# why
- 为什么 [[prompt engineering]] 对于大模型有效?
- [[后训练]]的重要性。
# what
- 一种基于[[Instruction Following]]的指令遵循模型,目的是**让模型更好的理解并回复用户提供的自然语言指令。**
- **原理**:通过[[RLHF 基于人类反馈的强化学习]],让 GPT 在后训练中学习很多“通过模仿人类与助理对话的过程”的文档,然后 GPT 就能够模拟这种对话。
# how
## GPT的演化路径
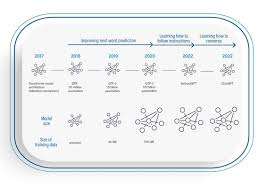
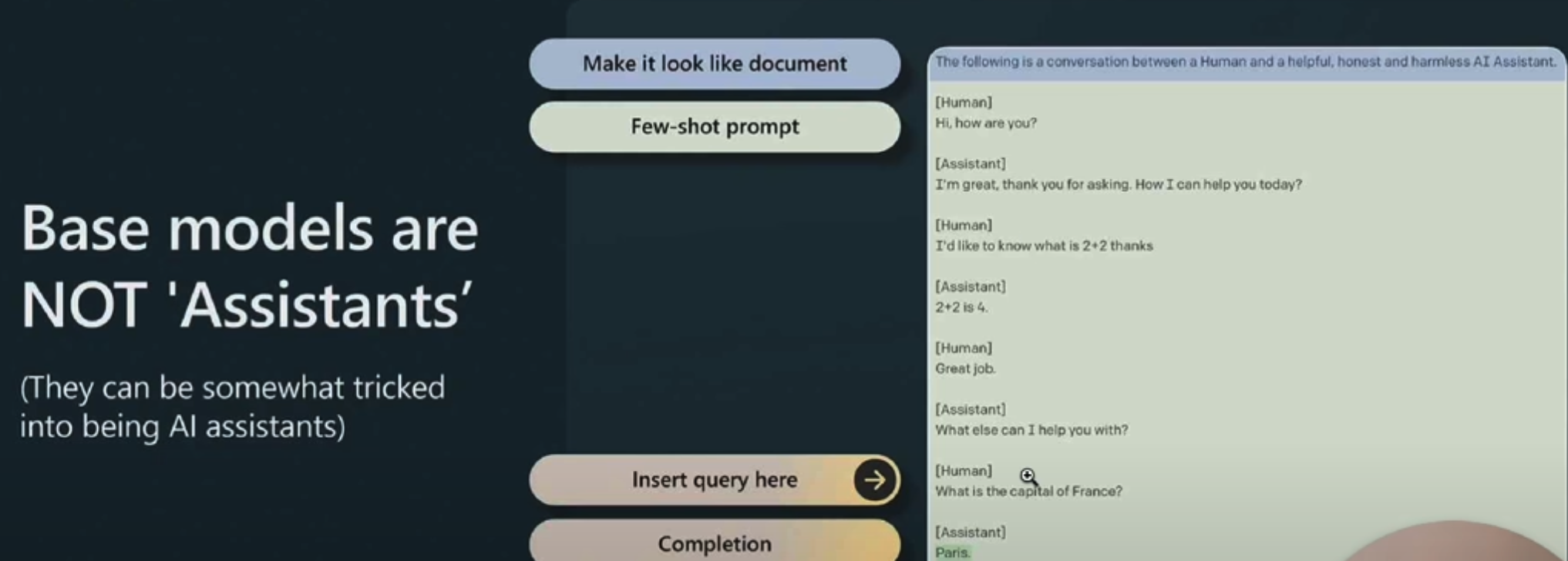
1. 2022 年之前:文本补全模型[[completion model]],相当于[[Pre-training 预训练]]阶段的基础模型,只能模仿训练数据,**并不能生成符合用户期待的对话**。
1. 
2. 2022 年:助手模型[[assistant model]] - [[InstructGPT]],后训练的模型([[LLM 预训练]])
1. 
3. 2022 年 11 月 30 日:以 Chat 为应用场景的[[ChatGPT]]
# how good
# Ref.
- [chat with gpt-指令跟随](https://chatgpt.com/share/67986c8f-a930-8002-b6c5-ceaf2c6c8999)