- # inbox
- [[元胞自动机]]?p49
- # todo
- # WHY
- # WHAT
- [[LLM 大语言模型]]的基本原理。
- [[ChatGPT3.5]] : 400个核心层,数百万个神经元,1750 亿个连接权重,96 个注意力块,权重数量与训练token数量相当
- # HOW
- ### token 它只是一次添加一个词
- 针对它得到的任何文本产生“合理的延续”。也就是说 GPT 生成的内容得是我们能够理解且认为是合理的。
- 例如:the best thing about ai is its ability to ...
- GPT 将把人类数十亿个网页上的内容都看一遍,然后预测下一个词应该是什么。*寻找某种程度上的“意义匹配”。* #todo 稍后解释
- 给词汇表的每个词生成一个概率。**但不一定是概率最高的就是最好的,通常将[[Temperature 超参数]](指数分布-玻尔兹曼分布)设定为 0.8 的输出结果较好,虽然还不知道为什么。** 生成的**随机性**就和模型会随机选择排名较低的 token 有关。
- **GPT是在每一次生成下一个 token 的时候都做一遍浏览,然后预测下一个词应该是什么。**
- ### statistics 概率从何而来
- 模型的概率根据是怎么来的?
- 先考虑一个简单的问题:
- 每个英文字母出现在下一个位置的概率。2-gram or bigram的概率显示,q 后面只有 u
- 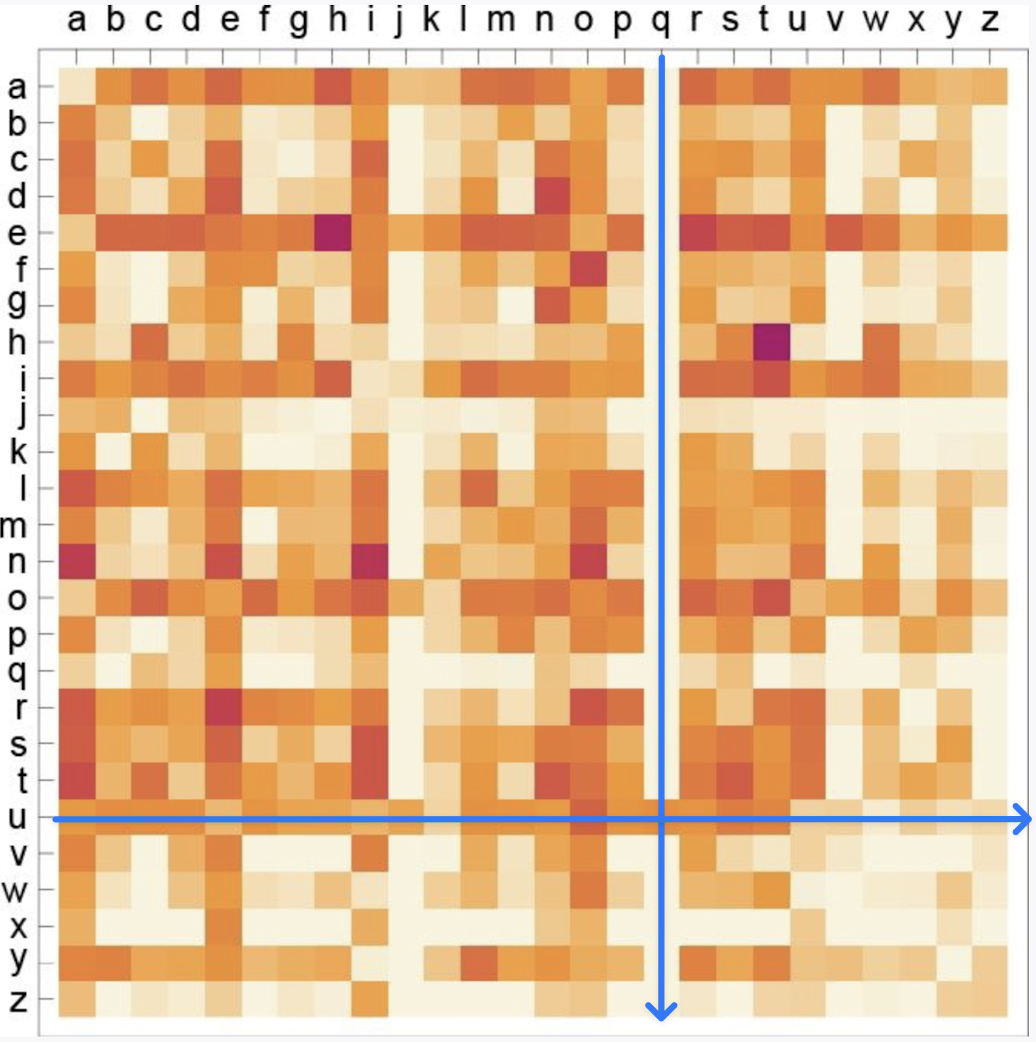
- 从 2-gram 变成 n-gram 字母的概率生成随机的词会出现一些真实的词
- 
- 用互联网上 50000 个常用词的概率生成的“句子”
- 
- 常用词的 n-gram的概率生成的“句子”将更加合理
- 
- 如果有足够的维度,几乎可以得到一个 ChatGPT,但是即使只有 4 万个常用词,2-gram 已经达到了 16 亿,3 元词是 60 万亿,无法估计这样的概率。解决办法是构建一个[[LLM 大语言模型]]。*没看懂* #todo
- **启发**
- GPT 的生成概率来自互联网上几百亿个词的出现概率。人类的自然语言也有自己的组合概率(互联网上的内容毕竟也是人类编辑的)。所以 GPT 在预测下一个词的时候就是在使用我们语言习惯(文本习惯),并通过温度参数来提升“创造力”。
- *这里说的 n-gram 是不是 token 的向量维度?* #todo
- ### model 什么是模型
- 理论科学的本质:为观察到的测量和记录建立一个模型,用这个模型不仅可以解释数据,还可以预计数据。
- 任何模型都有基本的特定结构和用来拟合数据的旋钮(参数)*是不是数学公式里的一些常亮?* #todo
- ChatGPT:模型-[[矩阵向量乘法]];参数-w
- $a+bx+cx^2$
- x 为给定,拟合的参数
- a 为特定
- ### pattern recognition 类人任务
- 大语言模型:对人脑产生的文本建立模型。这样的模型长什么样? —— [[ANN 人工神经网络]]
- 图像识别也是一种类人任务
- 教会机器识别图像,第一件事可以是获取每个数字的大量样本图像,任何字体、任何写作模式。
- 用输入的图像与**特定**的数字进行**逐个像素**的比较。人类可以将各种扭曲、涂抹、模糊的数字都很好地识别出来。
- 如果将数字图像中的每个像素的**灰度**值(参考[[影调]])视为变量$x_i$ ,是否存在涉及所有这些变量的函数,能在运算后识别出图像中的数字? #todo 可以。
- ### neural networks [[ANN 人工神经网络]]
- **神经网络的架构**
- 人脑神经网络 - [[孩子天生爱学习 神经元构造|神经元]]:神经元协同亮起一次表征一个概念或识别一个图像。
- 人工神经网络架构,例如[[Transformer]]
- 
- **神经网络识别事物的方法**
- 神经网络是如何识别事物的?[[attractor 吸引子]],相似的离得更近。
- 创建一个由像素灰度组成的 784 维的向量空间
- **如何执行识别任务,计算矩阵向量乘法**
- 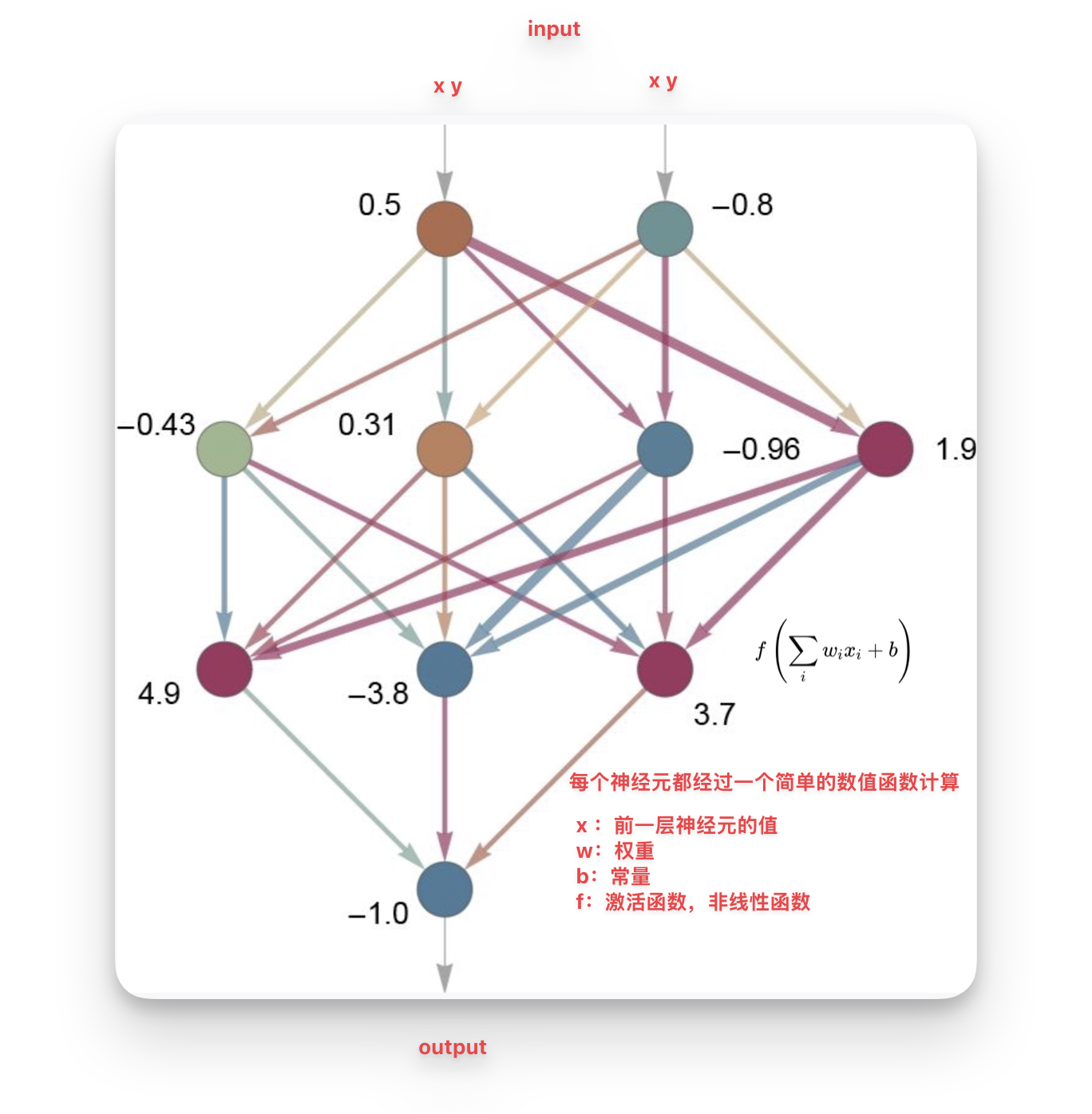
- **单个神经元**
- 每一个神经元都会做一次简单的[[数值函数]]运算:$f(wx_i+b)$
- **线性组合**
- x为前一层神经元的值,w 为特定的权重,进行乘法运算
- 将每个神经元的乘法部分进行加法运算
- b:然后加上一个常数
- **非线性组合**
- f:最后应用一个[[activation function 激活函数]]
- 为了让神经网络能够模拟更复杂的行为,将前一步计算的线性组合结果通过一个非线性函数(如ReLU、Sigmoid、Tanh等)进行转换:
- 最终结果:
- $f\left(\sum_{i} w_i x_i + b\right)$
- 越多的神经元,模型的表现越好,比如 LLM 这样的大型神经网络。
- 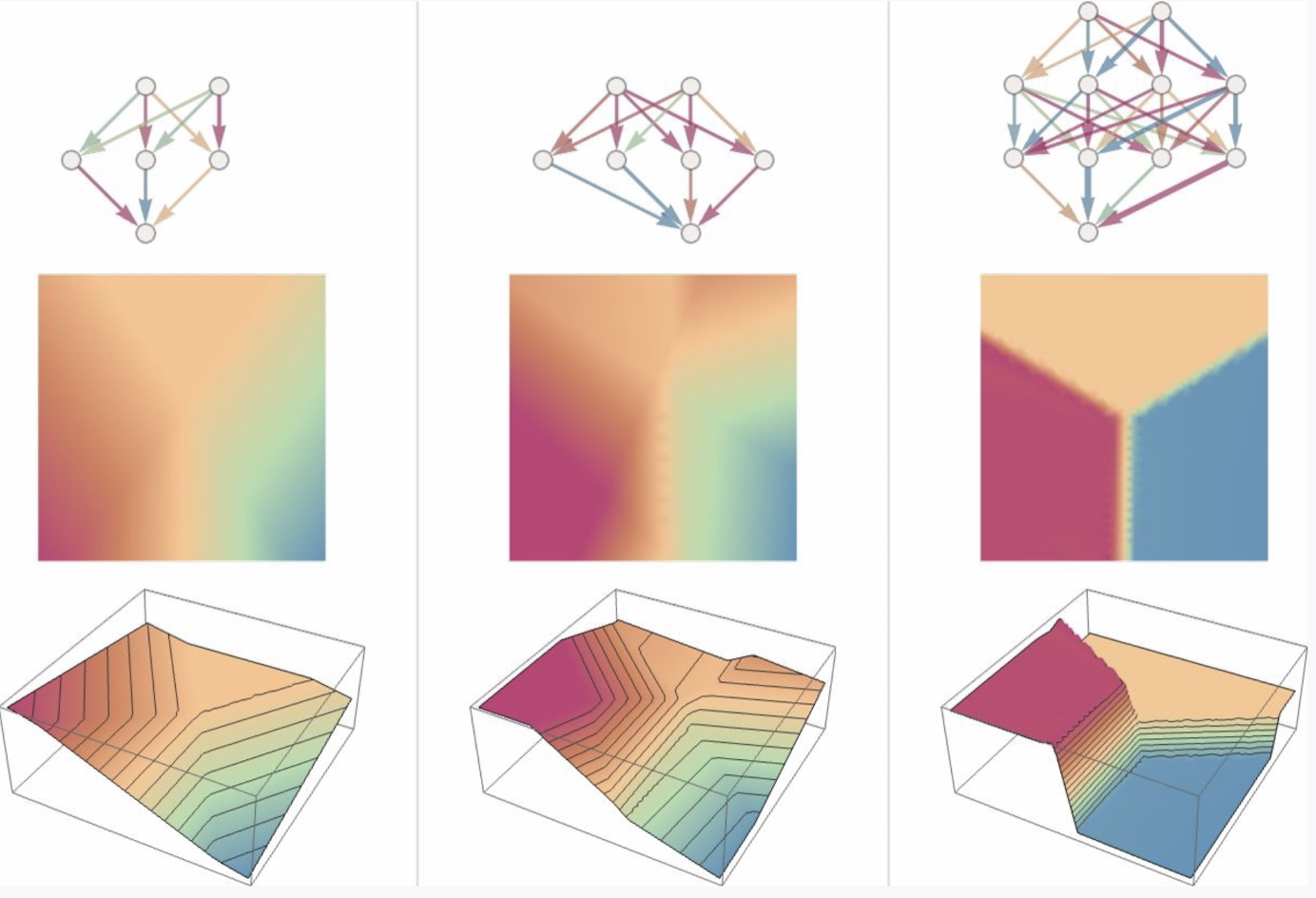
- **神经网络为何可以完成类人任务,我们尚不知道,只知道它会完成得很好。可以像人类一样进行[[特征学习 Feature learning]]和模式识别。**
- **识别猫狗图像**
- 寻找“最近点”:17 个神经元
- 识别手写数字:2190 个神经元
- 识别猫狗:60650 个神经元。*很难可视化出60650维的空间?* #todo ==这里的神经元等于什么概念?维度?==
- ### [[machine learning 机器学习]]和神经网络训练
- **根据样例学习——机器学习**:
- 神经网络之所以可以执行“寻找最近点”、“识别手写数字”、“识别猫狗”等等任务,不是因为人类给了他们特定的任务。而是神经网络通过**自主学习**([[machine learning 机器学习]])进行训练的结果。
- 像人类学习语言一样,神经网络可以将案例进行[[泛化]]。比如人类幼崽阅读大量的绘本,会自然习得语法,并将句子迁移到实际生活中。
- **神经网络的训练是如何起效的?**
- 通过不停地迭代[[weights 权重]],预训练的最终结果就是得到一份不再更新的权重。
- > 本质上,我们一直在尝试找到能使神经网络成功复现给定样例的权重。然后,我们依靠神经网络在这些样例“之间”进行“合理”的“插值”(或“泛化”)。p107
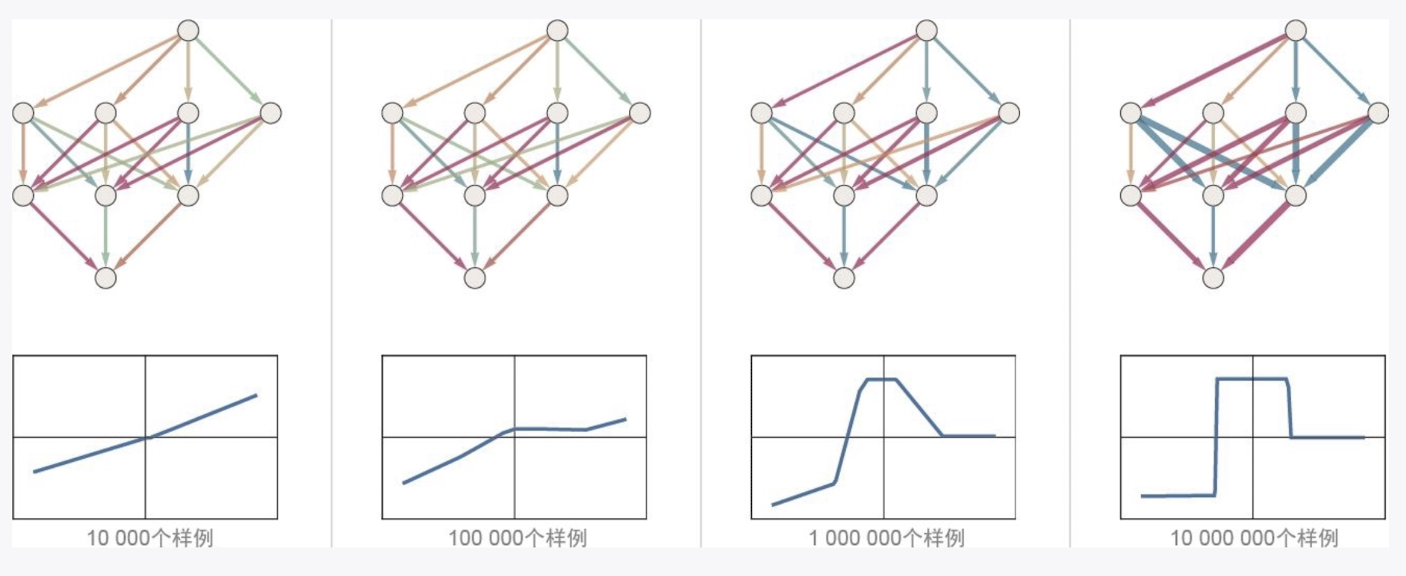
- **如何找到能使神经网络成功复现给定样例的权重?**
- 通过大量的输入-输出学习。1 万个输入输出学习和 1000 万个输入-输出学习的区别,后者更接近正确答案。
- 
- **如何调整权重?**
- 计算[[Loss function 损失函数]]:根据输出数据与输入数据的差值来调整权重。
- 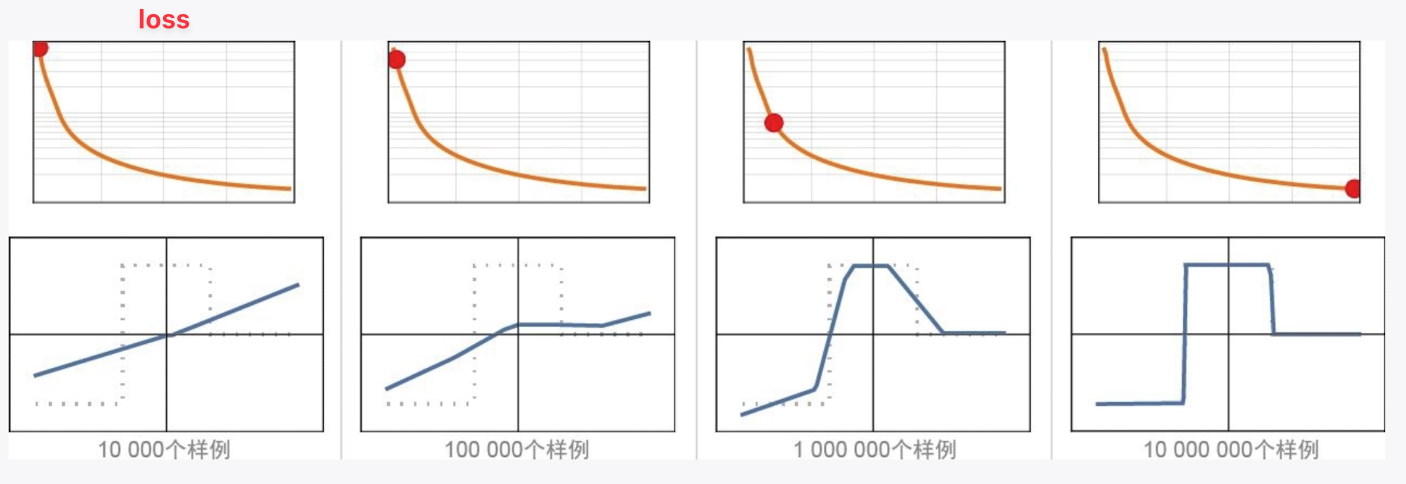
- **如何最小化损失函数?**
- 微积分的[[链式法则]]
- 梯度下降
- 可以想象成水从高处往下流,最终达到一片相对较低的小湖中。*换句话说,有时候用神经网络解决复杂问题比解决简单问题更容易—这似乎有些违反直觉。大致原因在于,当有很多“权重变量”时,高维空间中有“很多不同的方向”可以引导我们到达最小值;而当变量较少时,很容易陷入局部最小值的“山湖”,无法找到“出去的方向”——p115*
-
- ### training 神经网络训练的实践和学问
- **神经网络训练的几个关键问题**
- 针对特定的任务使用何种神经网络架构的问题
- 如何获取用于训练神经网络的数据
- 并不是从零开始训练,而是在新的网络中可以直接包含已经训练过的网络
- **模型的通用性**:
- 并不针对特定任务(心理咨询师、情感辨别 AI)进行多个神经网络的训练,而是训练**一个神经网络**,但具备解决多类型任务的通用能力。
- **[[端到端]]**:
- 早期训练神经网络,人类倾向于让神经网络做“更少的事”,人类进行任务分解,但是后来发现更好的解决办法是端到端的,让神经网络自己发现数据中的特征,识别模式。
- 足够大的神经网络,训练足够长的时间,提供足够多的样本,就能得到类人的输出。
- **如何获取用于训练神经网络的数据?**
- [[Supervised learning 监督学习]]:需要人类提供大量的标注数据。例如用于图像识别的 [[ImageNet]]
- [[unsupervised learning 无监督学习]]:ChatGPT等大语言模型则不需要明确的标签,可以从样本直接学习。
- **未来的改进方向 —— 人类大脑**
- > 神经网络(或许有点像大脑)被设置为具有一个基本固定的神经元网络,==能改进的是它们之间连接的强度(“权重”==)。(或许在年轻的大脑中,还可以==产生大量全新的连接==。)p129
- 人脑的每个神经元都是一台小型计算机,运转更加高效。而现在的神经网络,即便使用了[[GPU]],但仍然有大部分时间是空闲的。
- ### [[规模法则 scaling laws]] 足够大的神经网络当然无所不能
- 作者只讲了一个概念[[计算不可约理论]]。我的理解是,作者认为我们之前的一个结论错了,即让计算机写文章很难。但其实让计算机写文章是相对简单的,因为写文章是一个“计算深度较浅”的问题。==也许人类的语言是相对简单的==,更难的是自然的语言、宇宙的语言,即数学、计算机科学,凑十充满了计算不可约的复杂性。
- ### [[Embedding]] 嵌入的概念
- > 可以将嵌入视为一种尝试通过==数的数组[[向量]]==来表示某些东西==“本质”==的方法,其特性是==“相近的事物”由相近的数表示==。
- [[语义空间]]的二维展示
- 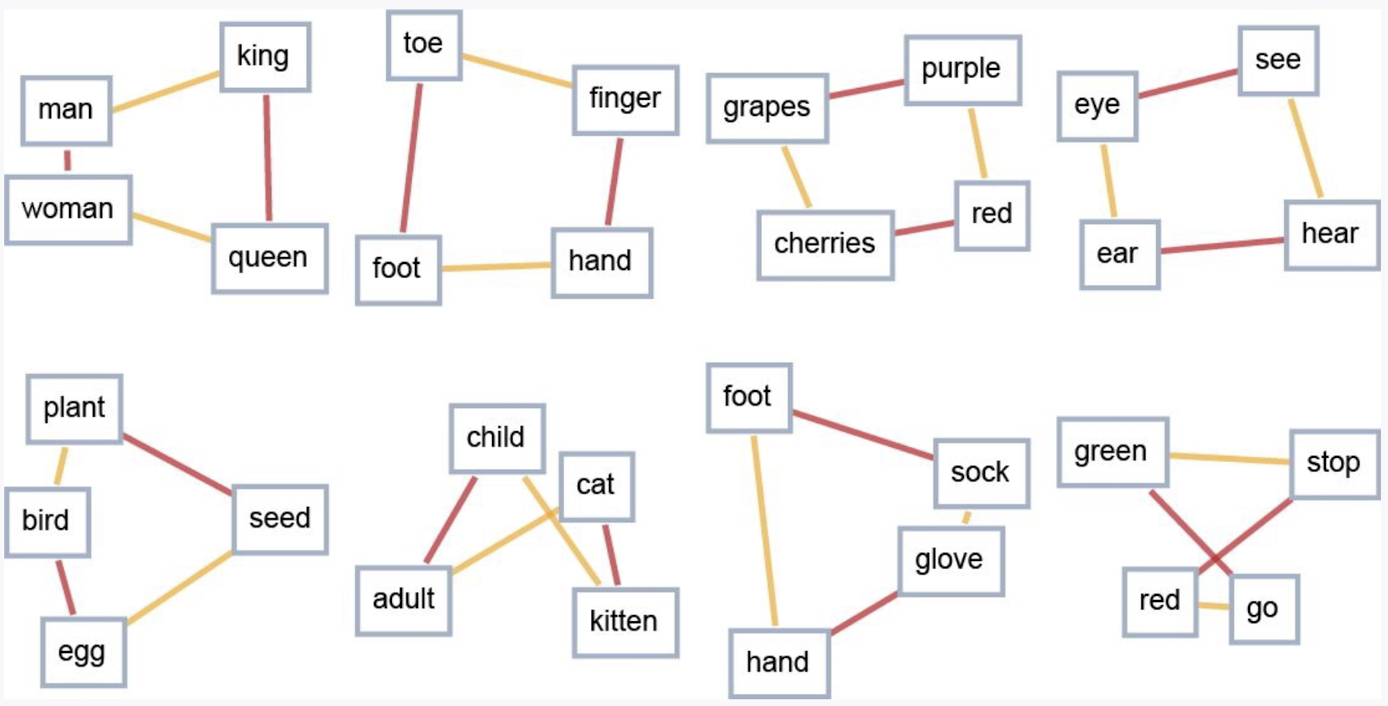
- **如何构建一个能把接近的词嵌入到相近位置的空间呢?**
- 通过学习大量的文本:比如来自互联网的 50 亿个词,然后发现短吻鳄与鳄鱼在相似的句子中经常互换。或者发现turnip(芜菁)和eagle(鹰)一般不会出现在相似的句子中就会离得很远。
- **如何判断是否应该认为这个图像是相似的?**
- > 这里的关键概念是,我们==不直接尝试表征“哪个图像接近哪个图像”==,而是考虑一个定义良好、可以获取明确的训练数据的任务(这里是数字识别),然后利用如下事实:==在完成这个任务时,神经网络隐含地必须做出相当于“接近度决策”的决策。==因此,我们不需要明确地谈论“图像的接近度”,而是只谈论==图像代表什么数字==的具体问题,然后“让神经网络”隐含地确定这对于“图像的接近度”意味着什么。
- 在一个高维的数字向量空间中,由这些浮点数字最终决定了==接近度==。
- **ChatGPT 如何对文本进行表征?**
- 相比[[数对词]],gpt 使用了更好的[[词序列]] (整序列,token ID)。从网络数据中提取并建立一个[[词汇表]],并给词汇表的每个词编制一个 token ID。模型的任务是在每次生成的下一个词时计算这个词汇表中所有词出现的概率。
-
- ### [[Attention]] ChatGPT的内部原理
- 一种特别为处理语言而设置的神经网络 - [[Transformer]]
- 每个神经元都与上一个神经元相连,但这种连接方式对于数据有已知结构有点浪费。例如图像识别采用[[CNN 卷积神经网络]]就够了。#todo 为什么?
- ==[[attention]]==是 transformer 中的一个重要概念,更多地关注序列的某个部分。
- ChatGPT 工作的三个阶段
- 获取 token ID 并嵌入向量,转换成一组 token 嵌入 x高维向量+position 嵌入 x 高维向量的 input 嵌入;
- 经过神经网络,“值“像涟漪一样依次通过”网络中的各层,从而产生一个新的嵌入(即一个新的数组)。”
- 神经网络中有**注意力块**(gpt-2 有 12 个,gpt-3 有 96 个)
- 每个注意力块中都有一组**[[注意力头]]**:对生成的文本进行“回顾的方式”,能以一种有用的形式“打包过去的内容”,以便找到下一个标记。即允许模型回看[[context length 上下文长度]]内的标记和前一个标记来进行预测。
- 经过注意力头处理后得到的“重新加权的嵌入向量”会通过“全连接”的神经网络层。
- 在经过所有这些注意力块后,Transformer的实际效果是什么?本质上,它将标记序列的原始嵌入集合转换为最终集合。ChatGPT的特定工作方式是,==选择此集合中的最后一个嵌入,并对其进行“解码”==,以生成应该出现的下一个标记的概率列表。
- 给每个词汇表产生一个概率。
- ### [[LLM 预训练]]ChatGPT的训练
- 1750 亿个权重如何确定?通过对人类巨型语料库进行大规模训练得出。
- 如何训练网络?用数据进行学习,模型生成下一个词并与输入数据进行差值计算,得出损失函数,再通过反向传播最小化损失函数。这个过程经过上万次的迭代,并且每次迭代,所有的权重都会发生微小的变化。
- 生成下一个词
- ==当我们使用 ChatGPT 生成下一个词时,是所有权重的一次计算==。虽然在 GPU 中可以并行计算,但在训练时所需要的计算步骤是生成的 n²,所以预训练的费用才更贵。
- ### Funtuning在基础训练之外[[后训练]]
- 微调:
- 经过预训练后的模型只需要很少量的调参就可以表现得非常好。因为所有的知识都在里面了,我们只是告诉它“我们想要的内容的轨迹”
- 神经网络的算法限制:
- 神经网络可以执行一些简单的规则,并且执行的很好。但如果是非常有“深度”且复杂的规则,神经网络不能完成地很好,因为本质上它只是在网络中向前馈送数据。但是神经网络可以使用**工具**,就像人类一样。
- 例如,给 ChatGPT 使用Wolfram|Alpha和Wolfram语言,它可以在“不可约”计算上表现得更好。
- ### language 真正让ChatGPT发挥作用的是什么
- 人们高估了语言的复杂性,通过 ChatGPT 可以得出结论,学习人类语言似乎对于机器来说是简单的
- gpt 通过大量的语料学习到了人类的语法规则,虽然它并不知道规则是什么,但可以模拟正确语法生成句子。==就像母语一样,我们并不是先学规则后学说话,而是从出生就接收外界大量的语音输入,自然习得母语。==
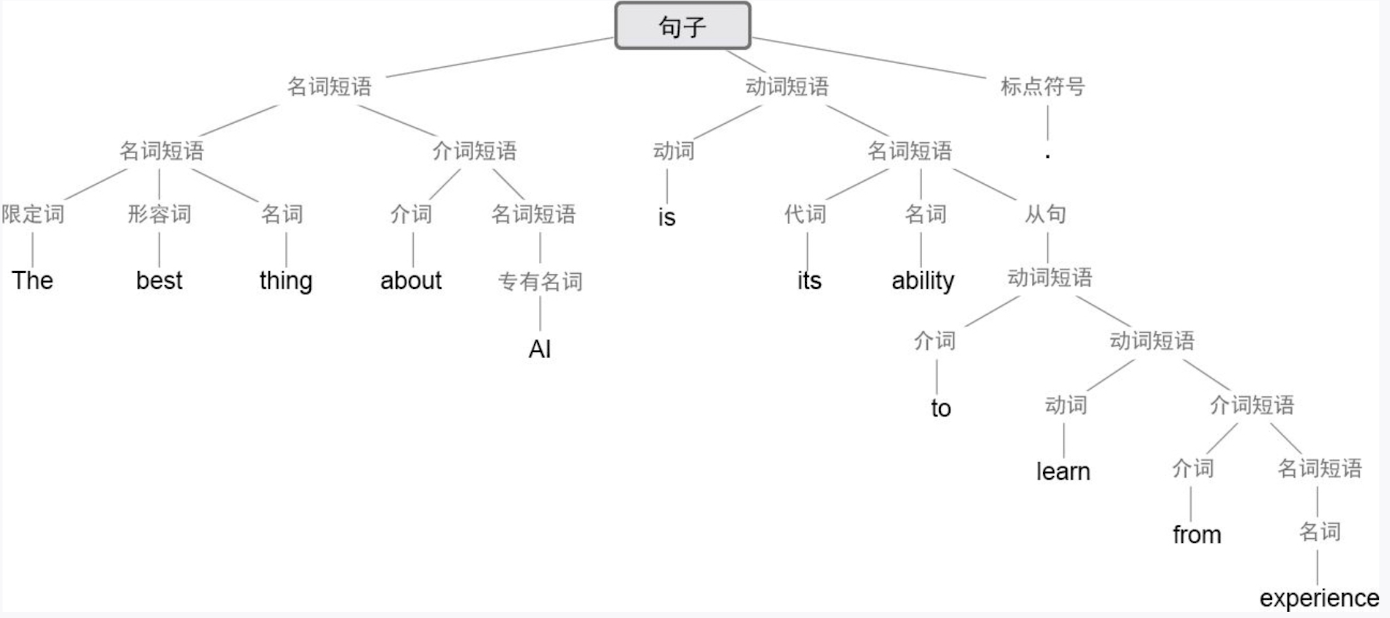
- > 一个关键的“类自然科学”观察结果是,神经网络的Transformer架构,就像ChatGPT中的这个,好像==成功地学会了似乎在所有人类语言中都存在(至少在某种程度上是近似的)的嵌套树状的句法结构==。
- 
- ChatGPT 不仅学会了正确的语法,还知道生成哪些内容是对人类来说==合理的==,原因也许是因为训练数据是来自真实世界的互联网,ChatGPT 隐含的发现了人类语言中的**逻辑**。可以说亚里士多德发现[[三段论]]也是通过研究了大量文本后发现的,ChatGPT 做了同样的事。
- > “Inquisitive electrons eat blue theories for fish”(好奇的电子为了鱼吃蓝色的理论)。—— 这是一个语法正确,但非人类会说的话,gpt 不会生成这样的内容。
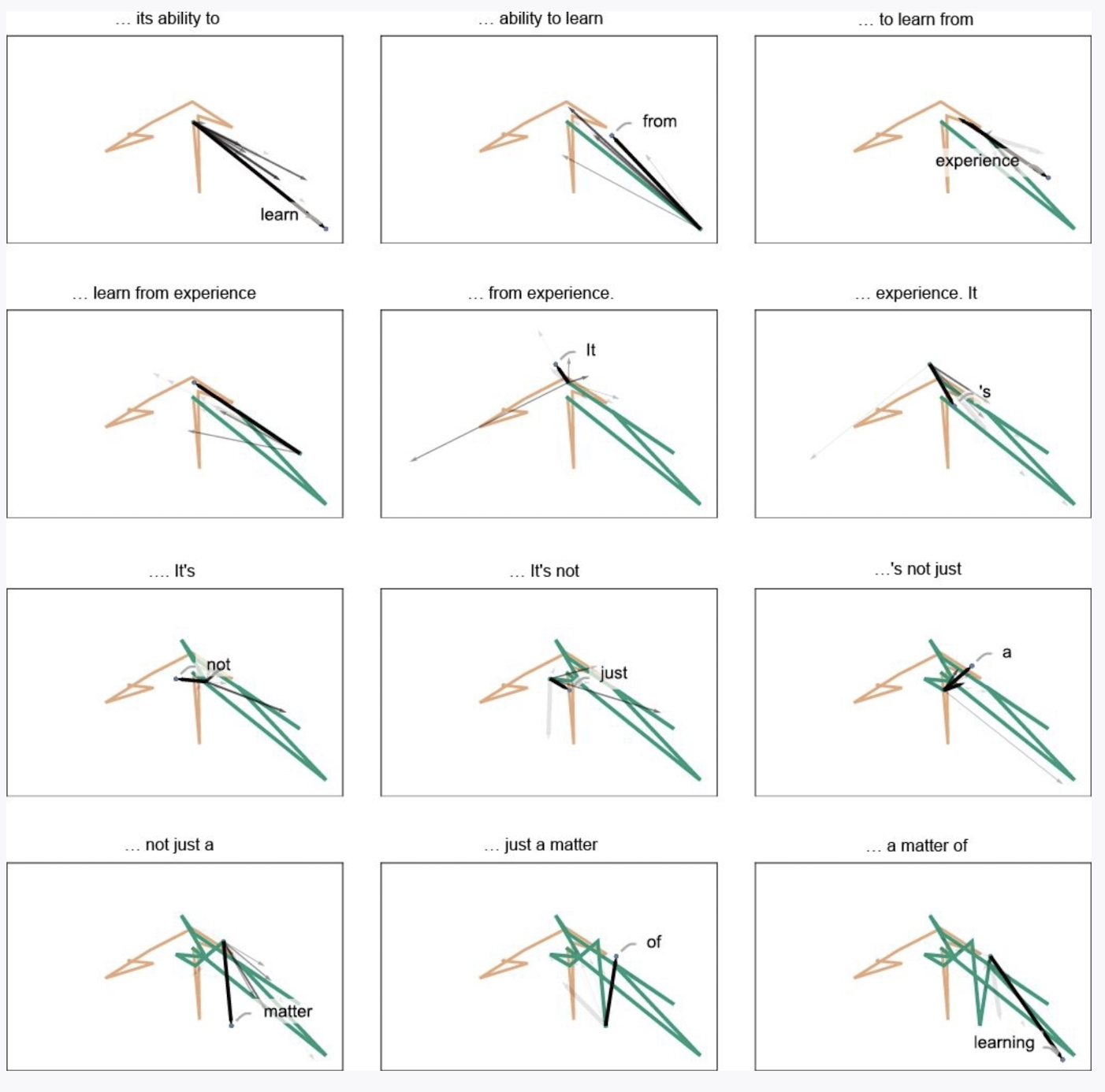
- ### semantics [[语义空间]]和语义运动定律
- 在 ChatGPT 内部,由高维向量组成的空间可以被看作是一个语义特征空间,每次生成一个 [[tokenization|token]]可以看作是在这个空间中的一次语义运动。
- 
- 
- ### world model语义语法和计算语言的力量
- **句法语法**是关于词的构建,基于不同词性的词提供了构建规则的树状结构。
- 但是**语义语法**必须基于一个==真实的世界模型==才能构建。
- > “The elephant traveled to the Moon”(大象去了月球)
- 这句话的语法没问题,语义也能理解,但就是在现实世界中还没有成真。
- 几世纪前,人们就发现[[人类语言]]并不是构建世界模型的唯一方式,还可以通过[[数学]]来构建世界模型,但现在有了更通用的方法:[[计算语言]] - Wolfram 语言。
- chatgpt本质上不仅仅是语言模型,也是**知识大模型**
- ### 那么,ChatGPT 到底在做什么?它为什么能做到这些?
- [[ANN 人工神经网络|神经网络]]本质上就是对人类大脑的建模。ChatGPT 就是在模仿人类生成语言时的大脑运作方式。
- # HOW GOOD
- [[计算不可约理论]]
- ilya:与伊尔亚·苏茨克维在多个访谈里强调的“GPT的大思路是通过生成来获取世界模型的压缩表示”异曲同工。
- 那么,人类还剩下些什么优势呢?根据“计算不可约性原理”(即“总有一些计算是没有捷径来加速或者自动化的”,作者认为这是思考AI未来的核心),复杂系统中总是存在无限的“计算可约区”,这正是人类历史上能不断出现科学创新、发明和发现的空间。所以,人类会不断向前沿进发,而且永远有前沿可以探索。同时,“计算不可约性原理”也决定了,人类、AI、自然界和社会等各种计算系统具有根本的不可预测性,始终存在“收获惊喜的可能”。人类可贵的,是有内在驱动力和内在体验,能够内在地定义目标或者意义,从而最终定义未来。
- GPT 的回答是基于神经网络对人类文本的理解和概括,是对全部人类文本的有损信息压缩
- 概念是对一系列具象**事物**进行高度压缩的结果
- 《一种新科学》
- 书中的主要观点是:万事皆计算,宇宙中的各种复杂现象,不论是人产生的还是自然中自发的,都可以用一些规则简单地计算和模拟。Amazon上书评的说法可能更好懂:“伽利略曾宣称自然界是用数学的语言书写的,但沃尔弗拉姆认为自然界是用编程语言(而且是非常简单的编程语言)书写的。”
- 利用 Wolfram|Alpha系统,可以对知识进行计算
- 大模型进化树
- [[Decoder-Only]]: 带自回归的 Encoder-Decoder架构
- GPT-1的论文发表之后,OpenAI这种有意为之的更加简单的Decoder-Only架构。GPT技术路线的一大核心理念,是用最简单的自回归生成架构来解决无监督学习问题,也就是利用无须人特意标注的原始数据,学习其中对世界的映射。自回归生成架构,就是书中讲得非常通俗的“只是一次添加一个词”。这里特别要注意的是,选择这种架构并不是为了做生成任务,而是为了理解或者学习,是为了实现模型的通用能力。
- GPT 技术的一大核心理念,是用最简单的自回归生成架构来解决无监督学习问题,也就是利用无须人特意标注的原始数据,学习其中对世界的映射。自回归生成架构,就是书中讲得非常通俗的“只是一次添加一个词”。
- Encoder-Decoder:
- Encoder-Only:非自回归的 Decoder 架构
- 引发思考
- 产生“有意义的人类语言”需要什么?过去,我们可能认为人类大脑必不可少。但现在我们知道,ChatGPT的神经网络也可以做得非常出色……我强烈怀疑ChatGPT的成功暗示了一个重要的“科学”事实:有意义的人类语言实际上比我们所知道的更加结构化、更加简单,最终可能以相当简单的规则来描述如何组织这样的语言。
- 突然想通了 savage 总是在说的一些关于英语学习的话:“英语的语法很基本,关键是概念量的积累。”对于 ChatGPT 来说正是这样,它从海量的互联网数据中自然习得了各种语言的句法语法。但它之所以能力惊人是因为它是用全世界的知识进行训练的人工神经网络。所以对于娃来说,关键就是能否通过感兴趣的主题(内驱力的来源)进行大量且高质量的输入,语言是自然能够学会的,关键在知识。而用英语学习是因为 96% 的信息都来自于英语,是最流通的语言货币。
- # ref.
- [陈老师笔记](https://readwise.io/reader/shared/01jh4g8g33d55mc2tycc0ykyvc)
- # archive
![[f54ca04a2fdc01ae363c03fe4c7c5623.jpg]]
![[IMG_8207.jpg]]
![[IMG_8206.jpg]]