- Objective: 大语言模型本质上是在做什么?
- Breadcrumb:
# 概念阐释
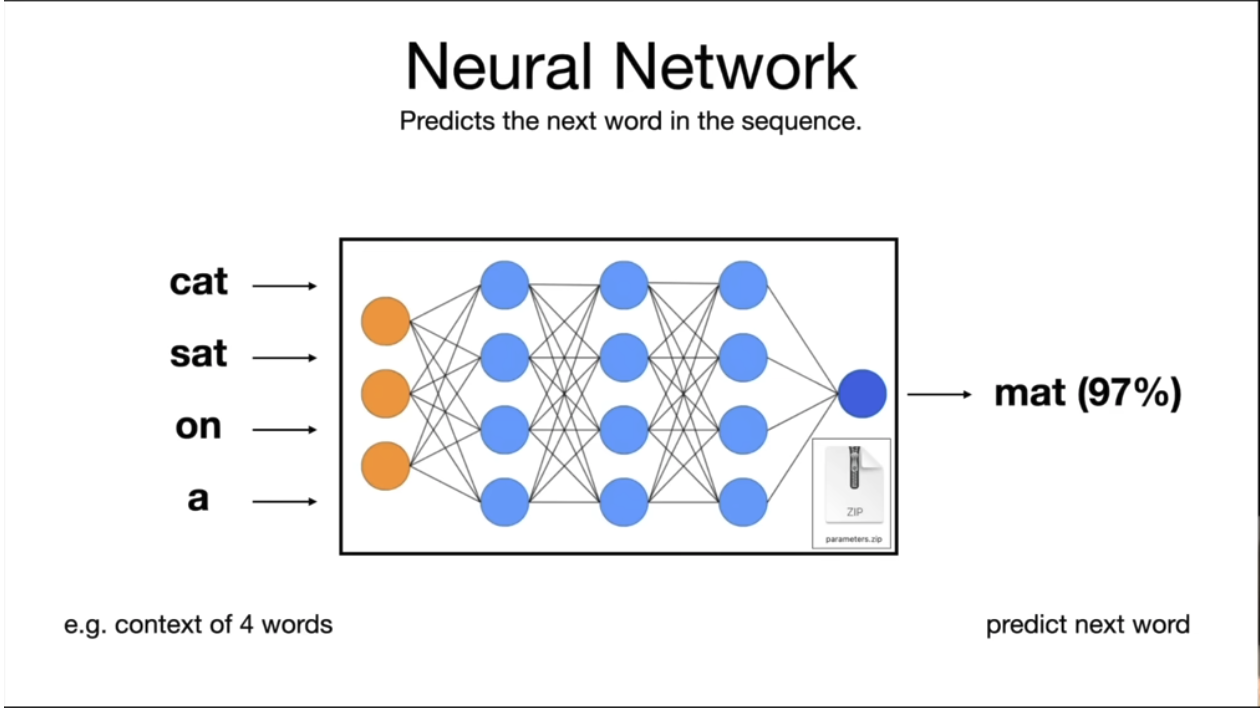
[[LLM 大语言模型]]本质上只做一件事,预测下一个单词。预测下一个词的概率分布使用的是[[gradient descent 梯度下降]]优化算法。
# 实例
在这个例子中,预测句子"cat sat on a"后面的词,mat 这个词的概率为 97%。
# 相关内容
## the network dreams internet documents
当模型“学习”过互联网的知识后进行推理。因为模型不是一字一句地“记住”所有页面的内容,而是用它记住的知识重新生成内容。在这种情况下,模型有时候生成的内容是合理的,有时候则是看上去“合理”的虚构内容:
- 例如:ISBN 或者页面其实并不存在,但他知道 ISBN 后面会跟一串类似数字的东西,这看上去很合理。
- 或者模型生成一篇关于黑鼻鱼的内容,如果你查阅资料,这个信息大致是正确的。所以网络拥有关于这种鱼的知识,它知道很多关于这种鱼的信息。它并不会完全复述训练集中的文档,但它对这些知识进行了一种有损压缩,它大致‘记得’这种知识,然后生成正确的形式,并填充它的一些知识。
- 或者你向模型提出一些问题,它可能会继续生成一些问题。
你永远不能100%确定它生成的内容是我们所谓的‘幻想’(或错误答案)还是正确答案。有些内容可能是记住的,有些则不是,但你无法确切知道哪部分是哪部分。
## system 1&2
^20b23f
有一本书叫做《思考快与慢》,内容大致说的是人有两种思考问题的方式:
- system1,本能的,不假思索的,例如 2+2,或 speed chess
- system2,理性的,有逻辑的思考,例如 23x42,比赛时的下棋,需要在脑子中排列出各种可能
目前的LLM,在预测下一个词时更像是使用了 system1,“本能“的给出下一个词。但未来的大模型趋势是构建 system2,让模型学会理性”思考“。也可以尝试引导现在的模型进行有逻辑的一步一步的思考。
# 参考资料
- [语言模型-Wikipedia](https://zh.wikipedia.org/wiki/%E8%AA%9E%E8%A8%80%E6%A8%A1%E5%9E%8B)