- Objective: 标记数据集
- Breadcrumb:
# 概念阐释
ImageNet 是一个大型**标注 Labeling**视觉数据库,可以用来训练 AI 算法数据集,由斯坦福大学的[[Fei-Fei Li 李飞飞]]在 2006 年开始创建。该项目手动注释了 1400 多万张图像、2 万多的分类,标记出图片中的对象,并在至少 100 万张图片上提供了边框。2009 年,ImageNet 成为有史以来最大的标注数据集,促成了深度学习的成功。
# 实例
**ImageNet 标注做了什么?**
1. ImageNet 的核心是收集了海量图像,并对每张图像进行了**分类标签**(例如“狗”、“猫”、“苹果”等)。
2. 这些标签并不直接告诉模型哪些像素或哪些局部特征代表狗的耳朵、猫的须子等,而是给出了**全局的类别信息**。
3. 模型在训练时,通过这些标签做**有监督学习**,从而“学会”如何从像素空间中提取有用的特征。
# 相关内容
## ImageNet的起源与发展
### **1. 早期启发:观看猫的视觉实验**
- 李飞飞在大学期间(大约 1990 年代末至 2000 年代初)观看了 **[[Hubel & Wiesel的视觉实验]]**,他们研究猫的大脑如何处理视觉信息。这让她意识到,计算机视觉领域尚未解决的核心问题是:**如何让机器像人一样理解视觉世界**。
- 这促使她思考:**人类的视觉智能如何发展?机器能否通过类似的方式学习?如何让机器认识我们这个现实世界?**
## **2. ImageNet 的诞生(2006 - 2010)**
### **(1)为什么创建 ImageNet?**
- 李飞飞的突破性贡献是提出了**ImageNet** 项目,它的核心理念是:
1. **规模化数据驱动 AI 发展**:如果 AI 要学会识别物体,它需要像人类一样,在大量的视觉经验中训练。一个婴儿从出生起会接触数百万张图像,而计算机要学会识别物体,也需要足够多的训练数据。
2. **计算机视觉需要“大数据”**:当时的 AI 研究大多使用小规模数据集,难以支持深度学习的发展。她意识到,如果能够收集一个涵盖几十万、甚至上百万张图像的大型数据集,并为其提供详细的分类标签,计算机视觉的发展可能会迎来转机。
### **(2)如何创建 ImageNet?**
- **2006 年**,李飞飞开始构思 ImageNet,目标是构建一个**百万级别的图像数据集**,涵盖数千种类别,每个类别包含大量的示例图像。
- 她利用**[[WordNet]]**(一个词汇数据库)来定义类别,并使用**亚马逊[[众包]]平台 Mechanical Turk** 来标注图像,解决了大规模数据标注的难题。
- **2009 年**,ImageNet 数据集正式发布,包含**1000 万张图像、2 万个类别**,成为史上**最大、最完整**的视觉数据集。
## **3. ImageNet挑战赛**
- 2010 年,李飞飞组织了 **ImageNet Large Scale Visual Recognition Challenge (ILSVRC)**,希望研究者能够在这个大规模数据集上训练模型,并推动计算机视觉技术发展。
- 该比赛要求算法在 1000 个类别中进行**图像分类**,并衡量错误率。
- 一开始参赛的算法为[[SVM 支持向量机]]
## **4. 2012 年:AlexNet 的突破**
- 2012 年,**[[Geoffrey Hinton 辛顿]]** 的学生 **Alex Krizhevsky** 和 **[[Ilya Sutskever]]** 设计的 **[[AlexNet]]** 采用 **深度[[CNN 卷积神经网络]]** 并使用 **[[GPU]] 训练**,大幅超越了传统方法。
- **AlexNet 主要优势:**
- 采用 **更深层的 CNN**(8 层,相比之前的浅层网络)
- **使用 ReLU 激活函数**,提高训练速度
- **引入 Dropout 技术**,减少过拟合
- **使用 GPU 计算**,加快训练速度
- 其错误率仅 **16.4%**,远低于当时的最佳模型(26.2%)。
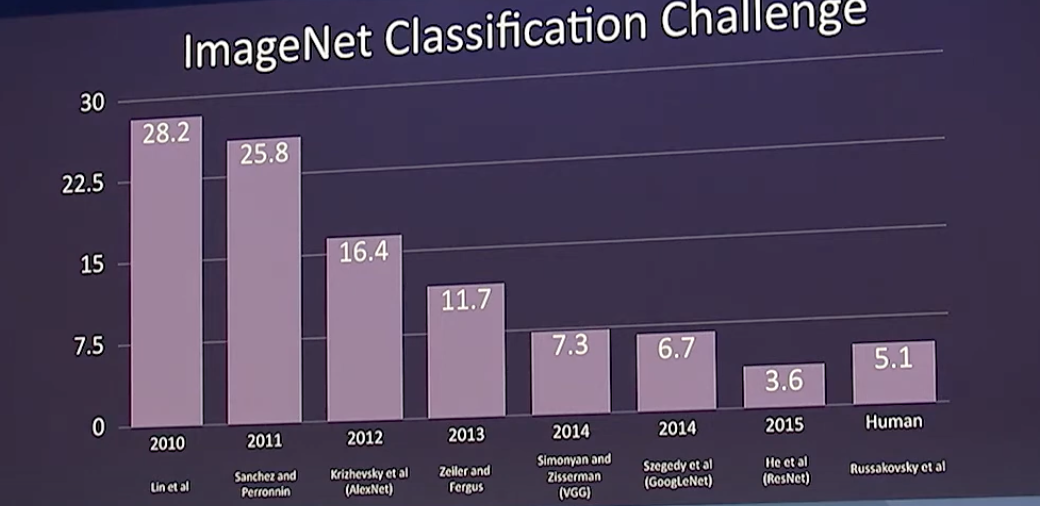
## **5. AlexNet 之后的发展**
- 2013 年:**ZFNet**(Zeiler & Fergus)改进 AlexNet,使用**可视化技术**理解 CNN 的工作机制。
- 2014 年:**VGGNet**(Simonyan & Zisserman)增加 CNN 层数,采用更小的 3x3 卷积核。
- 2014 年:**GoogLeNet (Inception V1)** 引入**模块化设计**,提高计算效率。
- 2015 年:**ResNet**(何恺明团队)提出 **残差网络**,实现 **152 层深度网络**,错误率降至 **3.57%**,超越人类水平。
- 2017 年后:**Transformer、Vision Transformer (ViT)** 开始替代 CNN,在计算机视觉领域取得突破。
## 数据集
训练深度学习神经网络需要大量的数据,数据分为标记数据与未标记数据,[[小猫论文]]使用的是互联网上未标记过的数据,而 ImageNet 使用的是标记过的数据。但不管是哪种数据,它们的源头都是 20 年以来的[[互联网]]基础设施,YouTube,Google,Wikipedia,Reddit,Z-library, Sci-hub, Github, IMDB等等。
## 数据标注是不是一种[[特征工程 Feature Engineering]]?
2. 从狭义的“特征工程”角度看,给图像贴上“这是狗”、“这是猫”、“这是苹果”的标签,**并没有手工去提取“狗耳朵特征”或“猫眼睛特征”等特征[[vector 向量]]**。
3. 这些类别标签只是告诉模型:这张图片整体属于哪个类别。模型还是要在训练过程中**自己从像素中学习具体的特征**。
4. 因此,ImageNet 的标注更接近于“**数据标注(Labeling)”或“数据集构建**”,它本质上是为了提供**训练信号(监督信息)**,而不是直接人工提取特征(如 HOG 特征、SIFT 关键点那样)。
# 参考资料
- [ImageNet-维基百科](https://zh.wikipedia.org/wiki/ImageNet)