# why
# what
- Fineweb 是 hugging face 发布的一个模型训练数据集;
- **查找原始数据**
- 自己爬,像 OpenAI 那样
- 使用第三方已爬网页的仓库,例如 common crawl,一个非营利组织,从 2007 年开始一直在爬去 web
- 拥有 15 万亿 token,44TB 储存空间,96 个 commoncrawl快照;
# how
## 数据过滤步骤
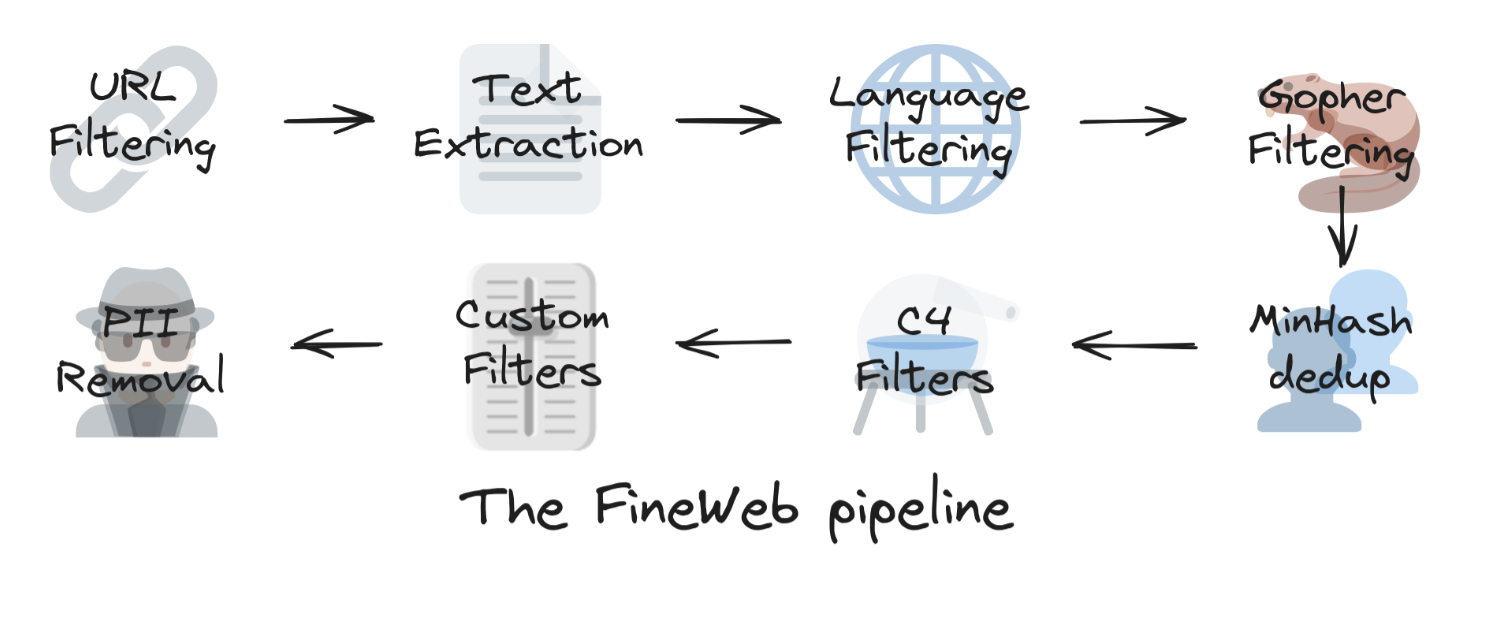
- 文本提取
- commoncrawl 通常有两种数据格式:
- WARC:包含网页的 HTML 和请求元数据
- WET:网站的纯文本(LLM 会使用纯文本),WET 可能会保留太多样板内容和导航栏,需要进一步提取。
- 文本提取是处理数据过程中成本最高的部分。
- 筛选过滤
- 删除部分会降低模型性能的数据
- 删除成人内容
- 仅保留英文文本≥0.65 分数的数据
- 从 MassiveText应用质量和重复过滤器: 指的是对这个数据集进行清洗,通过使用过滤器来移除:
- **质量差的文本**: 例如,包含大量乱码、语法错误、不完整语句的文本。
- **重复的内容**: 例如,完全相同的文本或者非常相似的文本片段。
- 删除重复数据
- Web 有许多聚合器、镜像、模板化页面或分布在不同域和网页上的其他重复内容。有时,当不同的链接指向同一页面时,这些重复的页面甚至可以由爬虫本身引入。
- 删除重复数据集的方法尝试从数据集中识别和删除冗余/重复数据。
- 删除重复项还能提升模型性能,使模型减少这些重复项的 **记忆**,就好像人类,见过次数更多的东西记得更清楚,但如果内容本身不是高质量的,只是重复性高,这会影响模型的性能。
- 减少重复数据能够提高训练的效率,通过更少的训练迭代达到相同的性能水平。
- minhash 删除重复数据
- *但是更多的重复数据删除将不可避免地==导致更高的基准测试分数[[benchmark]]==,因此我们决定仔细研究最古老的转储之一。*
- C4数据集
- 于 2019 年首次发布。它是从 `2019-18` 年 CommonCrawl 转储中获得的,方法是==删除非英语数据==,在行和文档级别应用一些启发式过滤器,在行级别删除重复数据,并从单词阻止列表中删除包含单词的文档。
- 常见的 LLM 训练子集,用于 Llama1 等模型。
- 自定义过滤器
- PII removal
- PII removal 指的是移除个人身份信息(Personally Identifiable Information,简称PII)。PII 包括姓名、地址、电话号码、身份证号、电子邮件地址等能识别个人身份的信息。PII removal 就是把这些敏感信息从文件、数据库或其他记录中删除或隐藏,以保护个人隐私。
# how good
# Ref.
- https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1
-