- Objective: 图像识别
- Breadcrumb: 计算机视觉 - 视觉网络
# 概念阐释
卷积神经网络(Convolutional Neural Network,简称 CNN)是基于[[Backpropagation 反向传播算法]]和受动物的**视觉皮质构造**启发(卷积)而发展起来的一种用于处理图像识别的深度学习模型。由[[Geoffrey Hinton 辛顿]]和[[Yann LeCun 杨立昆]]在 1998 年提出。
## 结构特点:
1. **卷积层 convolutional layer**:通过卷积操作提取输入数据特征。
2. **池化层 pooling layer**:对卷积层输出的特征图进行降采样,减小数据维度,同时保留重要信息。常见的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。
3. **全连接层 Fully Connected Layer**:所有神经元与前一层的所有神经元相连,用于对提取到的特征进行分类或回归任务。
### 卷积层
卷积层就像是大脑中处理视觉部分的视觉皮质一样,视觉皮质的不同部分处理眼睛捕捉到的不同部分的光。卷积神经网络也是将图片分割成不同的小方块,并分别分析每一个方块。在这些方块中找到小图案,然后这些信息通过人造神经网络构建成完整的图案。
- 第一层:卷积相当于一个滑动滤波器,一个滤波器为 3x3 的小方块,在图像中滑动的过程中提取特征。在一个卷积网络中会有多个滤波器,每个滤波器都会寻找不同的图像形状或特征。

- 第二层:随着更加“深入”神经网络,滤波器越来越具备“抽象 abstract”能力。例如可识别一个房子中的窗、门、屋顶的形状。

- 最顶层:层级越深,抽象能力越强,最终可以识别整张图像。


# 实例
- 图形识别和分类(OCR 图像识别)
- 目标检查(面部检测)
- [[NLP 自然语言处理]]中的序列建模
- [[AlexNet]]
# 相关内容
## 卷积的基本概念
### 数学定义
简单来说,**卷积**就是用一个小的“滤波器”(通常叫做卷积核)在输入数据(比如图像)上滑动,**通过加权平均的方式**从输入数据中提取信息。
- **滤波器**:是一个小矩阵,通常尺寸比输入数据小。例如,一个 3x3 的卷积核。
- **加权平均**:在卷积的过程中,卷积核和输入数据的某个区域(局部区域)进行元素逐个相乘后相加,得到一个新的值。这个过程会“滑动”整个输入数据,生成新的特征图。
### 形象比方
你可以把卷积想象成一个“放大镜”在图片上滑动,并且“放大镜”上有一层筛网,筛网的每个网格可以记录和计算局部区域的特征。每当“放大镜”移动到一个新区域时,筛网会根据当前区域的信息(像素值)做一次计算,输出一个新的特征。
举个例子,你想要识别一张图像中的边缘。你可以用一个简单的卷积核,它会重点关注图像的变化区域。例如,如果你给它一个图像,它通过卷积操作能捕捉到图像中亮度变化较大的地方(边缘)。随着卷积操作的进行,图像中的不同特征(如角落、纹理等)会被捕捉到。
## 重要概念与迭代
- 杨立昆的卷积神经网络是福岛邦彦最初提出的 CNN 的一种变体,福岛邦彦使用的是监督学习和无监督学习算法,杨立昆使用反向传播算法替代。
- **filter 滤波器**:滤波器也成为卷积核(kernel),之所以叫做卷积convolutional是因为过滤器执行了一个数学操作叫做卷积。卷积是两个函数通过积分或求和计算得到的第三个函数,表示一个函数对另一个函数的影响。具体来说,卷积操作通过将一个函数(滤波器)应用于另一个函数(输入数据)来提取特征。
- **[[pooling 池化]]**:简化数据,减少计算量和防止过拟合。
- [[activation function 激活函数]]:Sigmoid 输出函数被线性整流函数 ReLUs 取代。
- **分类**:最顶层的单元被送进分类层,与其中所有分类单元连接,采用[[Backpropagation 反向传播算法|反向传播误差]]训练模型对图像进行分类。
- **增益归一化**:
## 卷积网络与视觉皮层
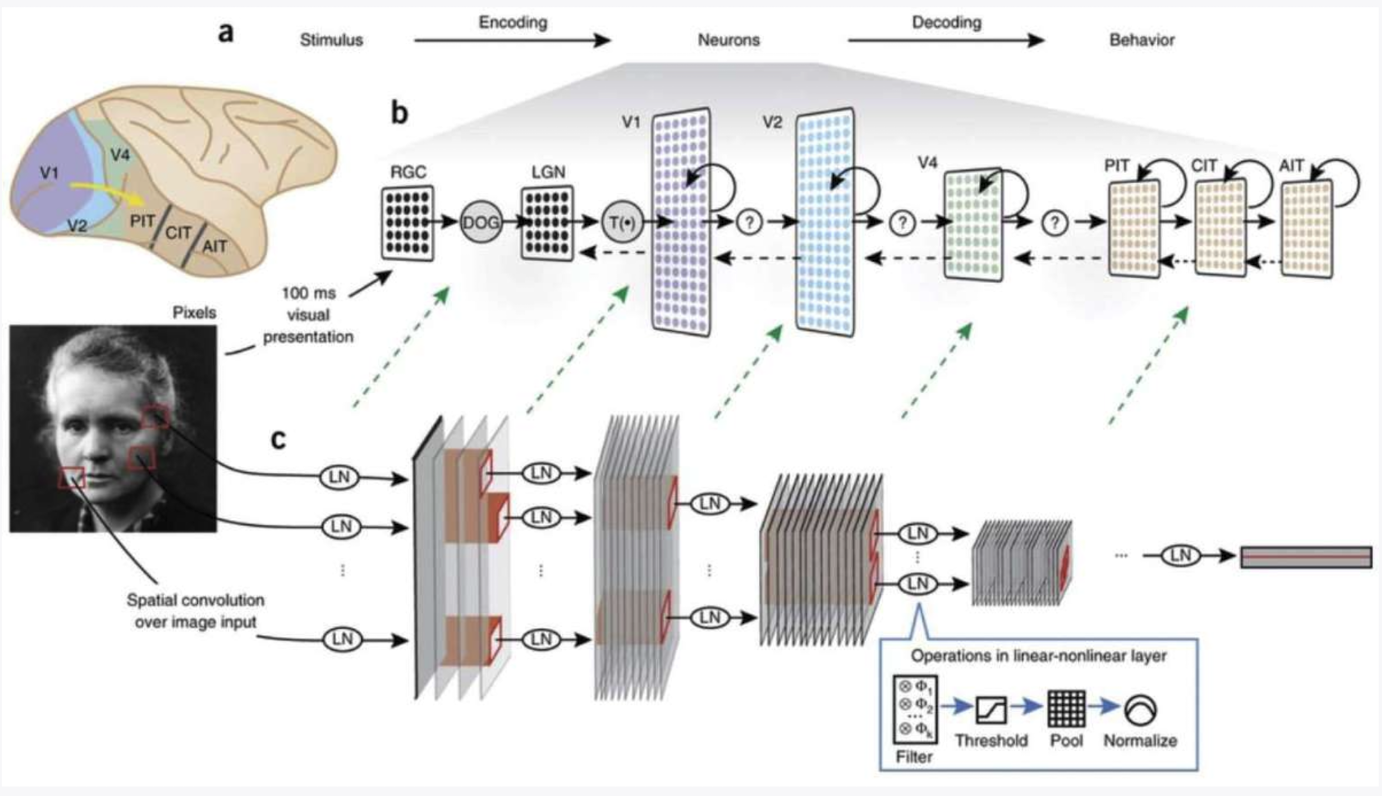
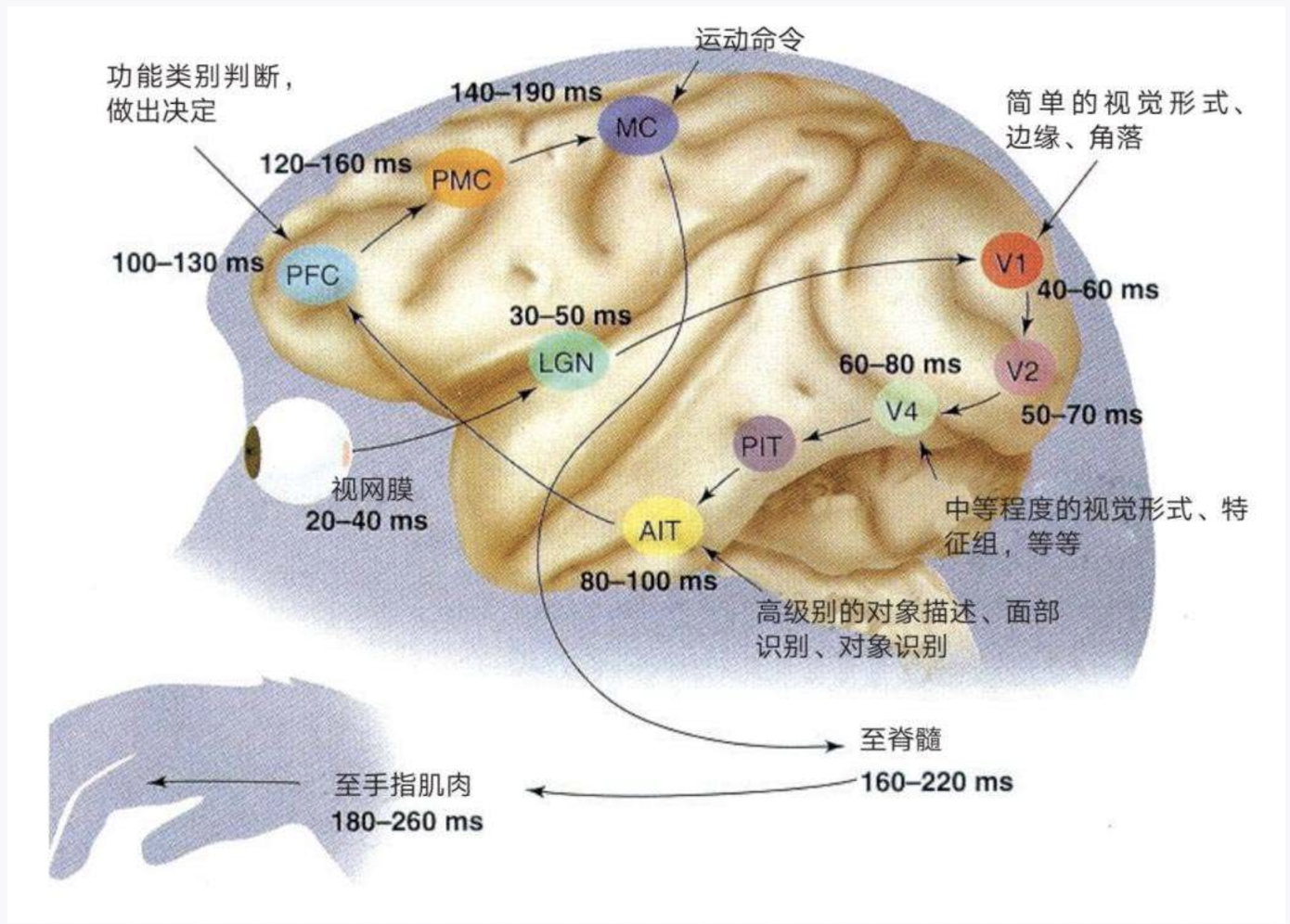
1. **视网膜 (Retina)**:视觉处理的起点,光线在这里被转化为神经信号。处理时间为 **20-40 毫秒**。
2. **LGN (外侧膝状体)**:接收来自视网膜的视觉信息并进行处理的丘脑部分。处理时间为 **30-50 毫秒**。
3. **V1 (初级视觉皮层)**:皮层处理视觉信息的第一个阶段,==处理简单的视觉特征,如边缘和角度==。处理时间为 **40-60 毫秒**。
4. **V2**:处理更复杂的特征,如==轮廓和纹理==。这个阶段的处理时间为 **50-70 毫秒**。
5. **V4**:进一步处理视觉信息,涉及==颜色和形状==。处理时间为 **60-80 毫秒**。
6. **PIT (后下颞皮层)**:参与高级别的物体识别。处理时间为 **60-80 毫秒**。
7. **AIT (前下颞皮层)**:处理更==复杂的物体识别==任务和面部识别。处理时间为 **80-100 毫秒**。
8. **PFC (前额叶皮层)**:负责==决策和功能分类==。处理时间为 **100-130 毫秒**。
9. **PMC (运动前区)**:参与运动的计划。处理时间为 **120-160 毫秒**。
10. **MC (运动皮层)**:==发送运动命令以执行动作==。这个过程的时间为 **140-190 毫秒**。
11. **至脊髓 (Spinal Cord)**:信号传达到脊髓的时间为 **160-220 毫秒**。
12. **至手指肌肉 (To Finger Muscles)**:最终信号到达肌肉,导致动作,所需时间为 **180-260 毫秒**。
# 参考资料
- [CNN 工作原理 - GPT](https://chatgpt.com/share/588d9ad4-9319-4268-bc23-43dd4128f7f6)
- [CNN - 维基百科](https://zh.wikipedia.org/wiki/卷积神经网络)
- [What are CNNs - youtube](https://readwise.io/reader/shared/01j04ya2m6p6s5yhvwk925g301)
- 《深度学习》谢诺夫斯基 05-p76-77、09-p158
- 《深度学习革命》p40
- [李飞飞 GIF‘17 演讲](https://youtu.be/bS9fdzPMmSA?si=WMoayQkOY7hVBSfp)
- [福岛邦彦 - 维基百科](https://en.wikipedia.org/wiki/Kunihiko_Fukushima)
- [算法与结构的区别](https://chatgpt.com/share/b051d5ae-8bd4-4605-b02b-6d9dc77bc3f7)