Transformer架构的 LLM 是[[NLP 自然语言处理]]的新范式。
- “大模型”则更多强调网络的规模(参数数量、层数等)。模型的容量大通常是指“[[parameters 参数|参数]]”量大,例如 700 亿个参数的 Llama 模型,1 个参数包含 2 个字节,所以 700 亿参数的模型需要 140GB 的储存空间。之所以是 2 个字节是因为数据类型为 16 位浮点数。
- 获得更大量的参数需要满足两个条件:
- 较高的并行处理速度
- 能够捕获并构建上下文信息,能够充分挖掘大数据文本中的语义信息
- transformer模型是解决以上问题的最佳选择。(详情见[[Transformer]])
- **大算力**
- 训练大语言模型的芯片通常使用[[GPU]](图形处理单元)和[[TPU]](张量处理单元)。因为:
- 相比[[CPU 中央处理器]],GPU 擅长的任务不同。CPU 擅长处理串行运算、逻辑控制和跳转。GPU 擅长大规模并行运算,深度学习经常涉及**大量的矩阵或[[tensor 张量]]之间的计算**,所以适合 GPU 处理。
- [[TPU]]是谷歌研发的一款专门用来提升机器学习任务训练时间的集成电路。
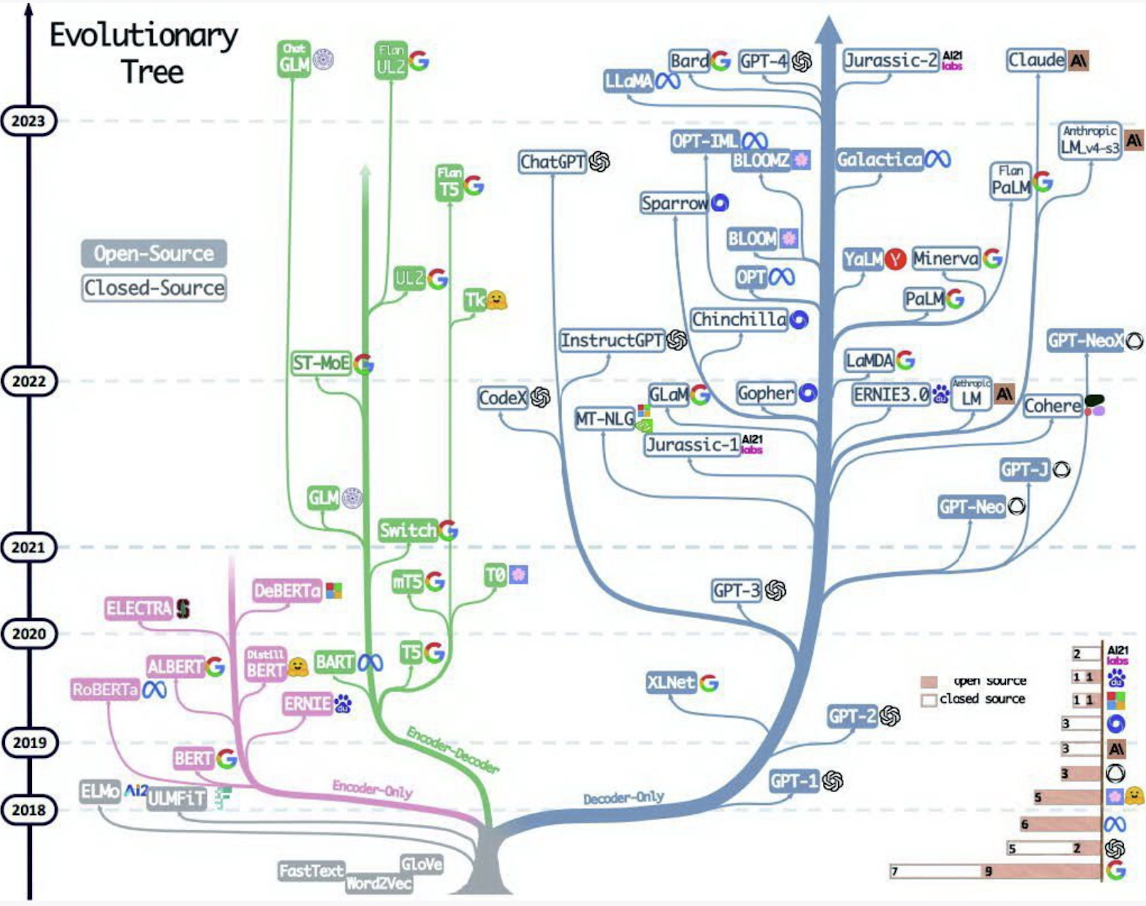
## LLM的历史
^061b01
- 在 2012 年,神经网络[[AlexNet]]在图像识别方面称为**主导地位**后,基于神经网络的预训练模型方法也被语言建模领域接受了。
- 2016 年,Google 将翻译服务改为基于深度学习的算法,在此之前使用的是seq2seq deep LSTM 神经网络。
- 2017 年,Google 发表论文“attention is all you need”,其中介绍了 [[Transformer]]架构。论文的目标是对seq2seq技术的改进。
- 2018 年
- 谷歌发布[[BERT]] ,是仅编码器模型(encoder-only),提出了[[Pre-training 预训练]]的方法。
- OpenAI 发布 ==GPT-1==
- 2019 年,OpenAI发布==GPT-2==
- 2020 年,OpenAI 发布==GPT-3==
- 2022 年,OpenAI 发布 ==ChatGPT==,使用 GPT3.5
- 2023 年,OpenAI 发布 ==GPT-4==
- 2024 年,OpenAI 发布==[[GPT-4o]]==,多模态
# 参考资料
- [LLM-维基百科](https://en.wikipedia.org/wiki/Large_language_model)
- [Intro to LLM](https://readwise.io/reader/shared/01hhtrqw42rdqw5hyv7j5gf0q4)
- [知识体系的科学原理](https://readwise.io/reader/shared/01jc83bqjmj62eaggdp04yb1ws)