# why
# what
- **“Semantic”** 通常指“语义、含义”。
- “Semantic space”是一个用来表示词语、概念意义相似度或关系的空间。**强调了概念之间的相似关系**。也就是说,如果两个词或者概念在意思上很接近,那么它们在这个空间里的位置就会离得很近;如果意思差很多,就会离得很远。
- **思维语言**:在 LLM 中,不管是中文、英文、法文,都是共享一个**概念空间**。LLM 使用同一种**思维语言**进行思考,不同的语言只不过是思维的表面形式。[claude团队揭秘:ai大脑不用英文也不用中文思考,而是靠“思维语言”](https://mp.weixin.qq.com/s/7TsCPpiA-HVd-3UAnk1hEg)
- 这一概念在[[NLP 自然语言处理]]里经常出现,当我们说“语义相似度”时,就是在一个高维向量空间里比较两个词向量或句向量之间的距离。
- 高维空间,人类无法想象,这是一个高维空间映射到一个三维切片上的效果
- 
# how
## 语义相似的词离得很近
- 在语义空间里,所有的 token(字、词、句子、标点)都被转换成了数字向量,语义相近的 token 就会出现在**位置接近、方向一致**的地方。所以,当 GPT 每生成一个 token时, 也是一次在高维[[语义空间]]里的一次**语义运动**。
- 这与人类的[[什么是编码?|理解]]方式不一样,人类通过理解知识砖块的语义和所处的语境来理解世界,transformer高维空间中向量之间的关系。
- [[《这就是 ChatGPT》]]的例子:cranberry、blueberry 、grape 等浆果自动聚成一团,apple、banana、melon 等肉果也自动聚成一团,cat、dog、bear 等动物又自动聚成一团;
- 跨语言:不论何种语言,也神奇地在高维空间中聚成一团!“我是一名学生”,“i am a student”,“je suis etudiant”……不同语言等翻译
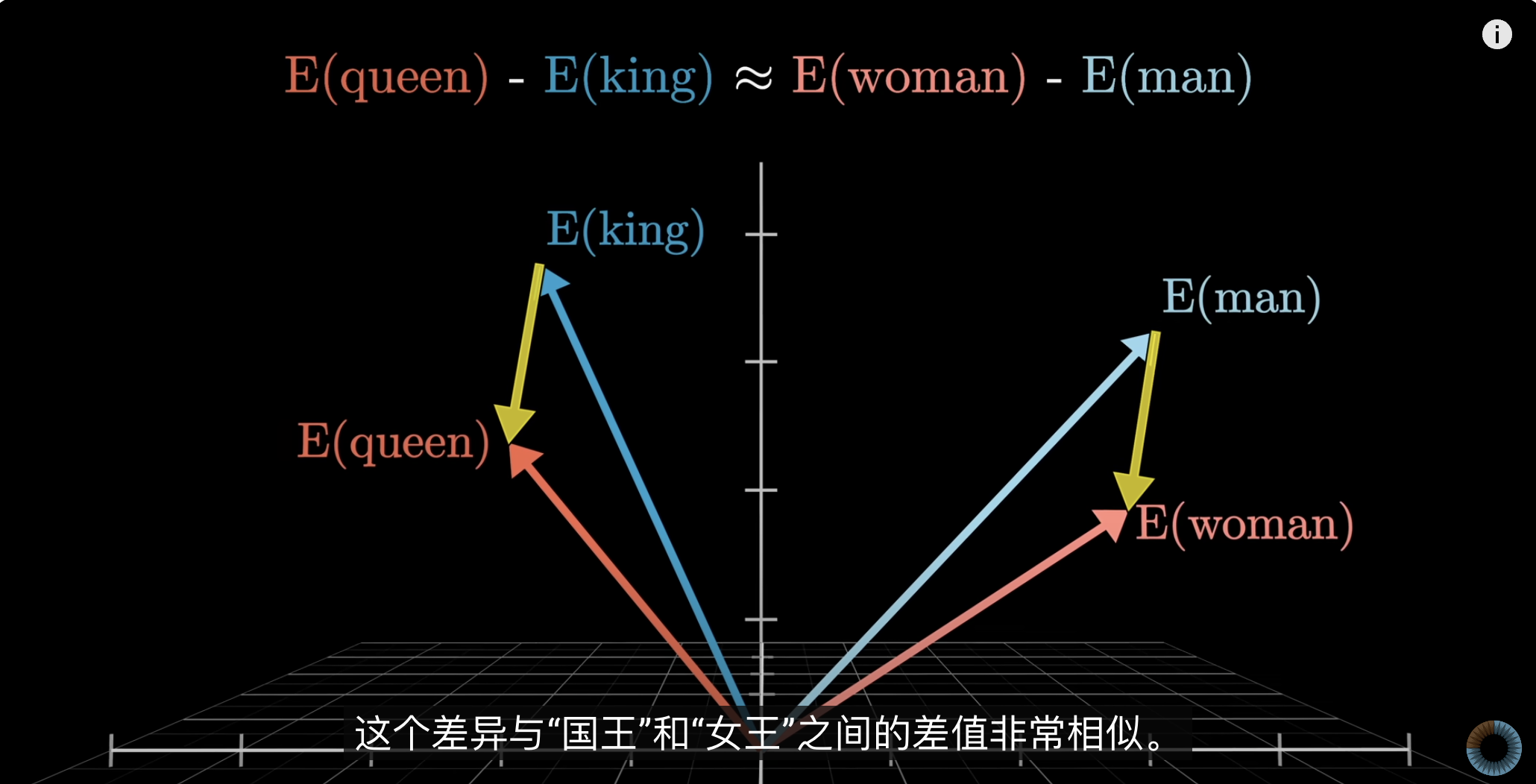
- 词与词之间的关系:king-queen=man-woman;
- 向量之间的位置关系:这里的数学概念叫做[[dot product 点积]]。
- AI 为什么这样理解世界,人类还不得而知,目前只知道这就是它们理解世界的方式。
%%如果想要可视化嵌入向量,首先要将高维空间降为到低维,比如二维或三维,比如利用`t-SNE`来降维。%%
### 打个比方
- 想象一下你在一个城市里导航,城市里每个位置都有一个坐标(比如经纬度),两个建筑物越是相似(比如都提供住宿,都是五星级酒店),它们在“语义地图”上就越相邻。
- 在semantic space里,**“hotel”** 和 **“motel”** 这两个词的向量坐标就会比 **“hotel”** 和 **“pizza”** 更接近,因为前两个词表示的事物在含义上更相似。
### 直观例子
- 人脑中处理语言也有类似的“空间”感:如果我跟你说“狗”,你可能联想到“猫”“宠物”“狗粮”“汪汪叫”等等,因为它们在语义上离“狗”这个概念都很近。
- 当模型需要去理解一段话时,它会将其中每个词或短语映射到这个语义空间里,看它们彼此的位置,从而对整段话的含义进行推断。token 在语义空间中进行位置和方向上的运动。
- GPT 翻译原理
- 将一种语言翻译成另一种语言时,只需要在高维空间中寻找到和目标语言最接近的 token
- 还可以在附近找到其他的表达
## 语义空间与[[潜在空间]]的区别与联系
- **联系**:二者都是在高维向量空间里抽象地表示信息。
- **区别**:
- Latent space 更偏向于“模型内部”的一个全面**特征表示**。它可能既**包含了语义**,也包含了语法、上下文等各种信息。它是更底层、并不直接面向人类语言的“压缩存储”。
- Semantic space 更强调“含义”之间的相似关系,是一种更聚焦于“语言意义”本身的向量表示。
## 语义空间与上下文
- 把所有的数据集token学完之后(预训练部分),每个 token就会在[[语义空间]](多维度向量空间)里有一个点,每个点的位置和方向就是这一 token 的原始意义,意义相近的 token 会在空间中离得更近。然后在使用时,比如我们给它的 prompt,GPT 根据给出的句子去生成下一个词([[LLM的本质是自回归 transformer]]),每次生成一个词,不断地调整整个句子在语义空间中的位置和方向。所以神经网络的AI 并不是通过语法规则来理解文本,而是**通过单词在使用场景的上下文来理解语义**的。这一点和人类一样(羽毛和羽毛笔,苹果和苹果手机)
- > *研究人员可以构建一个多层前馈神经网络,并用从网络公共资源中收集的数十亿乃至数万亿个句子来训练它。神经网络用于在500维(即一个由500个数字组成的列表,尽管这个数字是任意的——它可以是任何相当大的数字)空间中为每个句子分配一个点。起初,这个点会是随机分配的。在训练过程中,神经网络会调整这个点的位置,使得意义相近的句子在空间中彼此靠近,而意义不同的则相隔更远。进行了大规模语句训练后,任何一句话在这个500维空间中的位置就能准确地反映出它的含义,因为这个位置是根据它周围的其他句子来确定的。—— 《奇点更近》*
# how good
思考,不过是思维在高维语义空间中进行的有意义的运动
- 语义空间,对于 LLM 来说是高位向量空间
- 对于人类来说,是清晰的[[知识砖块]]组成的高维概念空间
# Ref.
- [所谓思考,只不过是思维在高维语义空间进行的有意义的运动](https://quanzi.xiaoe-tech.com/c_5c1ade1660b8e_66epWNJt6847/feed_detail?community_id=c_5c1ade1660b8e_66epWNJt6847&share_type=12&share_type=12&share_user_id=u_5fe70d591397a_vXMZy5Hozz&share_user_id=u_5fe70d591397a_vXMZy5Hozz&app_id=appDlhUKBqJ1468&feeds_id=d_67832958b5b0b_ofqFmiaGJBM4)
- [潜在空间与语义空间两个概念的区别与联系](https://readwise.io/reader/shared/01jhexekj8r7k9hpq1rq8bmq1q)