# inbox
# todo
# WHY
- 人类从很早以前就在思考什么是智能?我们为什么存在?
- 17 世纪,笛卡尔提出“我思故我在”(thinking,being)
- 1950 年,图灵提出如何创造一个 thinking machine 所需的2 个元素:
- 感知 - 视觉 vision
- 对含义的理解和推断 - 语言 language
- 1956 年达特茅斯会议上确立了人工智能(AI)这门科学学科,至今 68 年的历史
# WHAT(树干)
- **将图灵的设想付诸实践,以[[符号人工智能]]的方式**
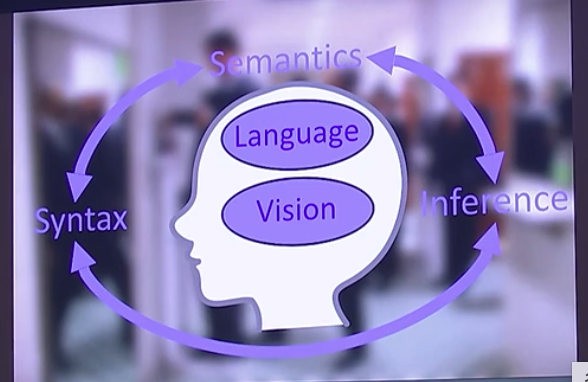
- Terry Winograd 是第一代将图灵提出的想法运行起来的人,他提出“一个人要理解世界”需要具备以下几点:
- 感知世界 perceive the world
- 需要对世界的结构做一个理解 syntax understanding
- syntax 在语言里是指句法结构
- 在视觉领域通常指[[三维结构]]
- 理解含义 semantics
- 进行推理 inference
- 
- 在以上的理论支持下,Terry Winograd 开发了[[SHRDLU]],可以理解人类的自然语言的计算机程序。
- **机器的「学习」过程出现了问题**
- Terry 使用的是[[符号人工智能]],即 hand-design rule,这种方法在当时看似是最“正确的”,但还是带来了 3 调阻碍
- 可扩展性
- 可适应性
- 虚拟完整的世界
- **从人类编程到[[machine learning 机器学习]]**
- 1958 年的[[perceptron 感知器]]
- 1962 大卫·休伯尔与托斯坦·威泽尔发现猫的视觉皮质的层次结构与深度学习网络的架构类似
- 1980 由日本科学家福岛邦彦 kunihiko fukushima发明了可以识别数字和字母的模型,原始的卷积神经网络架构,用的是监督学习与无监督学习算法。
- 1998 年,Hinton 和杨立昆在[[Backpropagation 反向传播算法]]的基础上进行优化,受视觉皮质启发,发明了[[CNN 卷积神经网络]]
- 2012 年,[[AlexNet]]
- **数据、算法、GPU**
- 2012 年的 AlexNet 其实和 CNN 的区别不大,但却得到了革命性的进步,主要是因为 3 个因素:数据、算法和 硬件的发展
# HOW(树枝和树杈)
**解决图灵提出的问题,以[[machine learning 机器学习]]的方式**
**视觉:**
- syntax:[[三维结构]],比如无人驾驶
- semantics:物体分类、场景分类、物体监测、物体切割,比如 ImageNet
- syntax+semantics:3D 建模与物体识别
**视觉+语言**:
- syntax+inference:CLEVER做了行业的基准(benchmark),与 SHRDLU解决的问题类似
- 
- 用不同的[[Deep Learning 深度学习]]模型来测试发现,[[LSTM 长短期记忆]]和 CNN 是表现最好的。
- 截至 2016 年,AI 对材料、数量、比较等能力还达不到人类水平。
- **看图说话**:
- 对一幅图进行一句话、几句话到一段话的描述
- next actions: 2016 年的 AI 还不能读懂一幅图中的幽默,但是 2024 年的[[GPT4o]]已经可以了。
# HOW GOOD(思维模型)
# ref.
- [SHRDLU](https://zh.wikipedia.org/wiki/SHRDLU)
- [原视频](https://readwise.io/reader/shared/01hzerzhh53r3reaffwb3jr4st)
# archive
---