# WHY
[[LLM 大语言模型]]的原理,以 GPT,llama 为例。
# WHAT
- 第一部分:什么是大语言模型 LLM
- 阶段 1:预训练
- **模型的[[parameters 参数]]是如何获得的?**
- 预测与压缩(参数)之间有非常密切的关系[[预测即压缩压缩即智能,智能即具备理解力]]
- **what is this LLM really doing?[[LLM本质]]上在做什么?**
- 神经网络如何进行推理?("梦见网页“而不是一字一句的复制,互联网生成器)
- 神经网络是如何工作的,到底是如何预测下一个词的,黑匣子里是什么?
- 目前,人类并不知道黑匣子是什么。我们能够了解模型的架构,我们清楚地知道在其各个不同阶段发生的数学运算,但是万亿参数会遍布在整个神经网络中,我们能做的是制定相应复杂的评估方法。 measure,adjust,iterate,optimize,evaluate
- 我们能做的只有调整和优化这些参数,让模型在预测下一个词时表现的更好。
- 这有点颠覆我们的认知,我们创造了一个我们不能完全了解的机器,它并不像一辆汽车,对于汽车的每个部件我们都是了解的,但是大语言模型不是。
- 举一个例子,逆向工程,问 GPT4,汤姆克鲁斯的妈妈是谁?它知道。但是问who is Marie Lee Pfeiffer'son?它却不知道了。这个例子表明模型在使用互联网数据进行训练后,似乎建立了一套自己的知识库,但是如果人类想使用这套数据库也需要具备一定的知识体系,知道如何从一个正确的角度向他提问。(GPT4o 利用多模态解决了这个回答)

- 阶段 2:微调fine tuning,获得一个真正的 AI 助手
- 阶段3:比较(强化学习)
- 其他
- 标签说明
- 人机协作
- 模型比较:开源与不开源
- 第二部分:大模型的现在和未来
- [[规模法则 scaling laws]]
- 大模型的进化关键,像人类一样**使用工具**
- 大模型的进化主轴:**感知能力**,多模态,看、听、说
- 未来的方向
- [[LLM本质#^20b23f|system2]]
- **自我提升**:[[奖励函数,LLM 超越人类的挑战]]
- **GPT 助理**:
- [[RAG 检索增强生成]]可以检索你自己的知识库,定制专家模型,而不是用一个模型解决所有问题
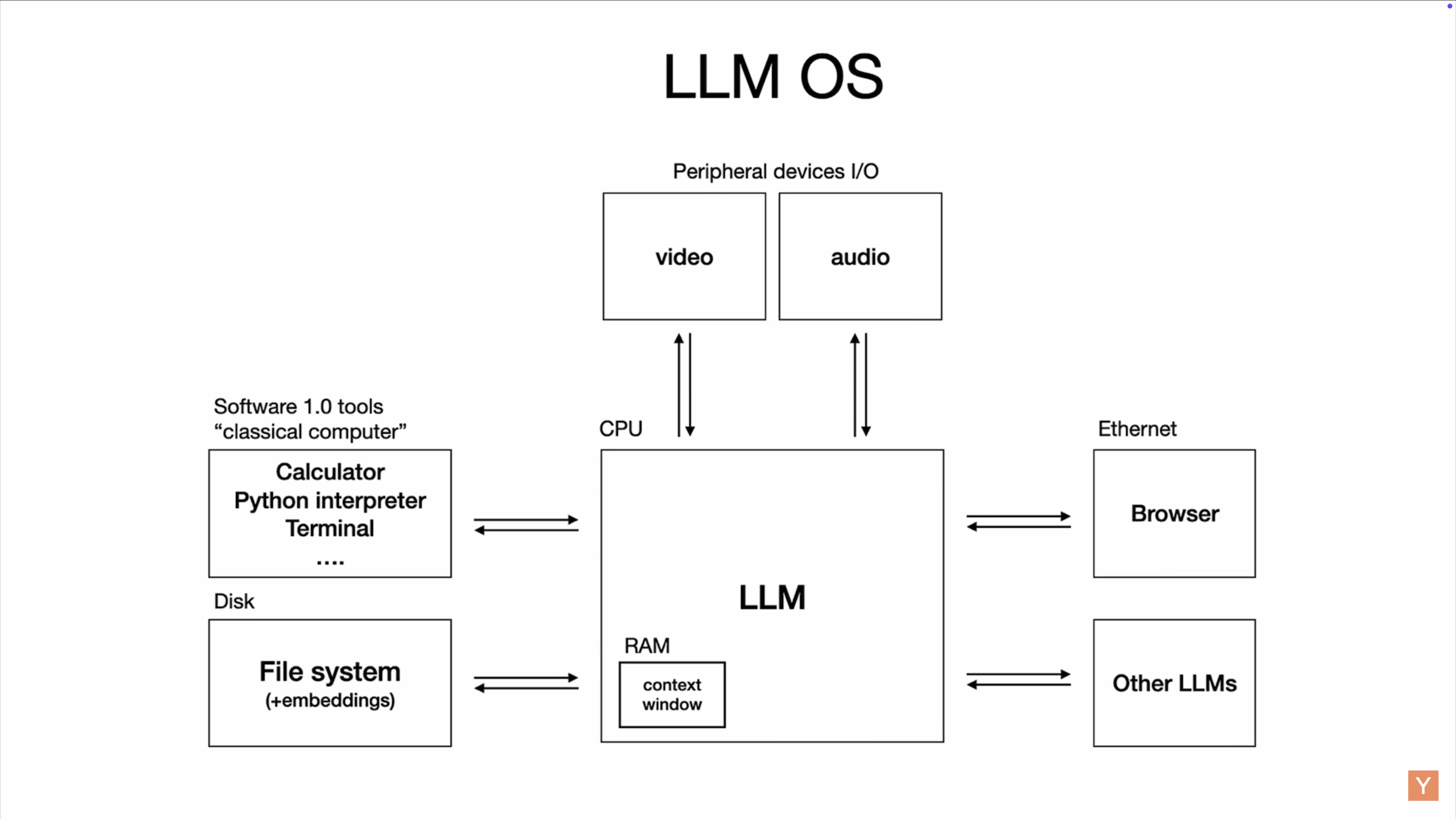
- 第二部分总结:[[LLM OS]]
- 
- 未来几年内LLM能做的事
- [[context length 上下文长度]]相当于计算机的内存
- LLM类比当今的电脑架构、LLM 的经济环境类比操作系统的开源和不开源
- GPT、Bard、Claude相当于 windows、MacOS
- llama 相当于 Linux
- 第三部分:安全问题
# HOW
## 大语言模型训练步骤
- 阶段 1:预训练
- 将互联网数据(10 TB)输入进神经网络模型进行训练,例如训练llama 270b大概需要 6000 个 GPU,运行 12 天,花费 200 万美元。预训练阶段是成本最高的阶段。训练好后会得到一个参数文件,参数的权重决定了预测的内容。10TB 的互联网数据会获得140GB 的参数文件,大概压缩了 100 倍。
- 因为成本很高,所以即便是公司也会以年为单位迭代
- 阶段 2:微调fine tuning,获得一个真正的 AI 助手
- 预训练后的LLM还不会回答问题,例如你给它一个问题,它会返回更多问题,
- 微调的目的是将模型从一个网页生成器变成一位有用的“助手模型”,能够帮助用户解决问题。
- 微调的过程与预训练最大的区别在于数据集,预训练讲求数据量大,但质量低。微调的数据量可以小,例如 100000 份Q&A 文件,但是质量要求很高。
- 公司会聘请人类来编写答案,公司还会提供相应的标签说明文件来规定答案的质量
- 微调因为很便宜所以可以迭代很快,每天、每周
- 阶段3:比较(从人类的反馈中进行强化学习)
- 有的公司会使用答案对比,这一步可以和第二步是“and/or"的关系,比较答案要比纯生成答案更容易。在第二阶段中,模型会生成候选答案(例如,几个候选的“俳句”)。人工标注者不需要自己写出完整的答案,而是通过比较模型生成的候选答案,选择出最好的。这样做比直接写答案要更容易。然后,在第三阶段的微调过程中,可以利用这些比较标签(即哪一个候选答案更好)来进一步优化模型。这一方法有助于减少人类标注者的工作负担,同时提高模型的性能。

# HOW GOOD(思维模型)
- 大模型的训练过程类似于人类学习的过程
- 如何更好地与大模型合作
# ref.
- 
- [GPT-Intro to LLM](GPT-https://chat.openai.com/share/5f42ec69-c936-4ebb-affb-2f6f2803deeb)
- [Readwise](https://read.readwise.io/new/read/01hhtrqw42rdqw5hyv7j5gf0q4)