事实证明,这些大型语言模型在预测下一个词的任务中([[LLM本质]])的性能(即准确度)是一个非常平滑、表现良好且可预测的函数,它仅依赖于两个变量。你只需要知道两个数字:
1. N - 网络中的[[parameters 参数]]数量
2. D - 你用来训练的文本量
仅凭这两个数字,我们可以非常有信心地预测你在下一个词预测任务中会达到什么样的准确度,而且趋势似乎没有显示出趋于饱和的迹象。
所以如果训练一个更大的模型,并使用更多的文本D,训练出更多的参数 N,则会提升预测的准确度。例如 GPT4 ,万亿参数的准确度要高于 GPT3.5,1750 亿参数。
算法上的进步不是必要的,它是一个很好的加分项。
大力出奇迹:想要得到更好的预测下一个词任务的模型,就是在预训练阶段投入更大,更多的文本,更多的 GPU,训练时间更长,得到更多参数。这有点像人类的学习,海量、丰富、高质量的输入,在学习的过程中不断优化突触连接,就会表现为学习能力更强,知识渊博,并且人类的大脑也是无上限的。而**小数据量**容易出现[[overfitting 过度拟合]]的问题,就好像对学习者进行了题海战术,在题海范围内的题都能非常适应,但是一旦超出了题海范围就不会做了。
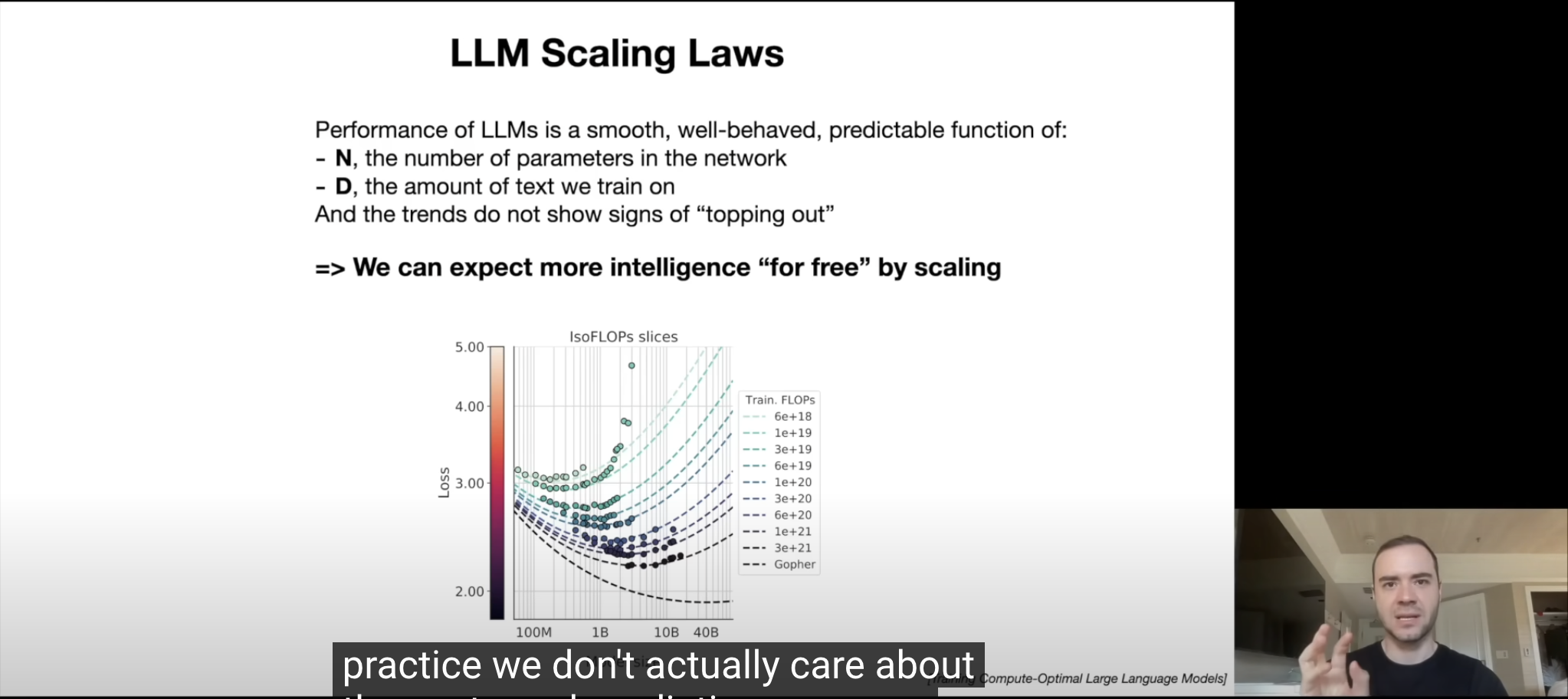
- 所谓规模法则就是大力出奇迹。
- ## 参考资料
- [缩放定律 - Wikipedia](https://en.wikipedia.org/wiki/Neural_scaling_law)