# videos checklist
- [x] seen?
- [x] note-taking? thinking about it?
- [ ] share?
# why
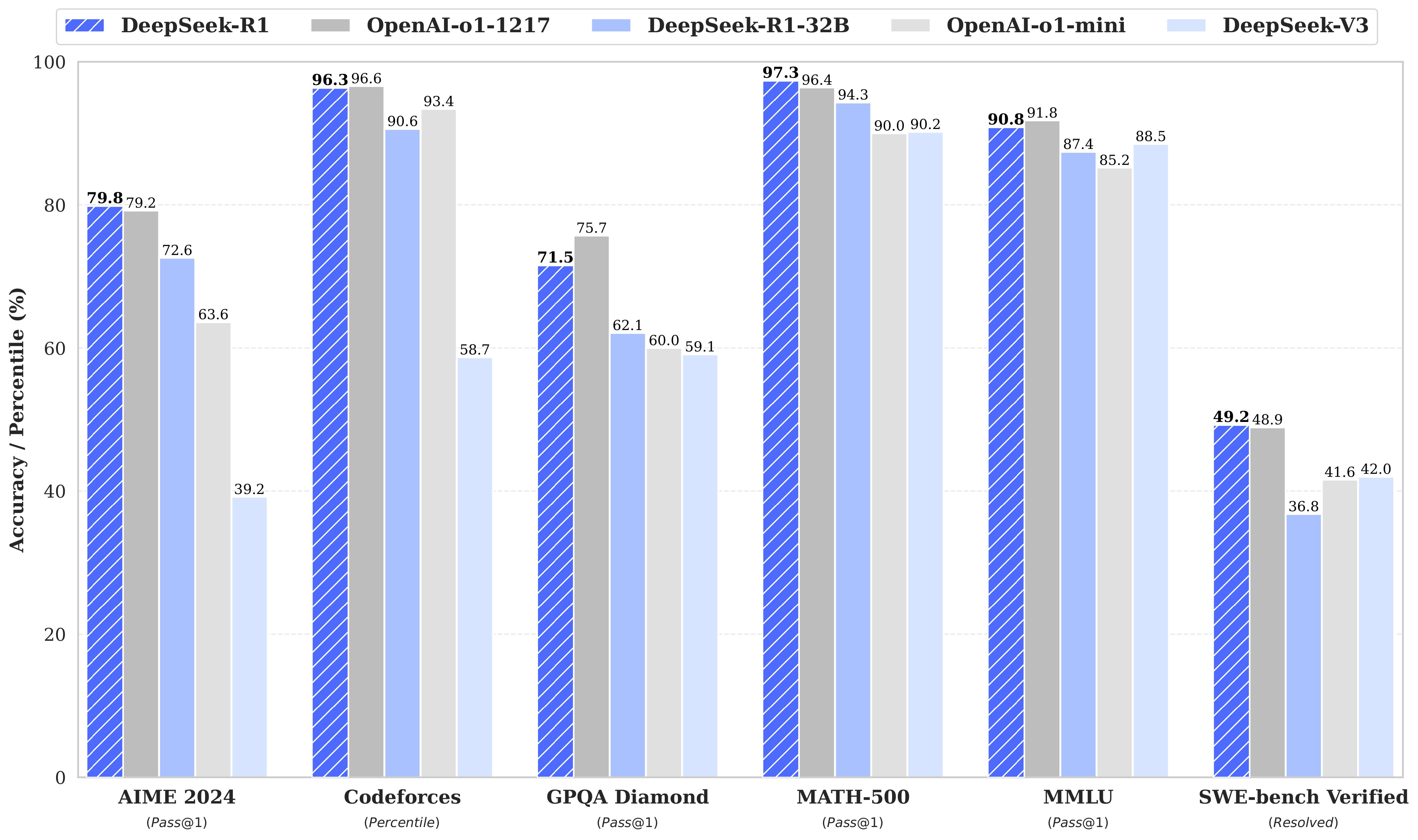
- 在 [[benchmark]] 中吊打满血 o1,却便宜 50 倍,速度快 5 倍。如何做到的?
- 
# what
## 训练过程
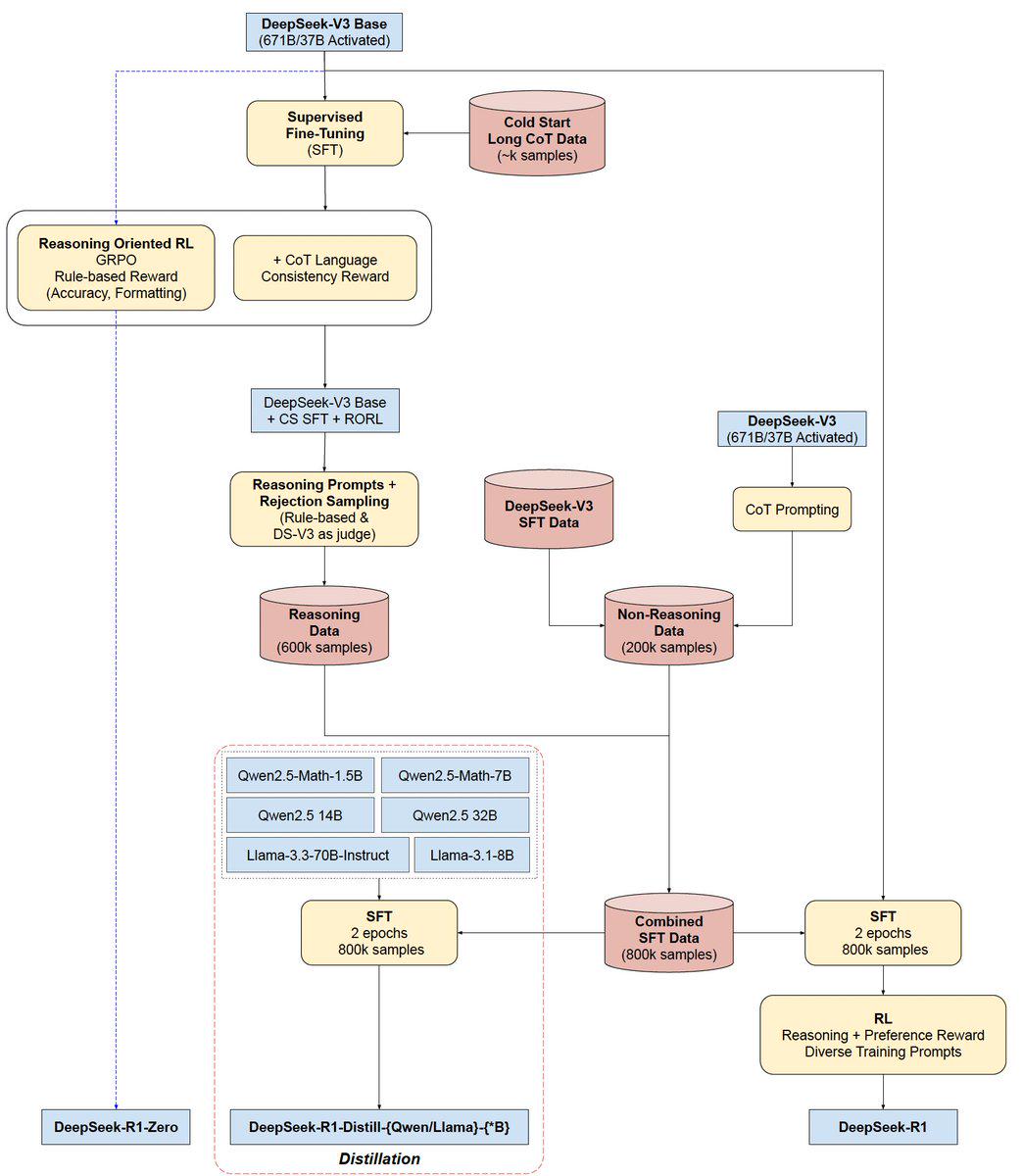
1. **DeepSeek-V3 Base(67B/37B激活)与SFT冷启动**
- 一开始先从DeepSeek-V3 Base出发,使用少量的长CoT(Chain-of-Thought)数据(约数千条)进行**Supervised Fine-Tuning (SFT)**,算是一次“冷启动”的过程。
- 这个阶段的目的是让模型先学会基本的长链式思维(CoT)格式,为后续大规模的推理数据做准备。
2. **推理取向的强化学习 (Reasoning Oriented RL,GRPO)**
- 在冷启动完成后,紧接着会进行一个基于规则的奖励(主要考察推理准确性和输出格式)以及CoT语言一致性的奖励,也就是图中所写的“+ CoT Language Consistency Reward”。
- 通过强化学习把模型在推理场景下的表现进一步提升,并且让它形成统一、清晰的Chain-of-Thought表述风格。
- 这一阶段完成后,就形成了**DeepSeek-V3 Base + CS SFT + RORL**的中间版本,可以理解为已经拥有了相对稳定且高质量的推理能力。
3. **Reasoning数据与拒绝采样(Rejection Sampling)**
- 为了进一步加强模型的推理能力,会用规则和训练好的DeepSeek-V3当作“裁判”去筛选,收集了大约60万条推理数据(Reasoning Data)。
- 同时,还有20万条非推理数据(Non-Reasoning Data),一并汇总到**DeepSeek-V3 SFT Data**里。
- 这样总共就获得了80万条“SFT数据”(Combined SFT Data),包含推理和非推理两种类型。
4. **多模型蒸馏 (Distillation) 与SFT训练**
- 在图的中间区域,可以看到Qwen2.5家族(1.5B/7B/14B/32B)和Llama家族(3.3-70B-Instruct/3.1-8B)等不同大小的模型,都要用这80万条的SFT数据来进行2个epoch的微调(SFT),目的是把DeepSeek-V3的能力“蒸馏”下去。
- 通过这样的多模型蒸馏,可以得到一系列不同规模的**DeepSeek-R1-Distill-{Qwen/Llama}-{*B}**模型,既能保证推理能力,也能兼顾资源消耗。
5. **最终的SFT与强化学习 (RL)**
- 上面得到的“Combined SFT Data”(80万条)还要再进行SFT两轮训练,并且配合**Reasoning + Preference Reward**的RL策略,以及多样化的训练提示(prompts),让模型在输出质量和用户偏好之间找到平衡。
- 这一阶段结束后,就形成了主打的**DeepSeek-R1**版本,可以说是把推理准确性、多样性、以及对话能力都整合到一起的最终成果。
6. **DeepSeek-R1-Zero**
- 图里左下方出现了“DeepSeek-R1-Zero”,看上去像一个 baseline 或最初阶段的版本,也可能是在最小规模上做的初步尝试。最终演进到DeepSeek-R1,功能更完整也更强大。
# how
## 论文解读
- 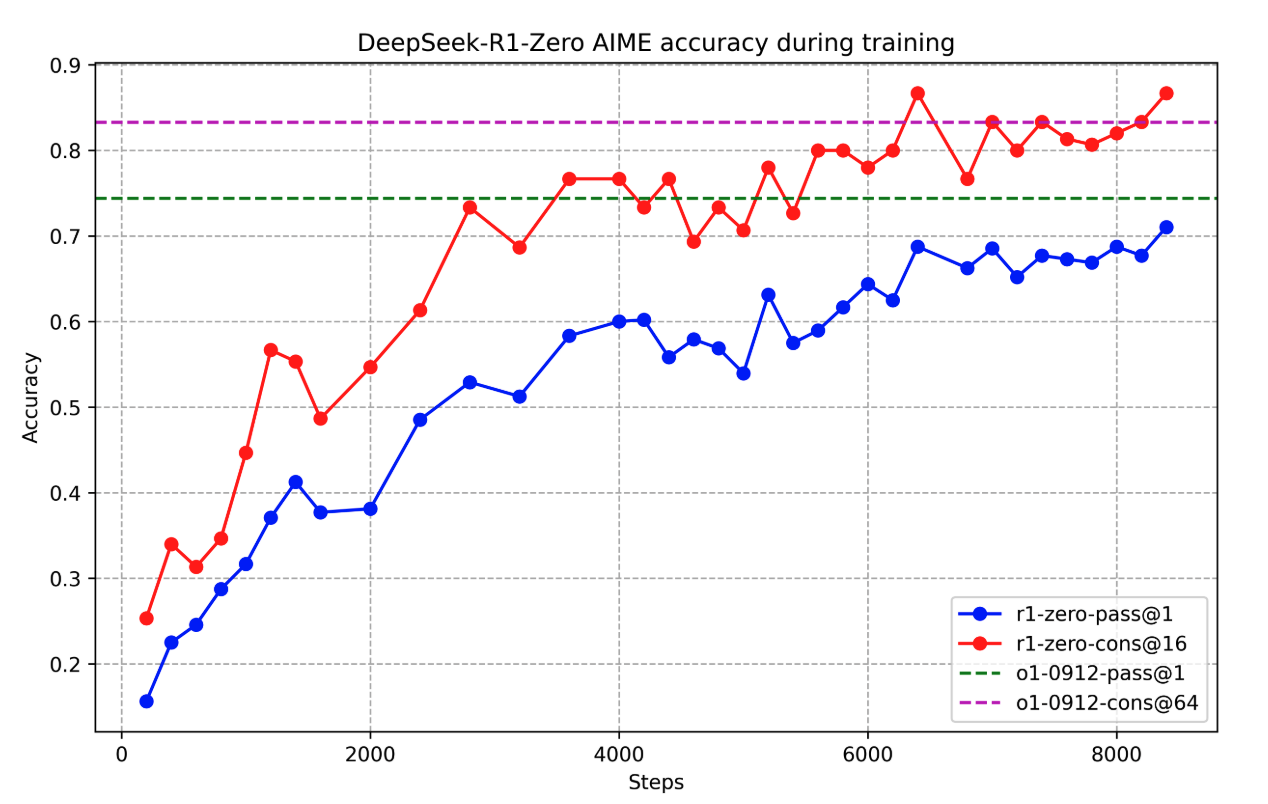
- 从结果来看,模型需要更多的步骤来获得更高的准确度结果
- 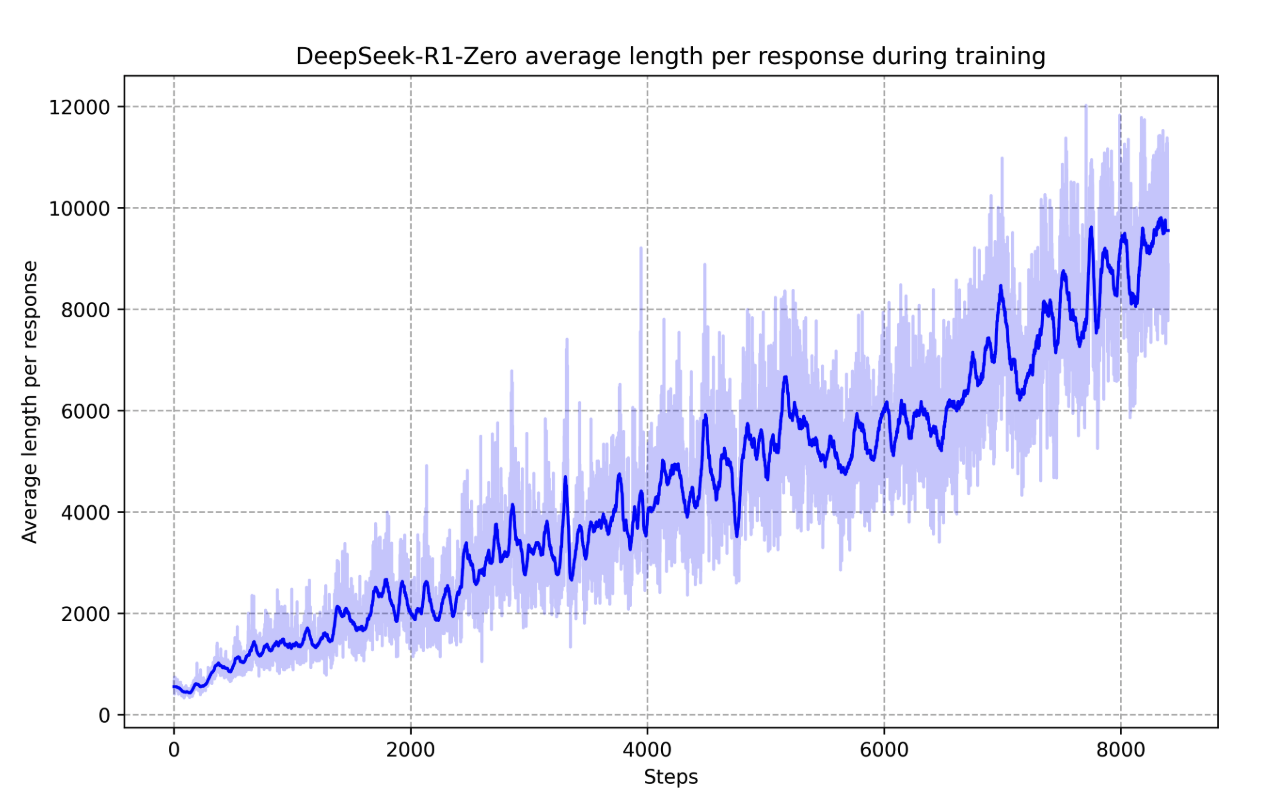
- 步骤越多,平均响应长度越长,意味着使用了更多的token,所以它正在学习创建**非常长的解决方案**,为什么这些解决方案很长,因为模型进行“思考了”
- 
- 模型在创建思维链[[CoT]]的过程,似乎学会了像我们脑子里的思考方式,解题 - 回溯 - 重现构建.....
## 测试实例
- 硬推理能力
- 编程和数学属于硬推理能力,这方面的优势可以交给时间去证明。如果真的超过 o1,会有更多的专业人士使用。
- 软推理能力
- [00:13:03](https://www.youtube.com/watch?v=R26xS9Obo3M&t=783s) 案例1:孩子数学考了38分
- 结果:没有说到问题的本质,即父亲发现孩子不是亲生的
- [00:16:00](https://www.youtube.com/watch?v=R26xS9Obo3M&t=960s) 案例2:把16个单词分为4类
- 分类分对了 2 个
- [00:17:41](https://www.youtube.com/watch?v=R26xS9Obo3M&t=1061s) 案例3:第三个字母是A的国家
- 有一个字母错了
- [00:19:13](https://www.youtube.com/watch?v=R26xS9Obo3M&t=1153s) 案例4:用1颗子弹看守100个犯人
- 大部分正确
- 对于笑话本质的理解与创建
- [00:22:47](https://www.youtube.com/watch?v=R26xS9Obo3M&t=1367s) 案例5:全聚德 vs 肯德基
- R1 没能理解
- [00:24:15](https://www.youtube.com/watch?v=R26xS9Obo3M&t=1455s) 案例6:构思一个恐龙笑话
- llm 编笑话的能力都不太好
- 深度思考
- [00:27:29](https://www.youtube.com/watch?v=R26xS9Obo3M&t=1649s) 案例7:人的agency是什么
- [00:28:49](https://www.youtube.com/watch?v=R26xS9Obo3M&t=1729s) 案例8:信息熵与知识管理
- 一进行深度思考就陷入**动词大词**中?为什么?
# how good
- signal 与 noise
- 不要盲目跟风,要有自己的判断,要抓住问题的原理、逻辑,并且要有有效的证据。
- 测试数据是否说明了模型针对 benchmark 的项目进行过特殊训练,所以性能更强?
# inbox
# todo
# ref.
- [ ] [R1 论文](https://readwise.io/reader/shared/01jk2zvekxjam5cb16yex5nybg)
- [x] [youtube-R1推理模型吊打 o1?](https://readwise.io/reader/shared/01jk30nhknsb8b94mtfv1pk6ne)
# related.
# archive.