**标题:大语言模型是如何学会理解人类语言的?注意力机制解释**
上一篇文章,我们学习了什么是 Embedding:将人类自然语言文本切分成以 token 为单位的词元,并将这些 token 映射到一个高维空间中,相近语义的词在这个空间中距离较近。例如 GPT-3 中的嵌入空间维度高达 12,288维。
## 什么是注意力机制 attention
在Embedding 步骤中,每个 token 的向量位置都是固定的,但在我们的日常用语中,通常会有同一个词在不同语境中会有不同的含义的情况,例如:
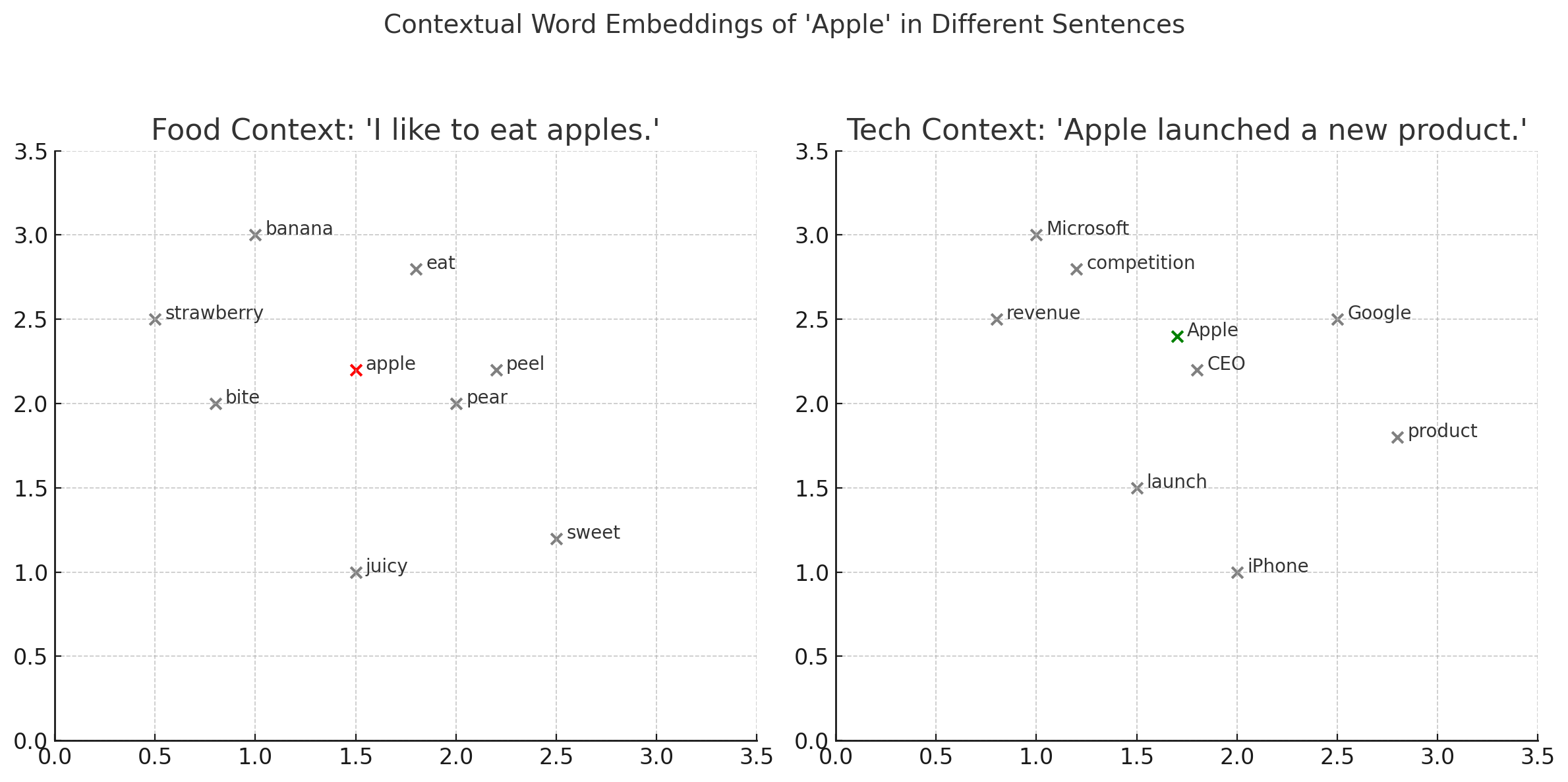
- 我喜欢吃苹果。
- 苹果公司发布了新产品。
这两句话中“苹果”的含义完全不同。在高维嵌入空间里,第一句中的“苹果”周围可能是“香蕉、梨子、西瓜”,而第二句中则可能靠近“iPhone、电脑、微软”等词。
因此,大语言模型要真正理解语言,就必须能基于上下文调整每个词的含义位置。这正是**注意力机制**要做的事情。
## 注意力机制如何帮助理解上下文?
我们还是想象一下高维空间中的情况,每个 token 有一个初始位置,但经过注意力模块后,这个 token 会根据**上下文**发生位置偏移。例如:
- 如果在 Harry 这个词之前看到的是巫师、霍格沃兹、赫敏,那么模型会将 Harry 理解为《哈利波特》中的人物。
- 如果在 Harry 之前看到的是女王、萨塞克斯郡、威廉姆,那么模型会将 Harry 理解为哈里王子。

不仅在短语中,即使在很长的文章或故事里,模型也能根据前后文精准地判断每个词的含义。例如,给模型一个推理故事,最后一句话说"因此凶手是",这里的"**是**“将基于编码前面所有内容的信息来生成最后一个词。此时的”是“与Embedding初始位置的”是“一定有很大的偏移。

注意力机制与之前的LSTM 长短期记忆模型不同之处在于:LSTM是按序串行处理文本,逐个 token 处理时,只能根据之前处理过的 token 来理解当前 token,难以远距离捕捉上下文信息;而注意力机制在计算上可以并行地同时处理所有 token,能够高效地捕获上下文中的长距离依赖关系,使模型更好地“理解”每个词的含义。
## 注意力机制是如何工作的?
注意力模块的目标就是在上下文长度内找到哪些词与哪些词相关,然后将相关的上下文含义编码到嵌入向量中,获得基于上下文的理解。下面用一句简单的英文句子作为例子:
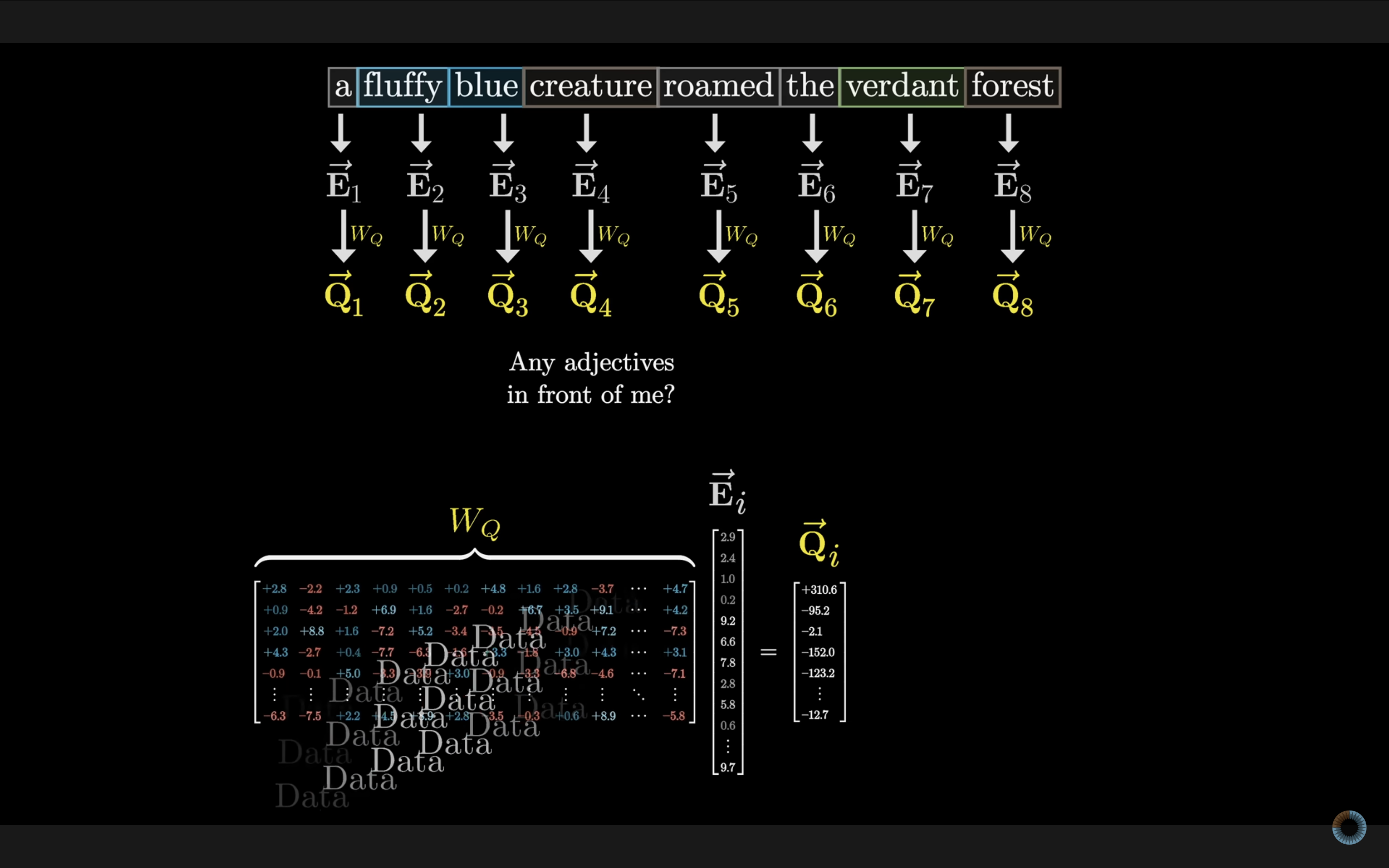
> a fluffy blue creature roamed the verdant forest
_这个例子仅仅是为了演示注意力机制是如何工作的,而模型在实际训练当中要复杂的多。_
如下图,我们的目标是让形容词(fluffy、blue、verdant)将它们的语义信息传递给对应的名词(creature、forest),实现上下文理解。

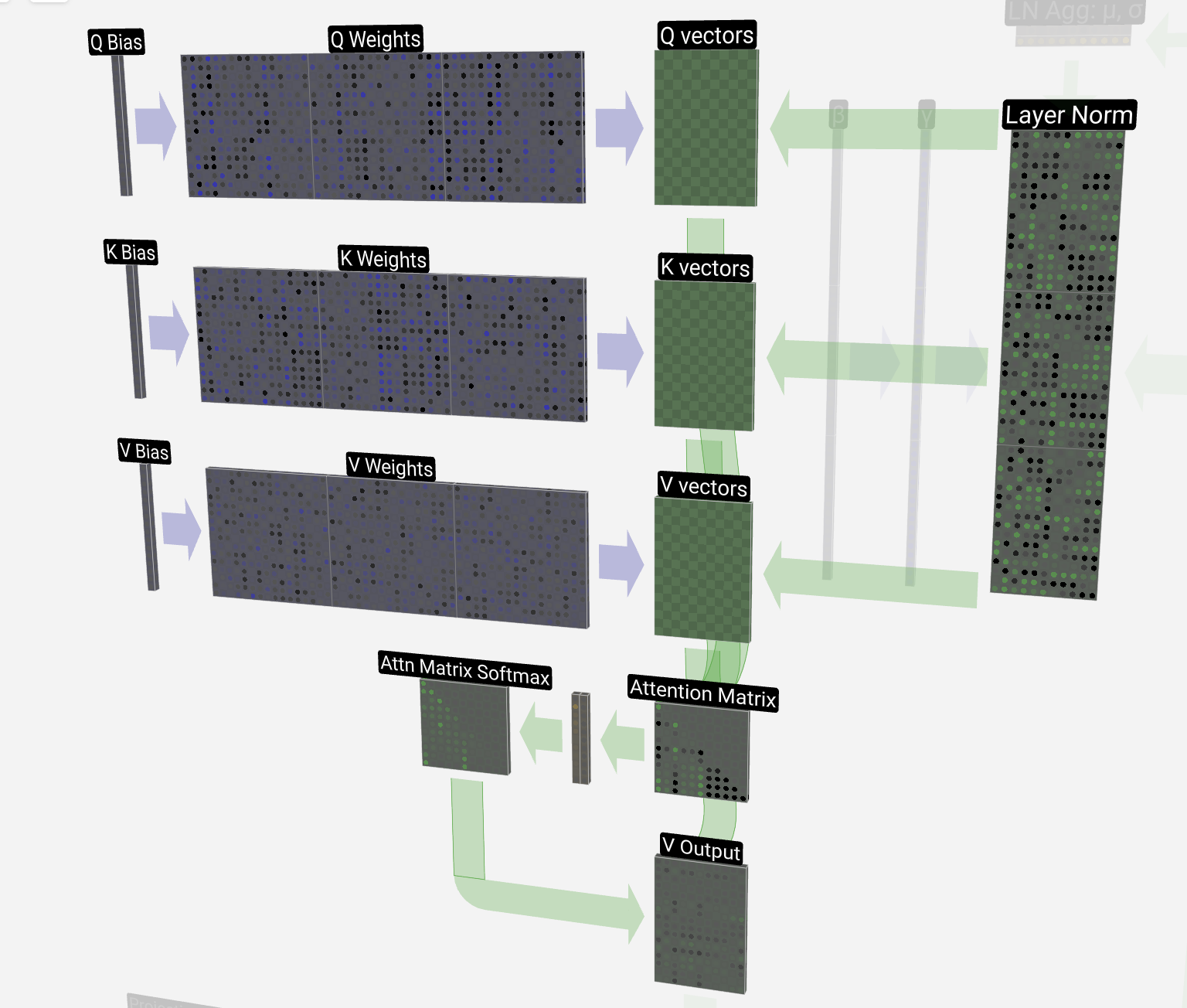
注意力模块使用三种矩阵:**Query(查询)、Key(键)** 和 **Value(值)**。这些矩阵与词嵌入向量相乘,分别得到 Q 向量、K 向量和 V 向量。
### 计算注意力权重
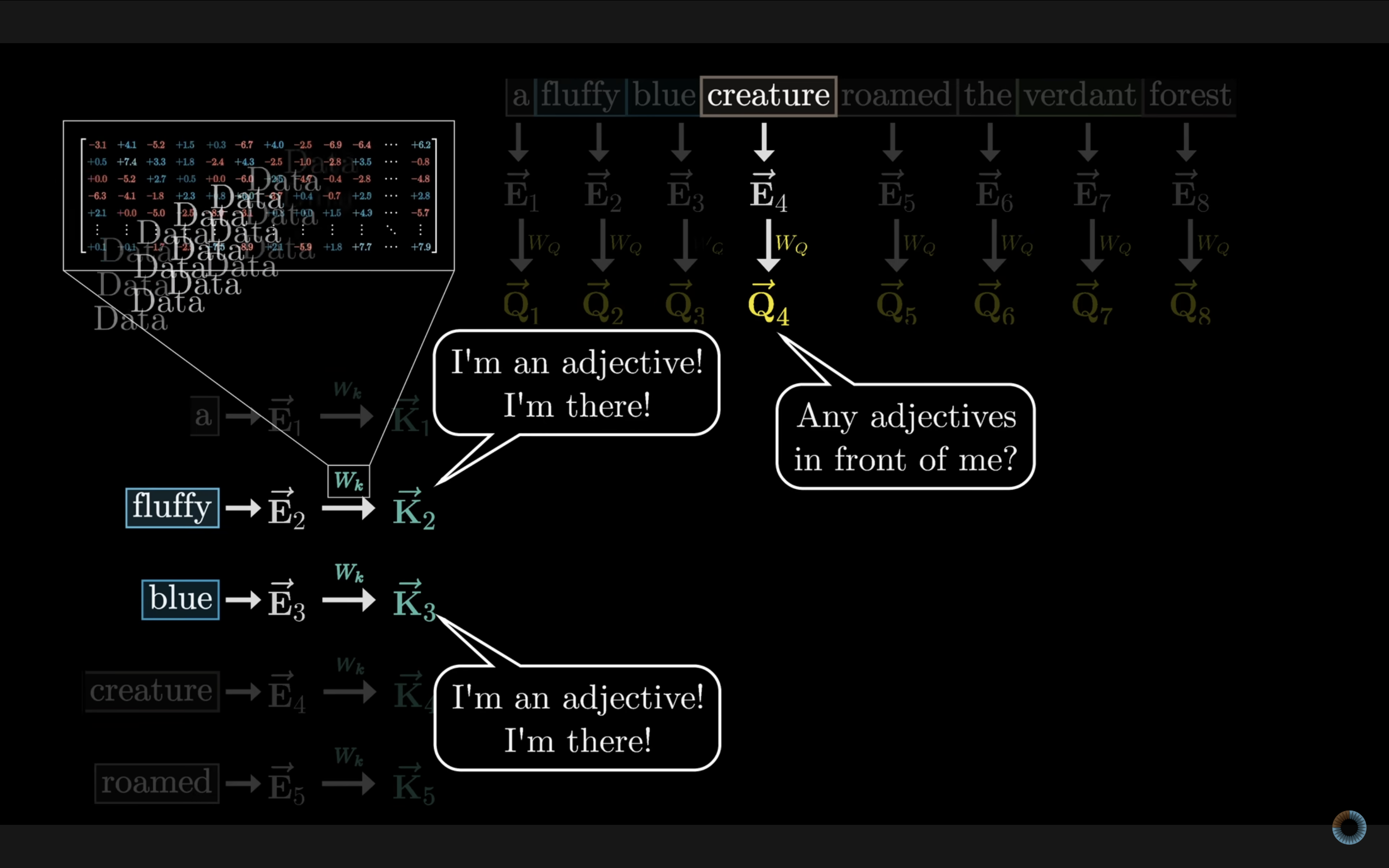
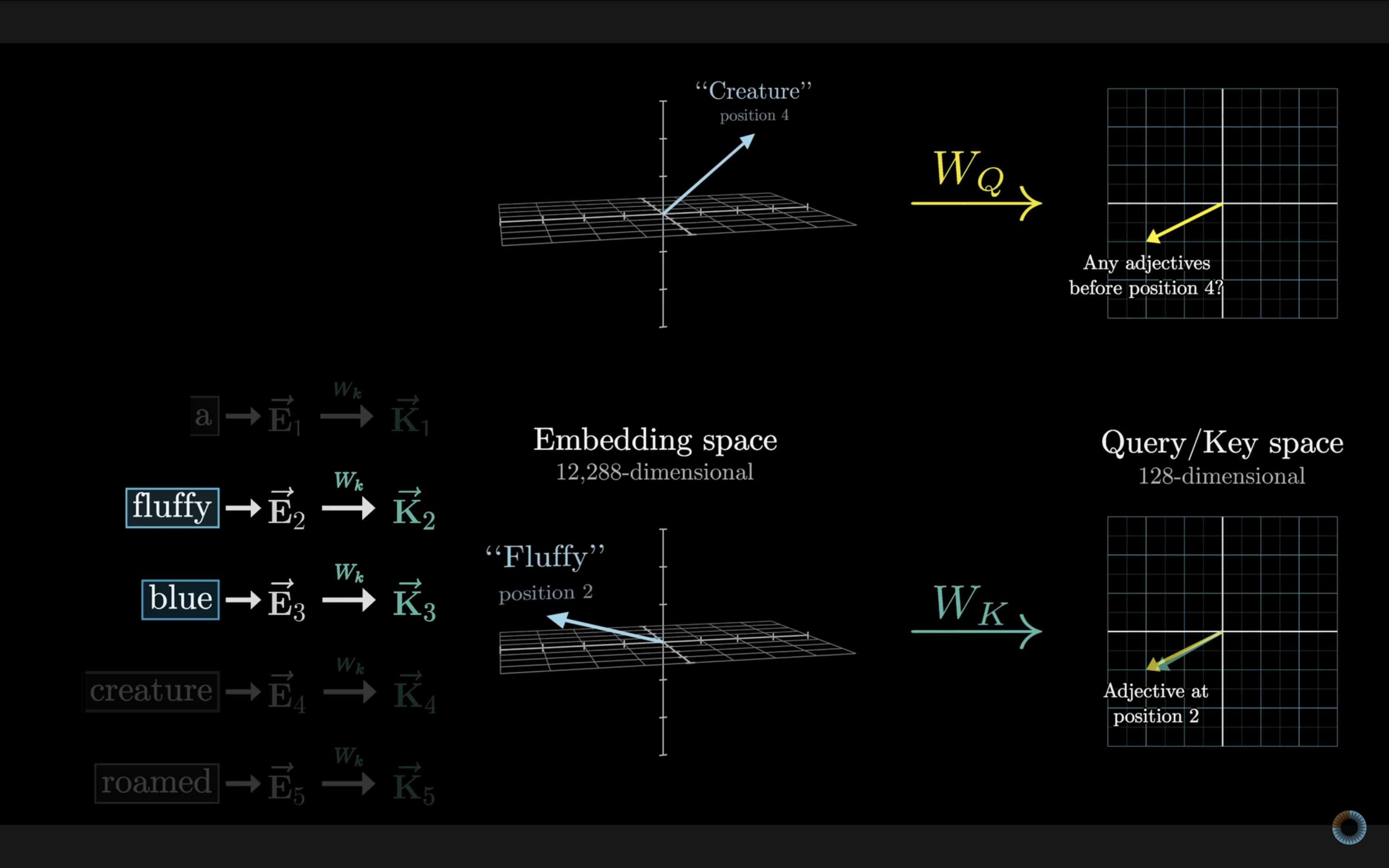
在嵌入环节,模型不仅嵌入了每个 token 的语义,也嵌入了每个 token 在上下文长度中的位置(**position embedding**)这些位置信息在 Query 环节发挥了作用。Query 向量就好比是一个提问者,会问哪些词与我相关。例如在这句话中“ a fluffy blue creature roamed the verdant forest”,好比 creature 在问:“我的前面有形容词吗?” 这个问句以某种形式被嵌入到 query 向量中。
另一方面,我们同时会得到一组 Key 向量。 Key 向量就好比是 Query 向量的答案,此时的“fluffy”和“blue”回答 “creature” 提出的问题:“我是形容词!我在这里!”
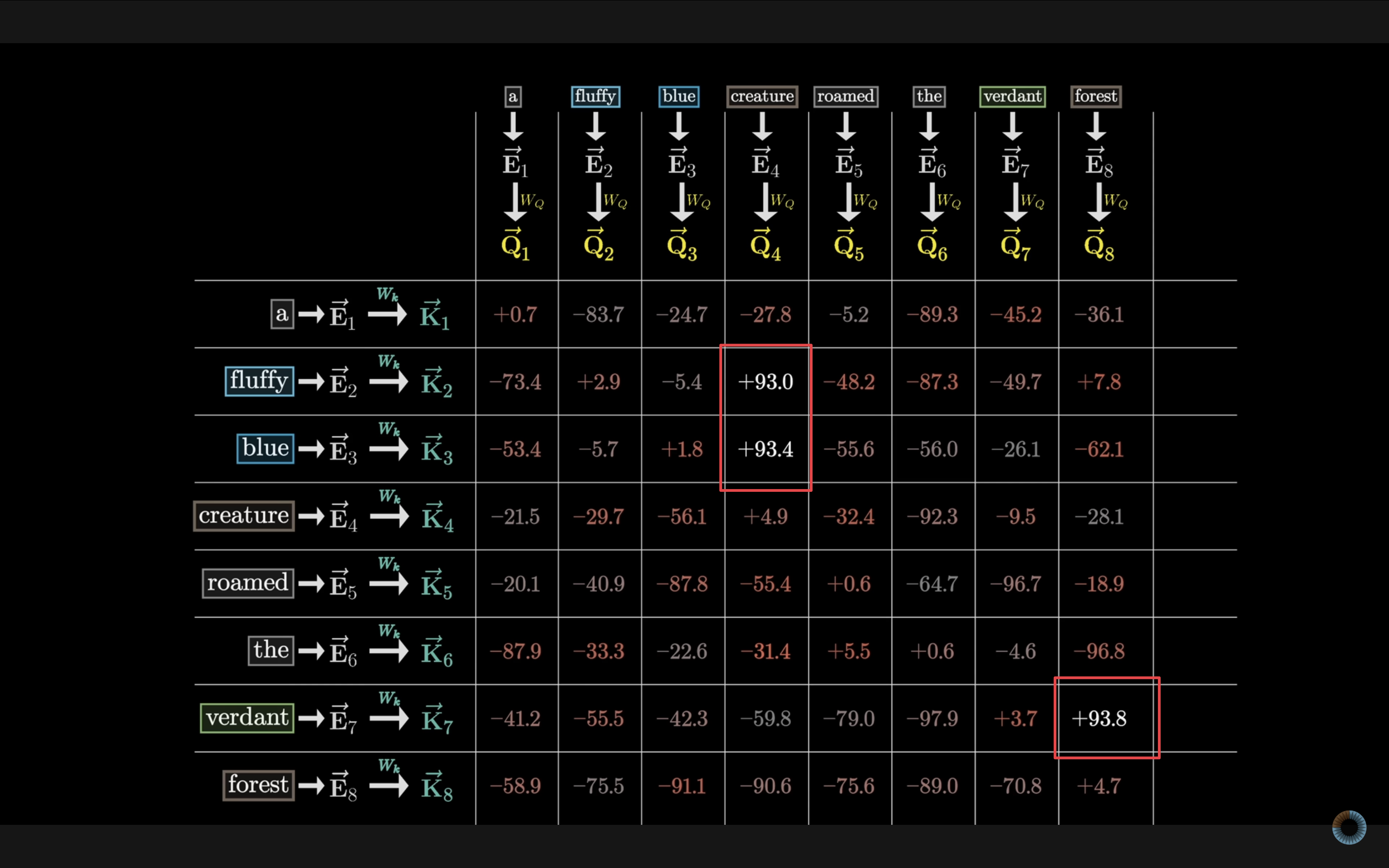
接下来,通过计算每个 Query 向量与所有 Key 向量之间的**点积**,判断词与词之间的相关程度。点积值越大,表示两个词之间越相关。如果压缩到一个二维平面来看,相关性高的 Q–K 对会聚在一起。
在本例中,则是 fluffy 和 blue 的值最大,说明这两个词与 creature 最相关。
接下来对点积矩阵按列做 Softmax,Softmax 函数会把这些任意实数压缩到 0-1 区间内(仍以浮点格式存储),并使每列的值之和为 1,从而得到一组概率权重。
### 使用 Value 向量更新含义
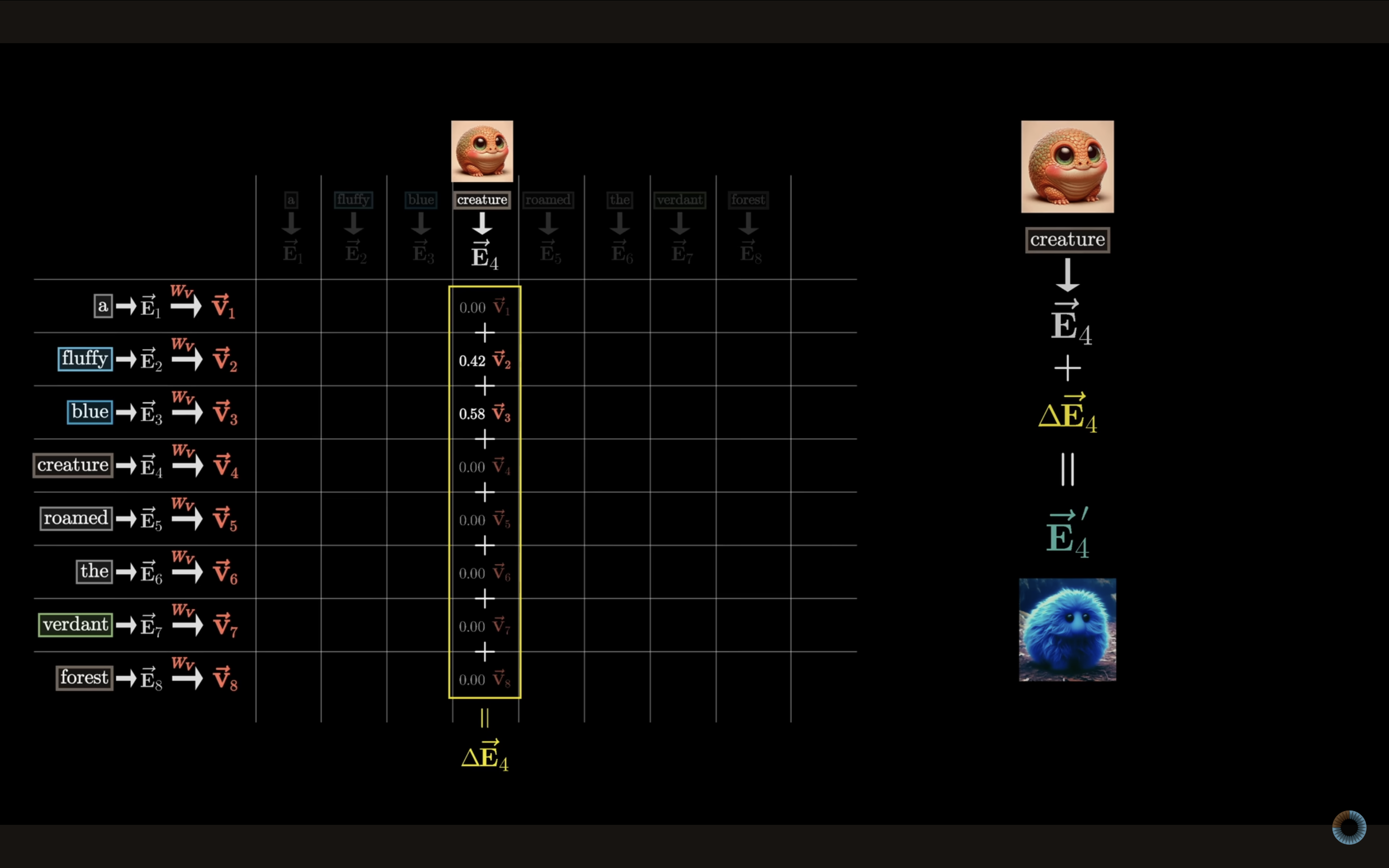
此时,我们已经知道了哪些词与哪些词相关(**Attention Matrix Softmax**)。下一步是利用这些相关性来更新词的含义位置。
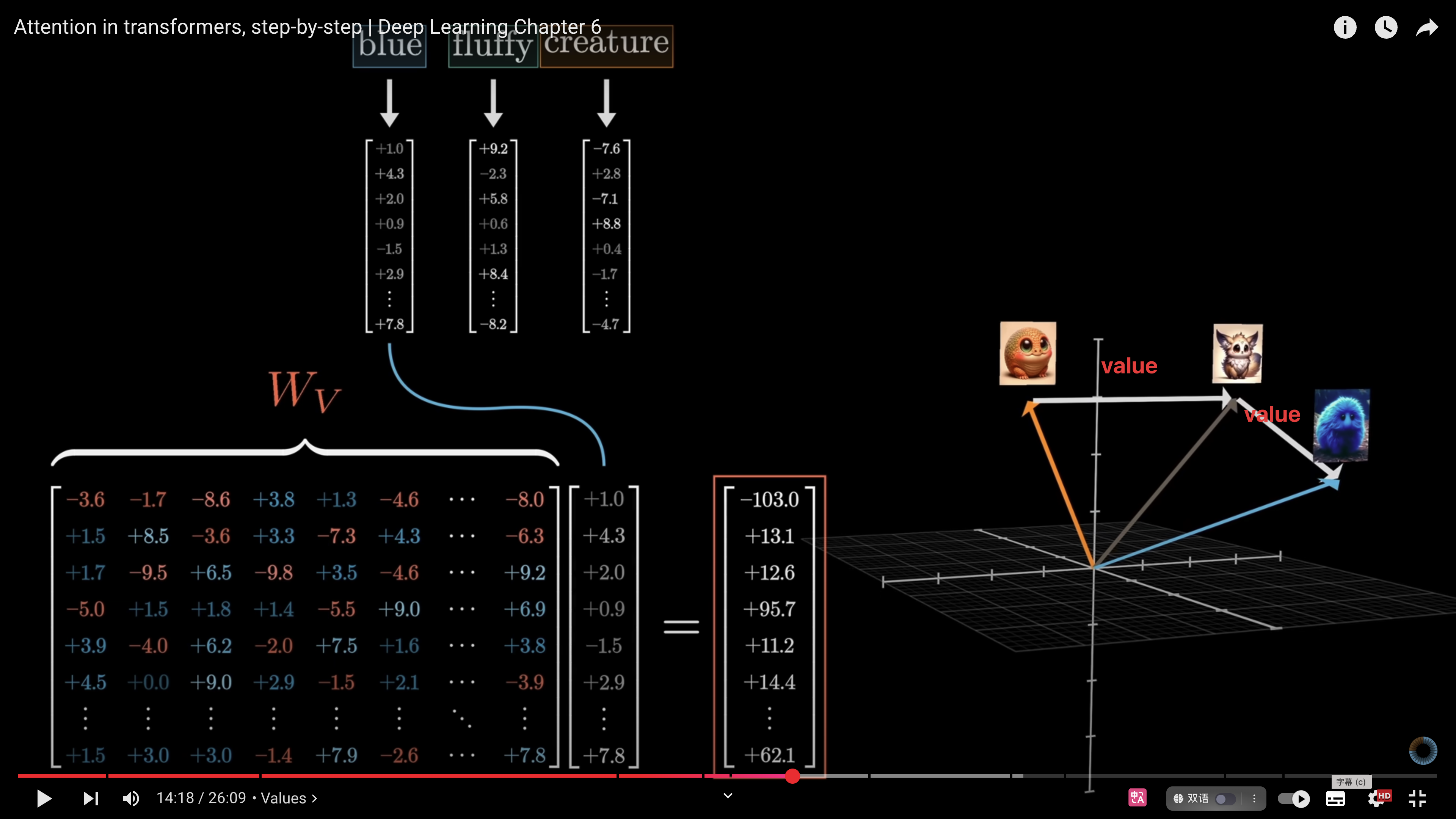
例如,我们希望 fluffy 和 blue 能够影响到 creature,把 creature 的嵌入向量向“蓝色、毛茸茸生物”的方向移动。
具体做法是:用刚才计算出的注意力权重对所有 token 的 V 向量进行加权求和,得到一个改变量 ,再把这个改变量加到 creature 原本的嵌入向量 中,形成新的含义向量 ,表示“蓝色、毛茸茸的生物”。**在这个过程中,fluffy 和 blue 因为权重最大,对最终含义影响最明显。**
完整的注意力公式为:
- 每个 QK 点积都除以是为了保持数值的稳定性。
至此,我们便完成了根据上下文调整词义的全过程。
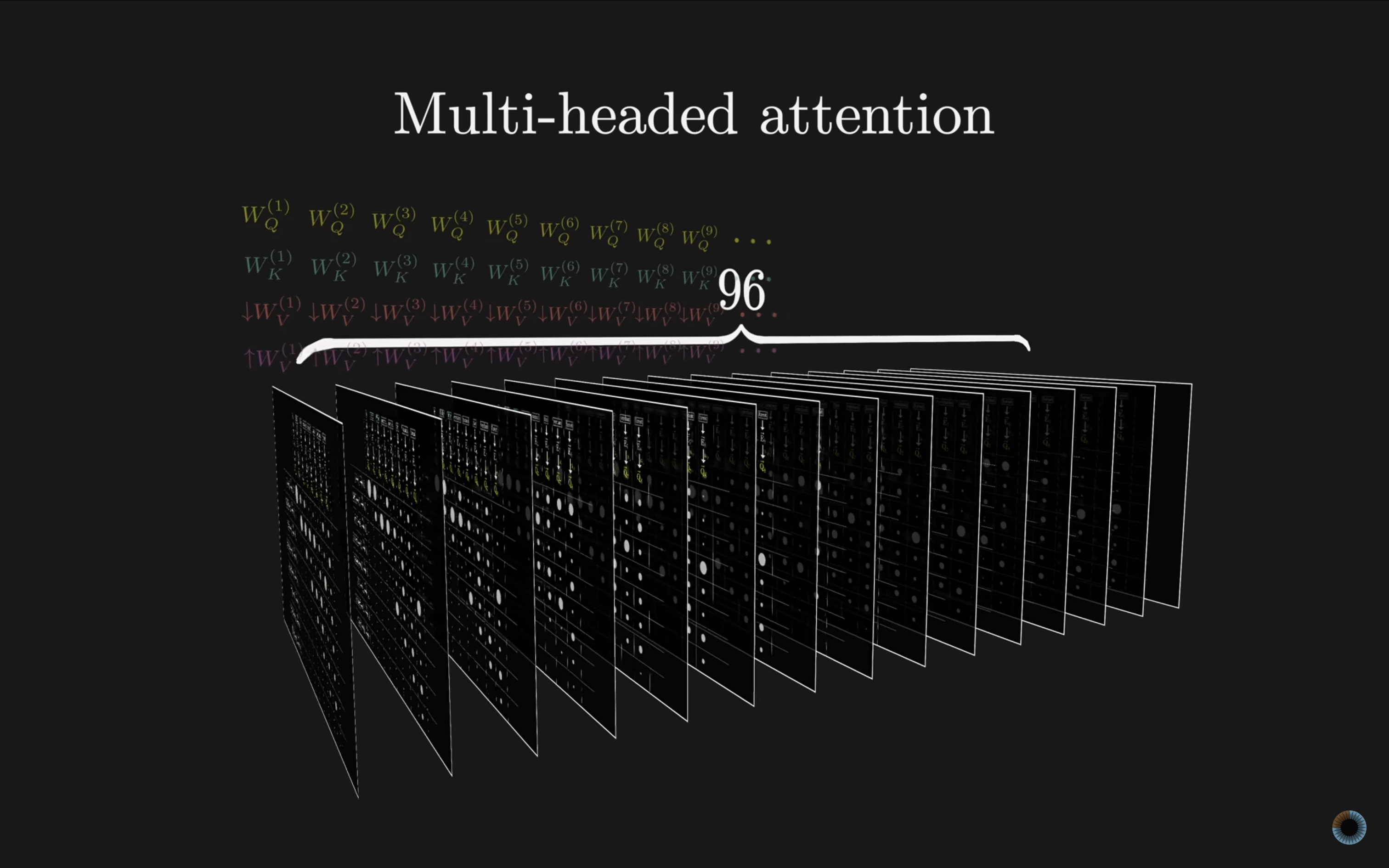
## 多注意力头 Multi-headed attention
以上的实例展示的是**单个注意力头**的计算方式。实际的 Transformer 模型则更加复杂,它会同时运行多个这样的注意力头(例如 GPT-3 每层 96 个头),每个头都有各自独立的 Q、K、V 矩阵,分别关注不同的语义角度。
这意味着你有 96 套不同的Q矩阵和K矩阵,产生 96 种不同的注意力模式。然后,每个头都有自己独立的V矩阵,用来生成 96 组值向量序列。相当于每个头独立计算并提出各自的含义更新建议,最后再汇总到一起,形成更全面、更精准的语义表达。
## AI 的“理解力”与人类的差别
我们知道 transformer 实际上是一个具有深层神经网络,并且能够对海量的数据进行**特征学习** Feature learning和**模式识别** Pattern Recognition的人工神经网络。
以 GPT-3 为例,它有 96 个这样的网络层,一个词语的理解经过 96 个注意力头后还要再乘上 96 个层。这意味着,在一个单词吸收了一些上下文信息之后,还有更多机会让它变得更加精确。网络层次越深,每个嵌入向量就从所有其他嵌入中汲取越来越多的含义,而那些嵌入本身也变得越来越细致。这种模式赋予了模型更高层次,更抽象的**理解力**。
对比于人类阅读时,我们也是在根据已有知识预测下一个词或后续内容。我们通常依赖**长期记忆**和短期记忆(**工作记忆**)协同工作,抓取关键词,建立上下文的理解链条。但由于个体知识背景不同,理解能力也有局限。
相比之下,大语言模型可以借助万亿参数(人类全部知识作为长期记忆)和数千甚至上万个 token 的上下文长度(工作记忆),基于一万多维度**特征**来进行理解。
虽然 AI 并非人类意义上的“理解”,但确实能做到在更广泛、更精细的维度上理解了人类的语言。
这真的是一件神奇的事情......
## Ref.
- Attention in transformers, step-by-step: https://www.youtube.com/watch?v=eMlx5fFNoYc&t=1274s