- # why
- 解决普通人难以进行的,需要复杂信息和深入思考的**主题研究**问题、个人的研究助理。
- 提升专业人士在主题研究环节的研究效率
- **综合分析**能力:**创造新知的前提**,deep research是实现[[AGI]]5 的重要一步。
- 30 分钟内,完成人类几小时,甚至几天才能完成的工作。
- 人类无法做到的就是 **信息获取、加工处理的算力优势**,deep research 可以在 5-30 分钟内把互联网信息翻个底儿朝天,最强的人类也做不到。
- # what
- ## 官方报告
- release date: February 2, 2025
- ### intro
- 使用**推理**对大量**在线**信息进行综合分析并通过**多步骤**来完成任务的代理。
- 搜索 - 阅读 - 思考 - 分析
- 是 OpenAI 的下一代 **[[AI agent|agent]]智能体**,能够针对复杂任务,独立在互联网上执行多步骤研究。通过查找、分析、综合分析上百个在线资源,创建一份研究分析师级别的报告。
- 底层采用满血 **[[o3]]模型**,该版本对web 浏览和数据分析进行了优化。
- **system prompt**,deep research的行为很简单,只用到两个工具
- 搜索:利用 o3 模型强悍的推理能力,执行(看似非常基础的)搜索、阅读、引用;分析和整合,会根据自己遇到的信息调整按照研究需要来**调整自身的研究计划(pivoting)**。
- Python:数据处理,表格呈现,加工对象是互联网上的文本、图片、PDF 资料;
- ### why we built deep research
- **解决学术领域问题**:金融、科学、政策、工程等领域需要彻底、精确、可靠研究的人
- **解决生活领域的问题**:对选购的物品需要仔细、彻底的研究(如汽车、电器、家具)
- **deep research可以独立发现、推理、整合来自 web 的见解**
- 在真实任务中进行训练,并使用浏览器和 Python 工具
- 使用了与 [[o1]] 相同的强化学习方法[[深度解读“强化微调”,o1模型训练的关键|强化微调]] #todo
- 解决现实中的问题需要具备信息搜索能力,和从资源上下文中整合有效信息的能力,deep research 弥补了 o1 在这方面的不足。
- ### how to use deep research
- 一次研究会运行 5-30 分钟
- 后期会在报告中嵌入图片、数据可视化、其他分析内容
- ### how it works
- 深度研究使用的是[[端到端]]的[[强化学习]],对一系列领域进行 **[[硬浏览]]** 和**推理任务**训练;
- 通过这些训练,模型学会了**规划和执行一个多步骤的轨迹来寻找到需要的数据,并在必要时回溯和响应实时信息。**(例如查看 research 的「活动」会看到一个“搜索-阅读-思考-回溯”的活动过程)
- ### Limitations
- 仍然处于早期阶段,会产生幻觉或做出错误判断
- 主动辨别信息源质量高低、信息真伪,对推理模型来讲这本身不难([[truth-grounding]],事实接地技术)
- 难以区分权威信息和谣言
- 目前的一大局限是无法接入付费资源(数据库、学术期刊)和私人知识库等非公开信息,但这可以解决;
- ### Access
- 计算密集型任务,研究查询所需时间越长,推理计算使用越多,pro 用户每月最多 100 次
- plus、team(1 个月内)
- enterprise
- ### what's next
- 移动端和桌面应用程序(1 个月内)
- 目前使用的信源为开放互联网与上传的文件,未来可以连接更专业的数据源
- 异步、真实世界的研究和执行与[[ChatGPT operator]]组合
- # how
- ## 使用经验总结
- 在提出问题时,用哪个模型都一样,底层都使用 o3 模型。在回答 GPT 对齐的问题时,model picker 才有用。
- 一定要一个月用完 100 次额度,deep research是自 chatgpt之后最有生产力革命性质的战略性技术/工具,值得战略性重视,所以,主观直接第一手经验的积累至关重要;(与降智斗智斗勇)
- **研究报告的最佳阅读方式**:剪藏到 Readwise reader或使用chrome 插件(chatgpt to markdown)导出为 markdown 文件,然后用 typora 或 pandoc 转换为epub 或 pdf(带 link,格式不乱),然后导入微信读书或 readwise reader 边读边划线,阅读 5678 遍;
- 暴论:2025 聚焦于阅读 AI 生成的内容。
- 什么情况下用哪种搜索模型: [[SearchGPT]]
- 每月限额并非以自然月份划分,而是以你升级会员的具体日期划分;(我是 2.7 付款的,才 20 天不到就降智了)
- 报告生成后,你可以在原始对话中继续提出新的研究需求,模型会保持对之前研究的记忆,但本质上是一次新的研究(不会在原始报告上修改,会重新生成新的研究报告);
- deep research 对参考文献的引用,精确到“行”。
- 最适合做**读书的主题研究**搭配。
- 对齐需求阶段使用的不是 o3 模型,而是你在 model picker(模型选项卡)里面选择的模型;一般情况下,建议你选择 o1 模型,其次是 gpt-4o 模型;实际差异不大,因为正式研究都是o3 模型,而在理解需求这种简单任务上区别不大
- ## 万能prompt模板
- <研究背景/context> :背景信息,我为什么要做这个研究
- <研究需求/goals> :研究主题,研究目标,需要注意的地方;这个研究是什么,关注什么;
- <通用要求/requirements> :
- 1、使用英文搜索,只采纳英文资料(因为互联网上英文资料在数量和质量上都是最好的),用中文撰写报告。
- 如果你研究的主题只有中文资料,你或许应该限定模型只用中文关键词搜索,只采纳中文资料
- 2、请解读足够细致深入,字数无上限,一切以深入全面解读为基本目标。(希望你拿出专业分析师的水准。)Your suppose to invoke the deep research function
- 3、包含但不限于 Wikipedia、相关书籍、学术和科普期刊网站、权威媒体和杂志刊物的网站;
- 4、视觉化,请按需在研究报告中采用图表和可视化媒介,来辅助促进理解;
- 可以上传指定文件
- **读书解读 prompt**
- 我希望你针对《xxx》这本书进行一次深入、全面的研究与分析,帮我撰写一份高质量的书籍深度解读报告。
- **研究目标** 请确保报告涵盖以下内容:
- 书籍的核心主题、关键观点和理论框架的全面总结;
- 每个重要观点和理论的详细解释,包括作者提出这些观点的背景、意图及其理论意义;
- 对书中涉及的重要案例、事例或研究进行深入分析,并用具体、生动的例子帮助我深入理解;
- 作者观点的实际应用价值,包括在现实生活或专业领域中的启示和具体可实践的建议;
- 对书籍整体的结构、逻辑和论述风格进行分析与评价;
- 请确保报告条理清晰、逻辑严密,同时在必要之处使用适当的引用或原文摘录,以便我能够快速掌握书籍的精髓,达到深入理解与应用的目的;
- **通用要求(general requirements)**
- **语言选择** 使用英文搜索,只采纳英文资料(因为互联网上英文资料在数量和质量上都是最好的),用中文撰写报告。
- **读者对象** 本报告面向普通读者(自我提升、终身学习、思维训练),并非面向学术研究;但内容上不排斥必要的学术概念和理论,一切以全面深入理解为标准;
- **报告长度** 请解读足够细致深入,长度不封顶,一切以深入全面解读为基本目标。
- **参考资料** 请参考Wikipedia、相关书籍、学术和科普期刊网站、权威媒体和杂志刊物的网站;优先选择权威信息源;
- **可视化** 请按需在研究报告中采用图表和可视化媒介,来辅助促进理解;
- [[deep research prompt 书籍分析]]
- [[deep research prompt 电影分析]]
- [[Deep Research 翻译]]
- [[deep research 写作]]
- [[meta prompt:主题研究]]
- ## 官方测试
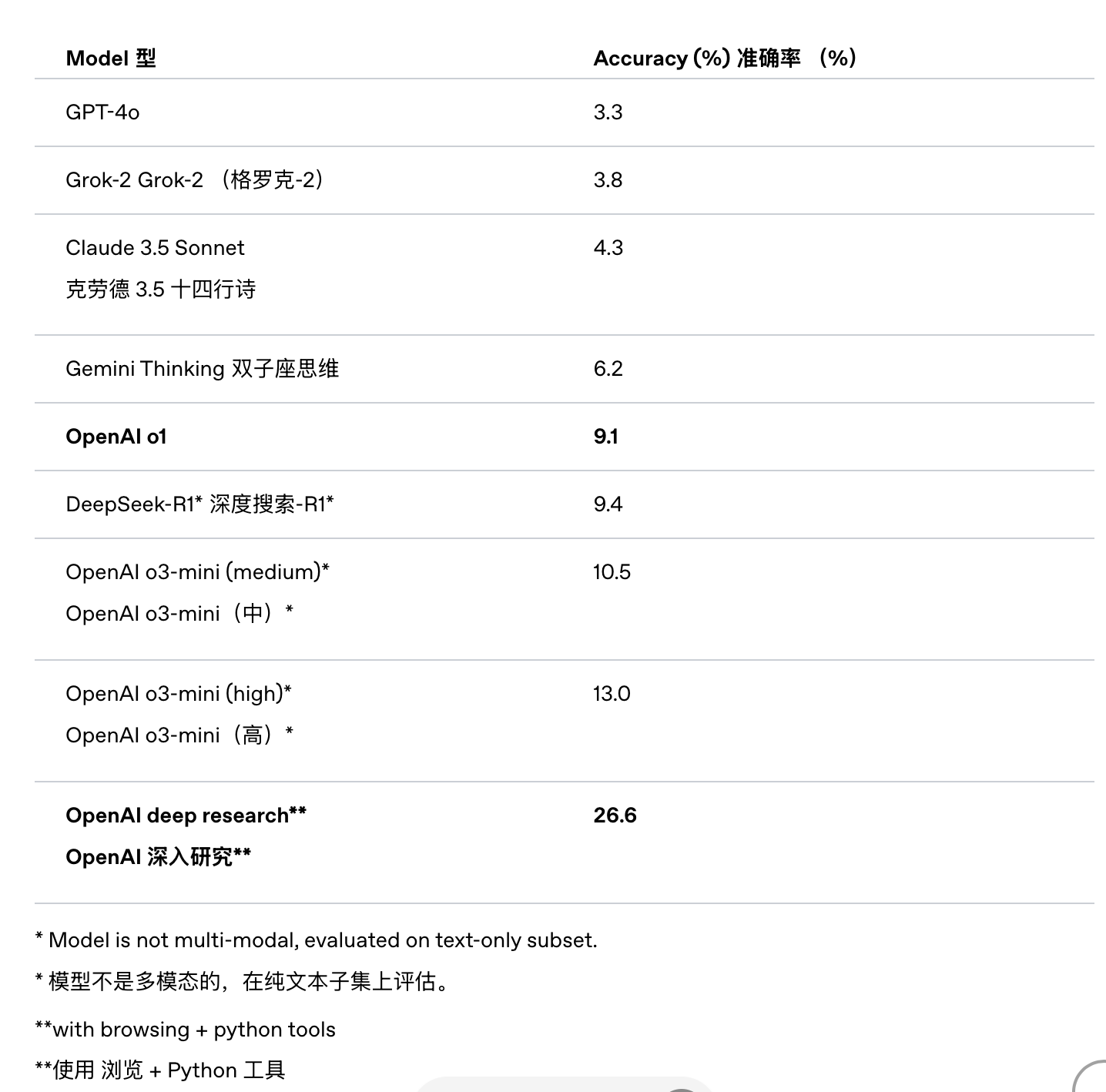
- [[HLE]] 人类最后的考试
- 
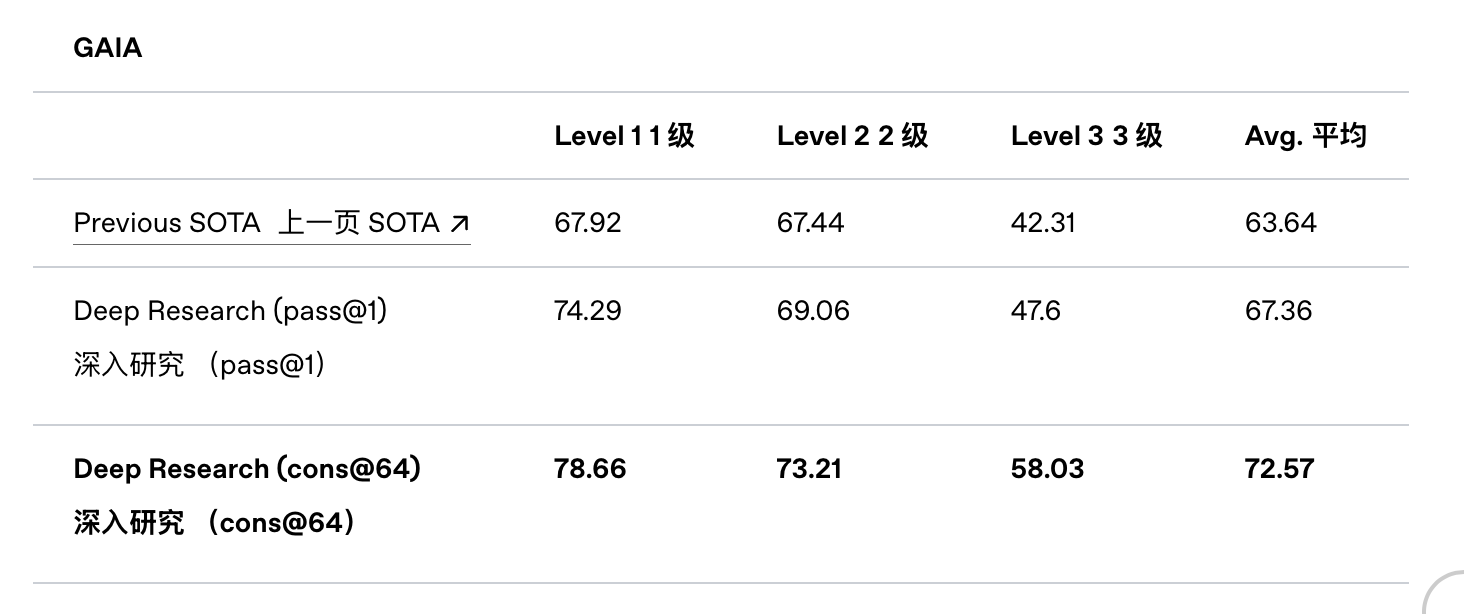
- [[GAIA]]
- 
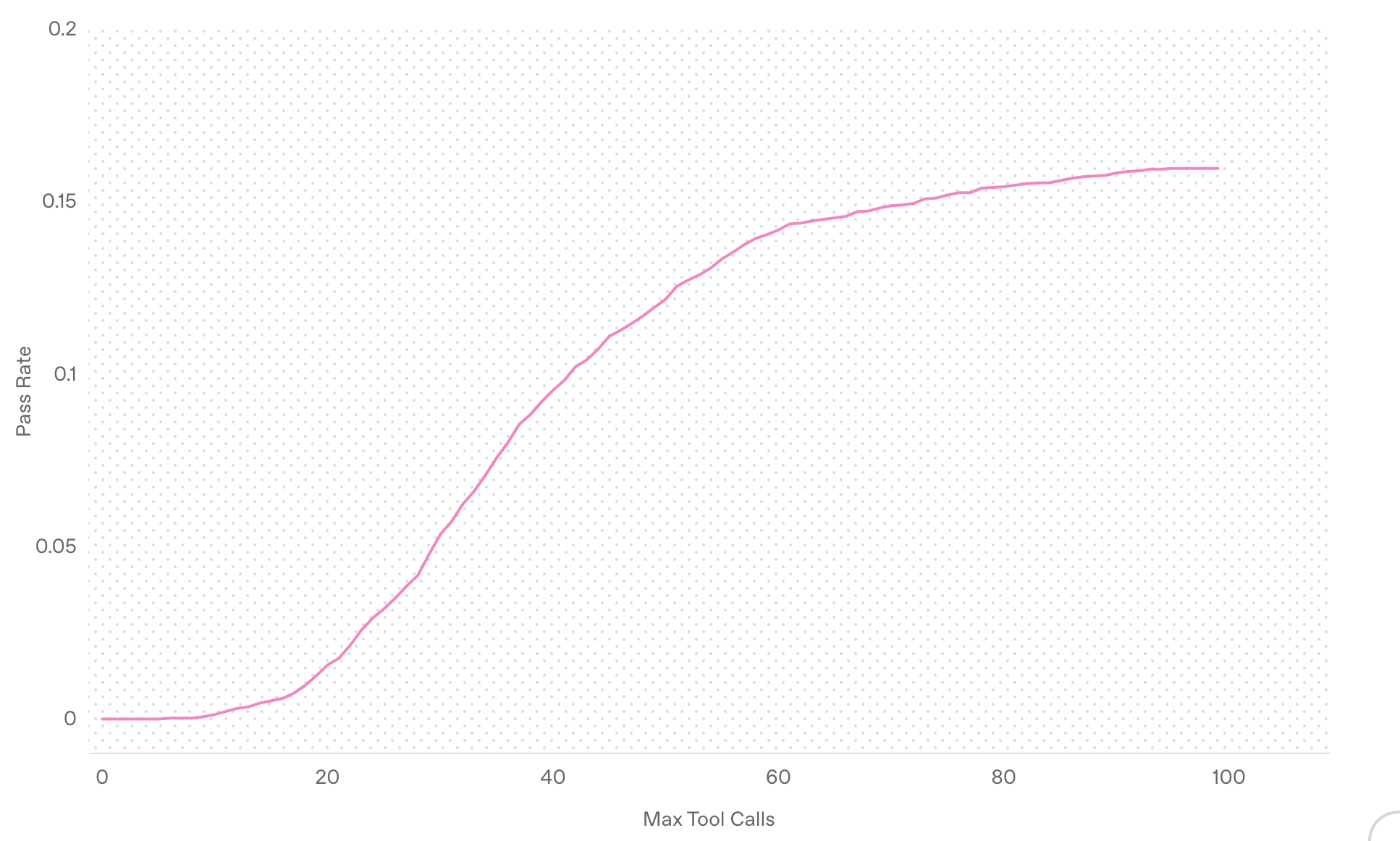
- 专家及任务
- 图片表面模型浏览和思考的内容越多,表现就越好,更多的时间思考对于模型来说很重要
- 
- 与人类专家自主做研究的时间对比
- 化学:节省了4 小时
- 语言学:节省了 5 小时
- 医疗学:节省了 2 小时
- ## 和[[Google Gemini with Deep Research]]对比
- 如果对研究的主题不需要深入,只需要广度就可以用 Google。背后原理是因为Google 的上下文长度只有 64k
- 重度依赖信息搜集,尤其是中文,英文差距不大。背后原理基于底层搜索引擎,openai 用的是 bing,不如Google search
- 指令跟随 instructiong following要求不那么高
- ## [[deep research 测试案例]]
- [[如何做读书笔记]]:原文阅读+报告阅读=节省生命时间一大截
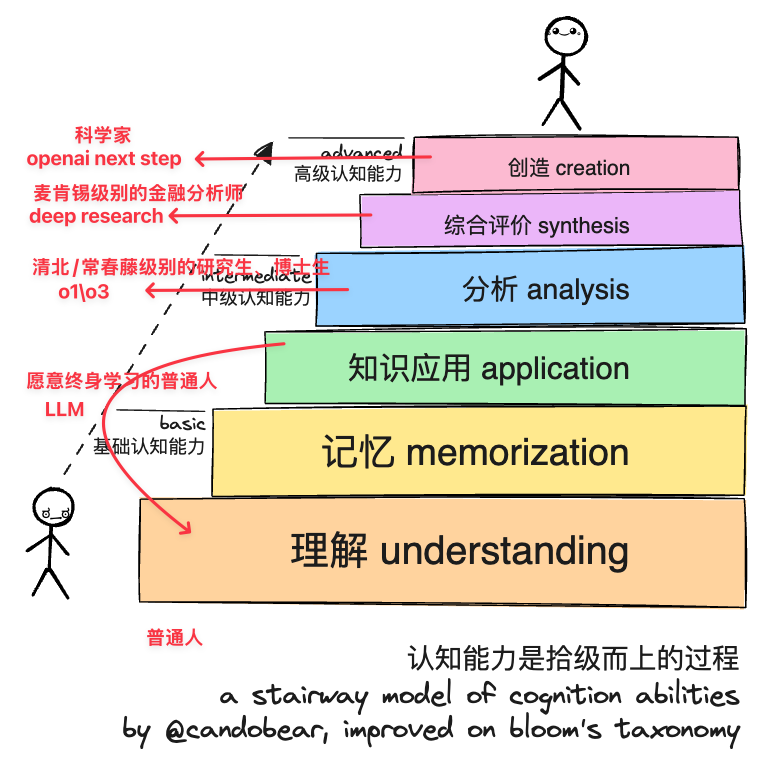
- # how good
- 
- # Ref.
- 知识视频:[[OpenAI Deep Research,让普通人一下变强好几倍的的主题研究 Agent!|深度测评、分析与使用教程]]
- [YouTube 直播](https://readwise.io/reader/shared/01jkerpav0y0y17ca8bm0d7mtd)
- [OpenAI blog - Introducing deep research | OpenAI](https://readwise.io/reader/shared/01jk5r439xg2pfkdpkxk1tpxkj)
- [Deep Research not working with O1 Pro?](https://community.openai.com/t/deep-research-not-working-with-o1-pro/1111868/22)
- [我一个月内用了100 次deep research,全部经验一次性分享|万能 prompt、深度经验、报告下载](https://readwise.io/reader/shared/01jn0917qcve2zrk0pywsjag0v)
- [candobear deep research研究报告](https://gpt.candobear.com/courses/kv2510-openai-deep-research?__readwiseLocation=)
- [什么情况下,20美金的google可以吊打200美金的openai?| deep research 研究](https://readwise.io/reader/shared/01jrq6k1kqd72e4mxaedxsef8b)