# why
# what
- **基础研究**:AI、机器学习、[[NLP 自然语言处理]]
- 人工智能、机器学习、自然语言处理等领域的基础理论研究
- 研究如何让计算机更好地理解和生成自然语言,或是如何构建和训练大型神经网络模型
- 1956 年 AI 学科诞生, AI 研究者用几十年的努力,建立了AI 学科,提出了一系列 AI 理论,从[[感知机]]到神经网络,还发展出CNN、RNN 等一系列神经网络算法
- [[Transformer]]
- **应用研究**:技术研究,GPT大模型
- why
- 在这个阶段,研究者将基础研究的理论应用于解决特定问题。OpenAI在成立时的定位,是一个立志于进行 **AGI** 基础研究的小小实验室。[[LLM 大语言模型]]是 OpenAI 选择的实现 AGI 的技术路线。应用研究是在力求“有用”的基础上解决问题,打造更高的技术方案。
- how
- 如何利用自然语言处理技术来提高聊天机器人的回答质量。这包括选择合适的模型架构、数据处理和训练技术等,旨在实现特定的功能或改善性能。
- what
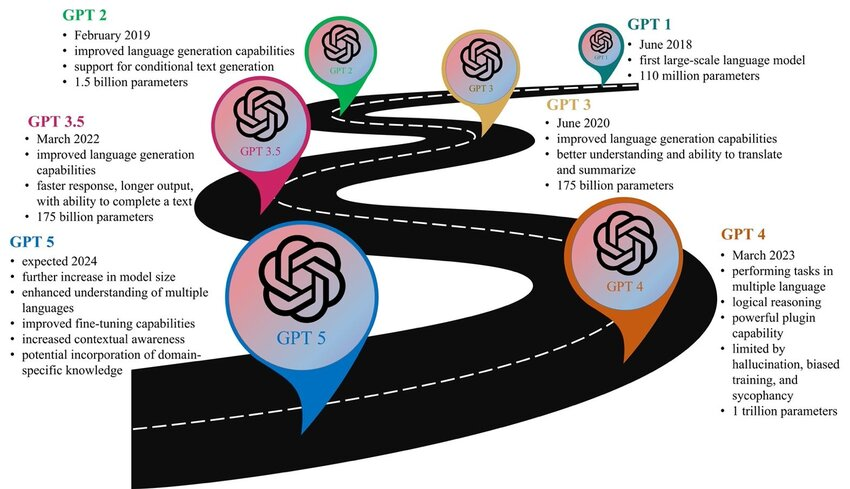
- 2018 年 6 月,OpenAI 发布了 GPT-1 模型,这是第一个大语言模型,参数“高达”1.1 亿。
- 2019 年 2 月,GPT-2 模型发布,提升了语言生成能力,支持了特定条件下的语言生成,模型参数也扩大了 10 倍,来到 15 亿级别。
- 2020 年 6 月,GPT-3 模型发布,继续提升语言生成能力,参数模型扩大 了 100 倍,高达 1750 亿,相应的,GPT在语言理解、翻译、总结等任务上迎来突破。
- 2023 年3 月,GPT-4 模型发布,这时OpenAI 已经不公布具体技术细节了,但估计参数量在 1.7 万亿左右。模型能力也真正达到了AGI级别,在文本生成、编程、知识等一系列任务上取得让人震惊的表现。
- 2024 年,OpenAI 会发布GPT-5 模型,根据Sam Altman 等人透露的零星消息,GPT 模型的能力又将继续迎来巨大突破。
- 
- **开发研究**:App,chatGPT
- 这一阶段专注于将应用研究的成果转化为实际的产品或服务。对于 ChatGPT 来说,这包括集成和优化模型以适应商业应用的需求,如提高响应速度、用户界面设计、确保安全性和隐私保护等,最终使产品能够满足市场和用户的需求。
- 对比
- 北京智源人工智能研究院:用GPT模型x10倍
- 一年时间几百个模型,都是基于开源模型,做点微调,做个app,宣传营销收钱
# how
# how good
- OpenAI在创立之初,所有人都不知道要做什么,初创的 10 个人一起聚在 Greg 的公寓中,在白板上写下要解决的问题:
- “训练一个大型的无监督模型,然后解决强化学习问题”,非常具体
- **connecting the dots**
- 2018 年的 GPT-1 和 2019 年的 GPT-2,确立了语言模型的范式;
- 2020 年的 GPT-3,确认了规模法则(scaling law)是有效的;
- 2023 年的 GPT-4,收获了复杂系统的智能涌现。
- **对人类学习的启发**
- 路线方针:训练自己的大模型?vs 教培路线
- [[规模法则 scaling laws]]:
- 规模法则就是“大力出奇迹”,10 年的刻意练习,20 万知识砖块,一定可以成为专家。
- GPT 时刻:高光时刻需要脚踏实地地持续积累
# Ref.
- [1.7 个人知识树的关键,在“研究”二字](https://readwise.io/reader/shared/01jcps6sf4q1wb9q99qhsq3yzx)
- https://zh.wikipedia.org/wiki/ChatGPT
- [890 samaltman访谈:how to build the future](https://readwise.io/reader/shared/01jchcrsjk241nfpvdmyj408bk)
- [3.7 TIL 笔记:日拱一卒的终身学习笔记](https://readwise.io/reader/shared/01jem79rqmfvzb0rjdpxwf7ka2)
# todo
- [ ] [[GPT的发展过程]]