# why
[[Transformer]]的核心技术。
# what
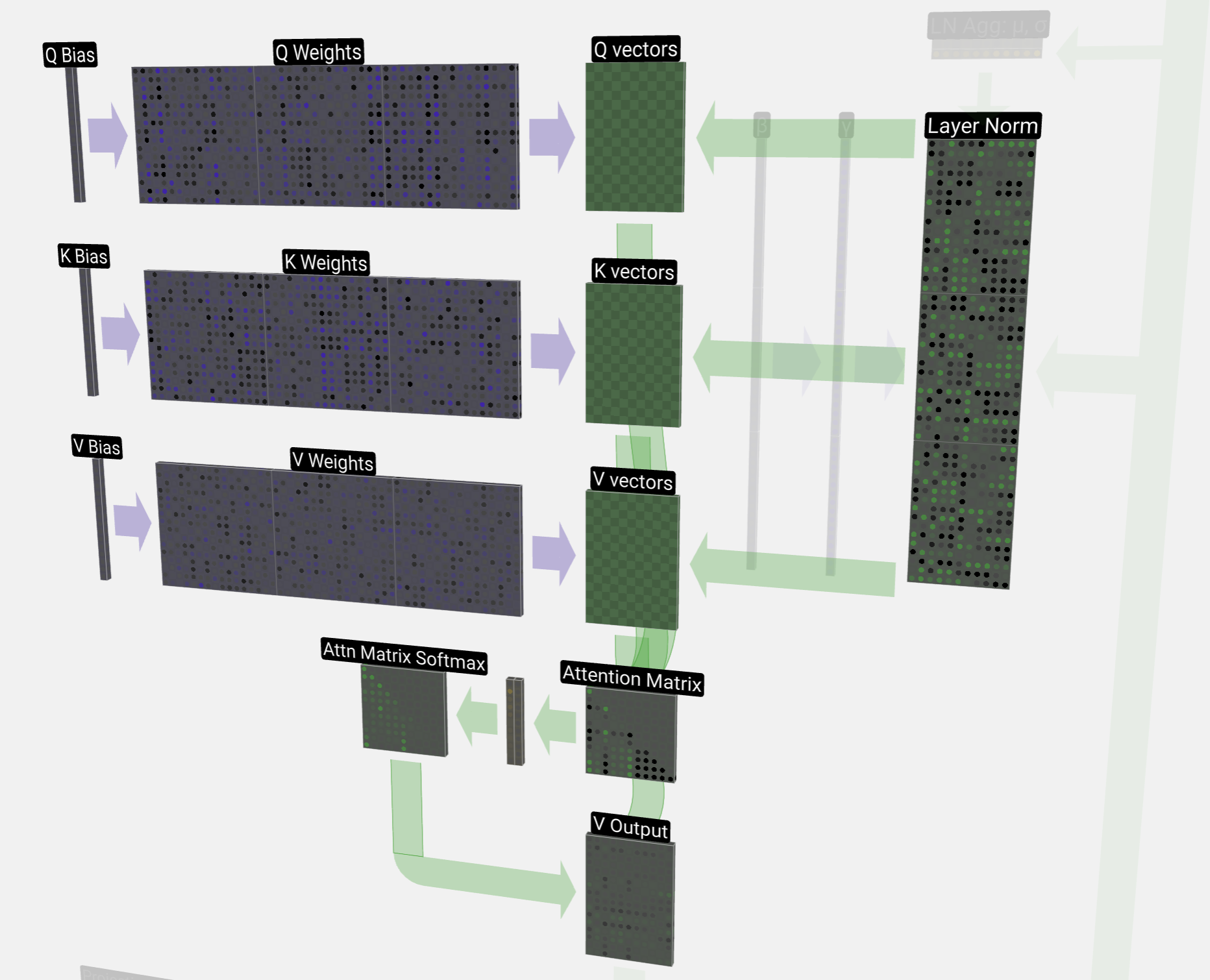
- Transformer的**核心**是**自注意力机制(Self-Attention)**。它让模型在处理一个词时,不仅只关注它前面的词,还能够**同时关注**到上下文中所有其他位置的词,从而更好地理解每个词之间的关系,并得出哪些词是重要的(需要更多注意力),哪些是不重要的,从而进行**权重分配**。这就相当于每个词在看其他词的“重要性”。就像我们在阅读时会划出**关键词**。
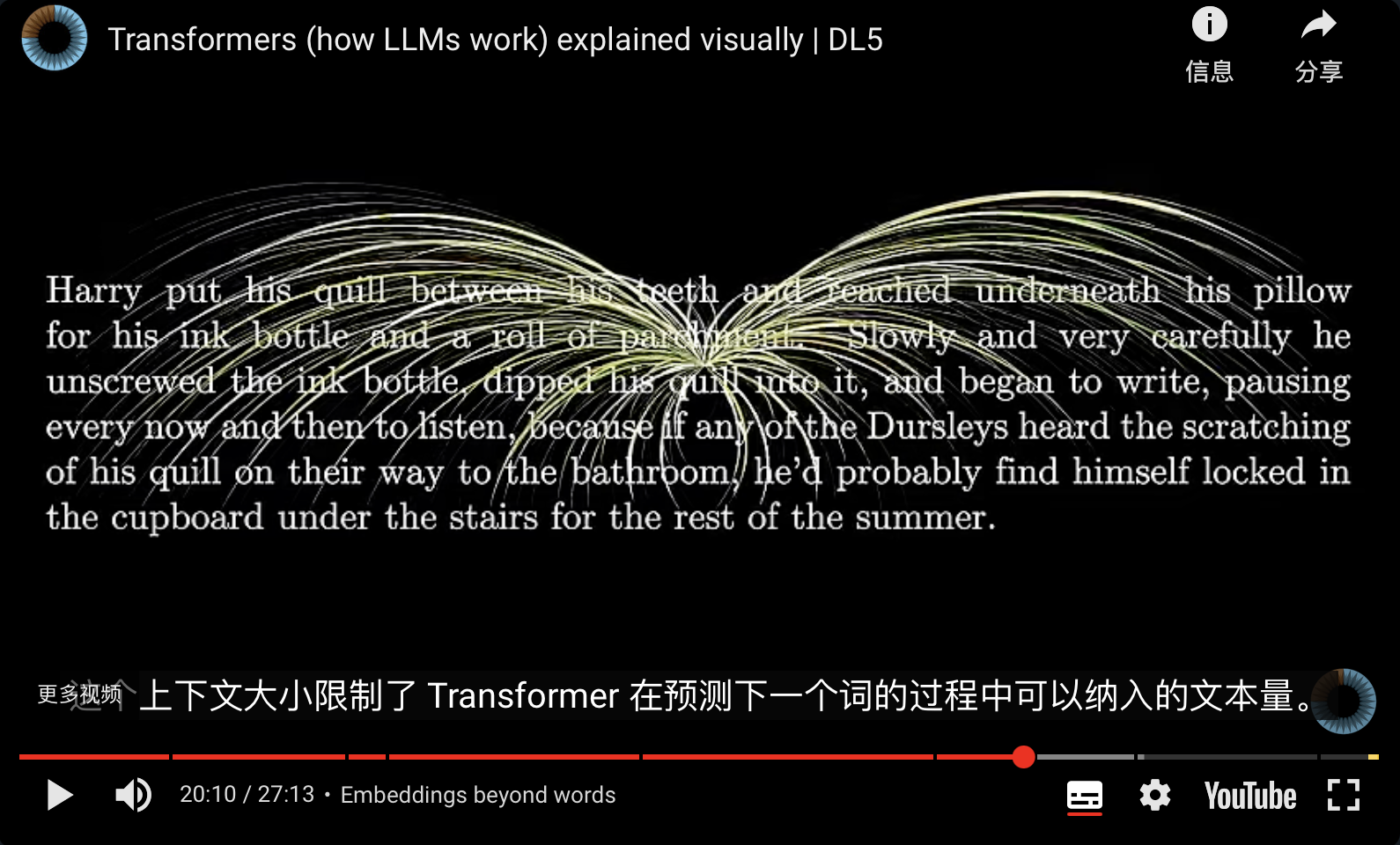
- 大语言模型的重要目标就是理解文本,以前的理解都是根据前一个文本,但是 attention 是根据几十k 的[[context length 上下文长度]]来理解。相当于人类的[[学习五元素 主动参与 工作记忆|工作记忆]]
- 上下文长度决定了模型的记忆力,超出这个部分的内容会被“忘记”。但是 2025 年初的 chatGPT 有了“永久记忆”功能。
# how
## 打比方
- 你在课堂上听讲解,假设你正在听一位老师讲解一个故事,比如“今天我们去海边玩”。老师说的每个词都有其意义,但它们之间也有联系:
- “今天”是时间的指示词,提醒你今天发生的事;
- “去”表示动作;
- “海边”是你将要去的地方;
- “玩”是动作的最终目的。
- 在听讲的过程中,你**同时**会关注每个词,理解它们之间的联系。比如,“去”跟“海边”有很强的关联,它们组成了一个完整的意思,而“玩”则是你要做的事情。你并不是先理解“今天”,然后理解“去”,接着理解“海边”,再理解“玩”,而是把整个句子一起理解。这就像Transformer的自注意力机制:每个词在处理时,可以“关注”到整个序列中的所有其他词,**并行地**捕捉它们之间的关系。
- 假设我们有一个简单的句子:
- **“猫在桌子上玩耍”**
- 在传统的RNN或LSTM中,模型是按顺序一个词接一个词地处理。假设模型正在处理词“桌子”,它可能需要先理解“猫”和“在”后,才能理解“桌子”,再到“上”,最后是“玩耍”。这样每一步都需要依赖前一步的结果。
- 而在Transformer中,模型在处理“桌子”这个词时,不需要按照顺序处理。它会**同时**查看**整个句子**:
- 它会通过自注意力机制,理解“桌子”与“猫”的**关系**(“猫在桌子上”),理解“桌子”与“玩耍”的关系(“桌子上玩耍”)。甚至会看到“猫”和“玩耍”的关系(猫是玩耍的主体)。
- 这种“同时”关注整个句子,能够帮助模型更好地理解句子的意思,尤其是对于长句子,能够捕捉到词与词之间的远距离关系。
## 计算过程
- [[Transformer 模型中的注意力机制 - 3b1b视频DL6]]
# how good
# Ref.
- [transformer概念解释](https://readwise.io/reader/shared/01jhshtjdpkqd1bkwg8pt85qnw)
-