# videos checklist
- [x] seen?
- [x] note-taking? thinking about it?
- [x] share?
# why
# what
- Timestamps: [0:00](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7)
- - Recap on embeddings [1:39](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=99s)
- 词转换成 token 再转换成向量,嵌入到一个高维的语义空间中,每一个token 的生成都是一次语义空间中的运动。不仅是词的语义,模型还会根据上下文来调整语义。
- - Motivating examples [4:29](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=269s)
- attention 应该做什么?
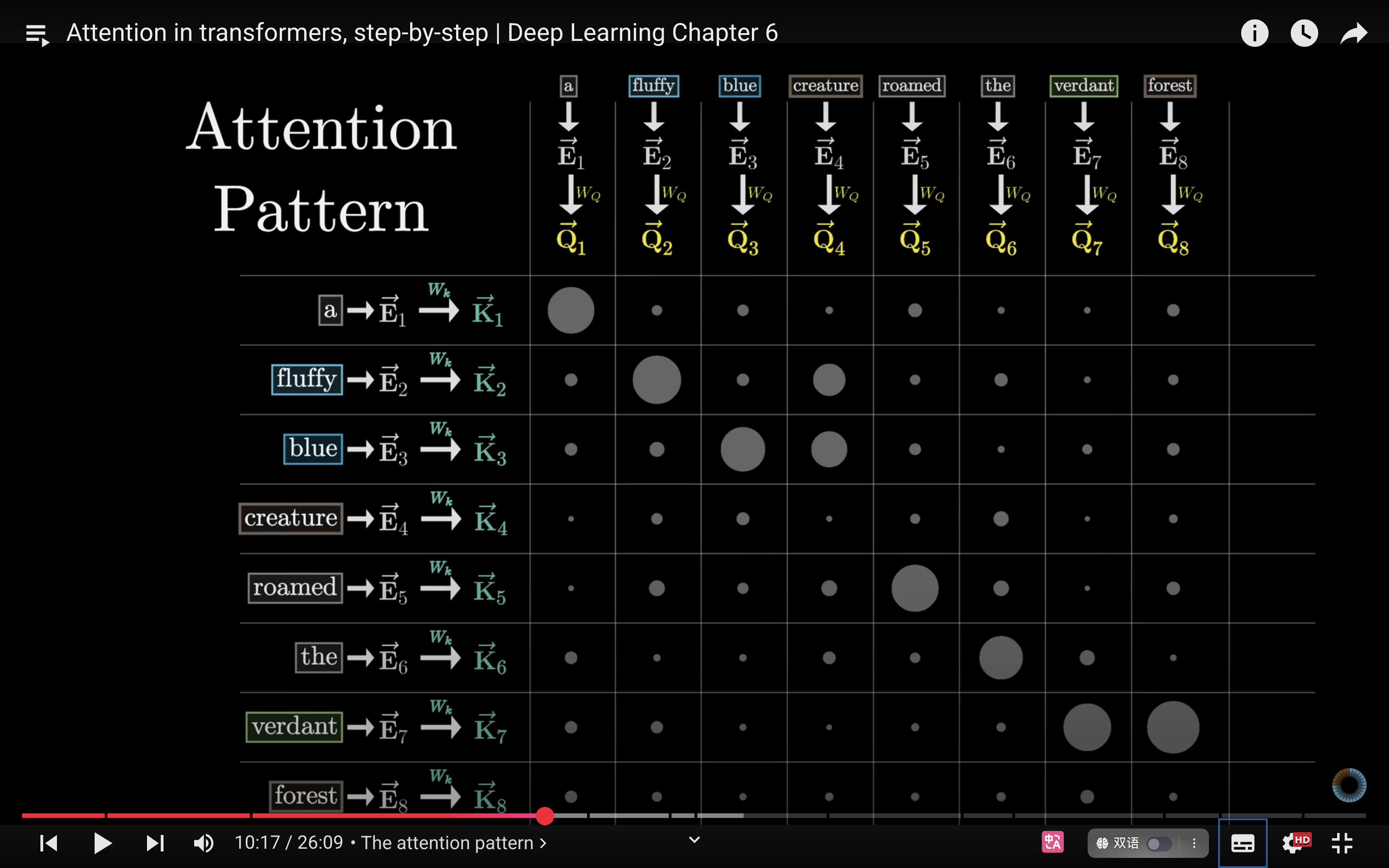
- - The attention pattern [11:08](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=668s)
- [[Attention in transformers, step-by-step]]
- 
- - Masking [12:42](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=762s)
- transformer 的高效之处在于永远都是根据上一个 token,预测下一个 token,所以你永远不希望后面的 token 去影响前面的 token,所以,我们希望 attention pattern 中的这些点为零。但又不能直接设置为零,这样的话想加就不能为 1 了
- 因此,需要把这些条目设置为无穷大,在应用了 softmax 之后就会变为零,但保持 normalized 归一化。
- - Context size [13:10](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=790s)
- attention pattern的大小是上下文大小的**平方**。所以 **上下文长度对于模型的理解力是非常重要的**,因此近年来的大模型为了扩大上下文窗口,也做了很多迭代。
- 
- - Values [15:44](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=944s)
- attention pattern 决定了哪些词语哪些词的相关性
- value:现在需要实际**更新嵌入**,允许单词将信息传递给与其相关的其他单词
- [[Transformer 模型中的注意力机制 - 3b1b视频DL6]]
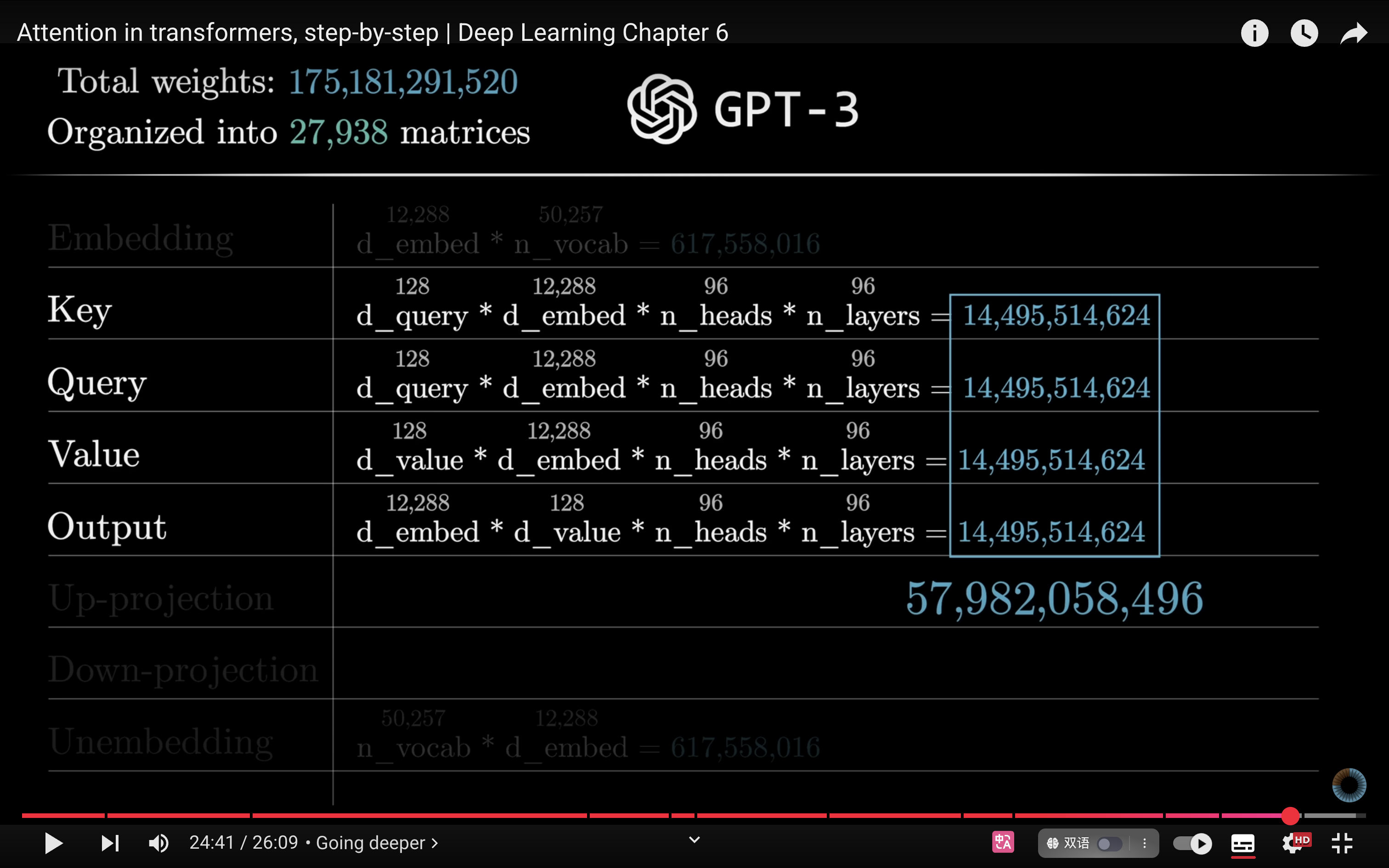
- - Counting parameters [18:21](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=1101s)
- 值矩阵将是一个 12,288 × 12,288 的方阵,因为它的==输入和输出都在这个巨大的嵌入空间中==。那就意味着要增加大约 1.5 亿个参数。更高效的做法是让值映射的参数数量与键和查询矩阵的参数数量保持相同水平。并行运行多个注意力头的设置下尤为重要。具体做法是将值映射分解为两个更小的矩阵的乘积(V vector和 V output)。在概念上,我仍建议你将其视为一个整体的**线性映射** —— 其输入和输出都位于这个大型嵌入空间中。例如,==它可以把单词 “blue” 的嵌入映射到一个“蓝色”方向上,然后将该方向添加到名词的嵌入中。只不过,这个映射被拆分成了两个独立的步骤来实现。==用线性代数的术语来说,我们实际上是将整个值映射约束为一个**低秩 (low-rank) 变换**。
- 1. 为什么值矩阵会是一个12,288 × 12,288 的方阵? 2. 什么是线性映射 linear map? 3. 什么是低秩 (low-rank) 变换? 4. 整体思路是不是将 v vector 的移动分成了两个部分来完成,为了提升模型的运行效率?
- 为什么 **V** 值矩阵「理论上」是 12 288 × 12 288?
- **背景尺寸**
- GPT-3 的隐藏/嵌入维度 _dmodel_ = 12 288。
- 如果我们**不做任何瓶颈**,那么 **V** 要把一个 _dmodel_ 维向量(词嵌入)映到同样大小的输出向量,再加回去。
- 因此最直接的设计是:**参数量 = 12 288² ≈ 1.51 × 10⁸。** 这一个头就 1.5 亿!再乘 96 个头,简直要把显存烧穿——我个人认为这完全不划算。
- 什么是 **[[线性映射 (linear map)]]**?
- 在线性代数里,一个变换 _f_ 如果满足
- $f(x+y)=f(x)+f(y),f(c x)=c f(x)$ 就叫线性。
- **[[矩阵向量乘法]]**是最典型的线性映射:$y=A x$
- $A$ 决定了“把向量 x ==搬到哪里去==”。
- 在注意力里,**V** 矩阵扮演的就是这个线性映射角色——它决定“如果 token i 想把自己的信息注入到 token j,上哪条方向注入”。
- 什么是 **[[低秩 (low-rank) 变换]]**?
- **矩阵秩 (rank)** ≈ 这张矩阵能表达多少**独立方向**:
- 满秩方阵 12 288 → 可以覆盖 12 288 个独立方向。
- **低秩** = 只需要 _r_ (≪ 12 288) 个方向就能近似原来的作用。
- **做法**:把大矩阵分解成两个小矩阵相乘:
$\mathbf{V}\;\approx\;\underbrace{\mathbf{U}\in\mathbb R^{d_{model}\times r}}_{\text{value-down}} \;\; \times\;\; \underbrace{\mathbf{W}\in\mathbb R^{r\times d_{model}}}_{\text{value-up}}$
- 其中 _r_ 通常取 128 或 256。
- **参数量**从 1.5 亿 ↓ 到 2 × (12 288 × 128) ≈ 3.1 百万,一下子省俭 50 倍。
- 直观上,你可以把 _r_ 想象成「我只保留最有用的 128 条语义主轴,让信息在这条压缩管道里流动,再展开」。这跟人类写提纲→展开正文很像。
- **U_down**:像「把大象放进冰箱」——先压成 128 维的语义精华。
- **W_up**:再把精华撒到 12 288 维空间里去影响其它 token。
- 为啥拆成两步就跑得更快?
1. **显存&参数量** —— 直接砍到原来的 ~2%。
2. **计算量** —— 乘 128 × 12 288 的矩阵,比乘满秩方阵少 ~100 倍 FLOPs。
3. **并行友好** —— 两个 skinny 矩阵乘法更容易在 GPU 上做张量并行。
- - Cross-attention [19:19](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=1159s)
- - Multiple heads [22:16](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=1336s)
- - The output matrix [23:19](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=1399s)
- - Going deeper [24:54](https://www.youtube.com/watch?v=eMlx5fFNoYc&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=7&t=1494s)
- 最终,在 GPT-3 的 transformer 模型中,所有注意力头相关的参数总数达到了将近 580 亿个,占 1750 亿个参数的 1/3。
- 
- - Ending
# how
- 模型的目标只有一个,获取一段文本,然后预测下一个词
# how good
- 我可不可以理解为就像人类阅读,通过提取关键词,再将关键词串联来理解文本?
- 可以**大致**这么类比,但要留意两点细微差别,harry:
1. **不仅是“关键词”那么简单**
- 人在阅读时往往先捕捉显眼的词(“wizard”“Harry”“Quidditch”),然后在脑海里把它们串成“哦,这是哈利·波特宇宙”。
- Transformer 的注意力头也会把某些 token 赋予更高权重,让它们“拉”走上下文里的信息。
- **区别在于**:==模型关注的并不一定是我们肉眼认定的“关键词”。它用 1 万多维的嵌入空间去衡量“重要性”——可能是某种细微语义模式、子词片段、甚至标点在特定任务上的统计暗示。==
2. **连接方式更像“连续向量运算”,而不是显式的链表**
- 人串关键词时,脑中会出现逻辑链(“wizard→magic→Harry Potter”)。
- 模型则是把 **权重矩阵 A** 乘到 **value 向量 V** 上,让信息以线性组合的形式流动。没有显式符号链,却能用向量加权把“哈利 + 巫师”这两个概念嵌合到同一个 token 的向量里,后续层再继续加工。
- 这使得它能同时捕捉多条互相交叉的关联,而不仅是一根线状链条。
- **一句话**:你可以把“非语法关联”想成“模型像读者一样察觉关键词并串联语义”,但它的“关键词”判定和“串联”方式,远比人类直觉更隐含、更向量化、更并行。正是这种向量化并行,让 Transformer 能在几百毫秒里把几十行小说转成“谁和谁有关”的高维语义图谱。
# inbox
# todo
# ref.
- [ ] link
# related.
# archive.