# why
因为[[tokenization]]所使用的算法导致的。当 strawberry 被分割成 token 时被分成了 3 个 token,所以就数不清楚有几个 r 了。

# what
Andrey Karpathy 将词元化的 token 比喻成“象形文字”,就像一个个 emoji 一样。
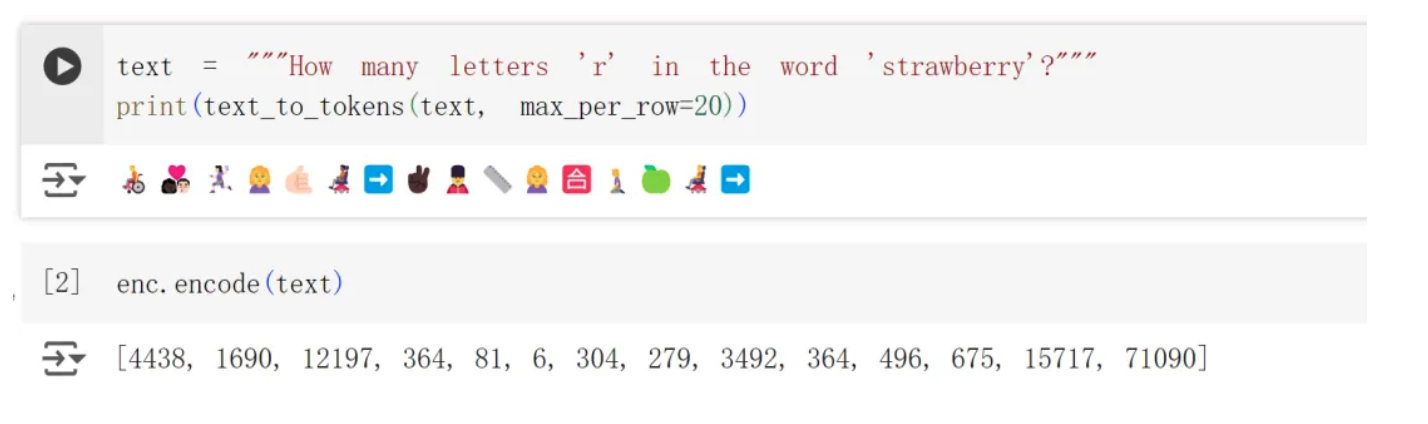
# how
A 对大模型能够在奥数考试中表现出色,却在数数、比大小这种低幼游戏中失败是因为 **模型没有认知自我知识的能力 cognitive self-knowledge。** 人类具备这个能力,是因为“人类的知识体系和解决问题的能力在成长过程中是高度相关的,并且是同步线性发展的,而不是在某些领域突然大幅度提升,而在其他领域却停滞不前。”
如果模型认识到自己具备的知识,可能面对不擅长的内容,会先回答不太擅长,然后调用工具,例如:“「我不太擅长数字母,让我使用代码解释器来解决这个问题」。”
解决这个问题的方法可以借鉴 Llama3.1, section4.3.6,Meta 的研究者提出了一些方法来让模型「**只回答它知道的问题**」。
> 我们遵循的原则是,后训练应使模型「知道它知道什么」,而不是增加知识。我们的主要方法是生成数据,使模型生成与预训练数据中的事实数据子集保持一致。为此,我们开发了一种知识探测技术,利用 Llama 3 的 in-context 能力。数据生成过程包括以下步骤:
> 1、从预训练数据中提取数据片段。
>
> 2、通过提示 Llama 3 生成一个关于这些片段(上下文)的事实问题。
>
> 3、采样 Llama 3 关于该问题的回答。
>
> 4、以原始上下文为参照,以 Llama 3 为裁判,评估生成的回答的正确性。
>
> 5、以 Llama 3 为裁判,评估生成回答的信息量。
>
> 6、对于 Llama 3 模型在多个生成过程中提供的信息虽多但内容不正确的回答,使用 Llama 3 生成拒绝回答的内容。
> 我们使用知识探测生成的数据来鼓励模型只回答它知道的问题,而拒绝回答它不确定的问题。此外,预训练数据并不总是与事实一致或正确。因此,我们还收集了一组有限的标注事实性数据,这些数据涉及与事实相矛盾或不正确的陈述。
# how good
- 引发的问题:为什么大模型不能在第一次回答中答对?
如果让大模型step by step的回答,或者告诉它先删掉 r 以外的字母,模型就能回答正确。为什么模型不这样做。A 给出的回答是“因为没人教他”。
也有人给出其他原因:可能是因为模型被设定为先使用system1(本能反应),如果不对在使用 system2,有逻辑推理的系统。
- 引发的思考:参差不齐的智能 jagged intelligence
# Ref.
- [https://readwise.io/reader/shared/01j4p3c44re60es9zh9k27e43n](https://readwise.io/reader/shared/01j4p3c44re60es9zh9k27e43n)
- [https://mp.weixin.qq.com/s/c52Ca4g0USzSIRXSEq-t4w](https://mp.weixin.qq.com/s/c52Ca4g0USzSIRXSEq-t4w)