# todo
- [ ] 符号主义、符号人工智能?
## 人工智能的起源
人类很早就开始思考什么是智能。智力 intelligence 源于拉丁语 nouns *ingelligentia*,意味理解或感知,可以被描述为感知或推断[[信息]]的能力。
人工智能之父艾伦·图灵曾在自己的论文《计算机器和智能》中提出一个问题:“机器会思考吗?”(Can Machines Think?)并且,图灵给出了创造一个 thinking machine 所需的 2 个元素:感知Perception和对含义的理解和推断能力(Understanding and Inference of Meaning)。
感知具体可以指视觉、听觉,当今的图像识别、语音识别等技术都是源于机器对于感知这一目标的追求。对含义的理解和推断能力即语言和推理能力,这一元素要求机器不仅能够获取和处理数据,还需要对这些数据的含义进行理解、推断和决策。
1968-70 年,一位名叫Terry Winograd的科学家将图灵的这一设想在一个叫[[SHRDLU]]的自然语言理解程序上进行了实践。Terry Winograd提出“一个人要理解世界”需要具备以下几点:
- perceive the world:感知世界
- syntax understanding:需要对世界的结构做一个理解 (syntax 在语言里是指句法结构、在视觉领域通常指[[三维结构]])
- semantics:理解含义
- inference:进行推理
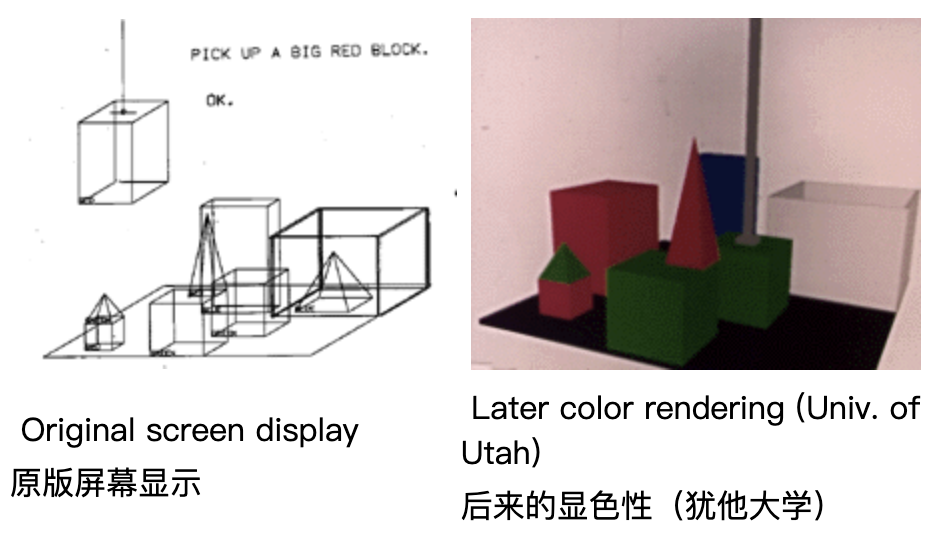
基于以上的几个要素,Terry 创造了一个虚拟积木世界(the BLOCKS world),人类可以通过电传打字机与 SHRDLU 进行简单的对话。部分内容如下:
> Person: PICK UP A BIG RED BLOCK.
> 人物: PICK 向上一个大红色的块。
> Computer: OK. (does it)
> 计算机:好的。
> Person: GRASP THE PYRAMID.
> 人物:抓住金字塔。
> Computer: I DON'T UNDERSTAND WHICH PYRAMID YOU MEAN.
> 电脑:我不明白哪个 你是说金字塔。
> Person: FIND A BLOCK WHICH IS TALLER THAN THE ONE YOU ARE HOLDING AND PUT IT INTO THE BOX.
> 人物:找一个更高的块 比你拿着的那个,然后把它放进盒子里。
> Computer: BY "IT", I ASSUME YOU MEAN THE BLOCK WHICH IS TALLER THAN THE ONE I AM HOLDING.
> 计算机:我猜是“它” 你的意思是比我拿着的那个高的块。
> Computer: OK. (does it)
> 计算机:好的。
> Person: WHAT DOES THE BOX CONTAIN?
> 人:盒子里装的是什么?
> Computer: THE BLUE PYRAMID AND THE BLUE BLOCK.
> 计算机:蓝色金字塔和 蓝色块。
> Person: WHAT IS THE PYRAMID SUPPORTED BY?
> 人物:金字塔支持什么?
> Computer: THE BOX.
> 计算机:THE BOX。
> Person: HOW MANY BLOCKS ARE NOT IN THE BOX?
> 人:有多少块不是 在盒子里?
> Computer: FOUR OF THEM.计算机:四个。
Terry人工编写了 SHRDLU 的所有程序,但是这种[[符号人工智能]](按照人类工程师制定的程序指令hand-designed rules运行)的方向最终失败了,以至于他离开 MIT 实验室后,SHRDLU程序频繁报错。而导致符号人工智失败的原因主要是基于:
- **scalability 可扩展性**:
- 人类编写的程序不可能预测可能出现的全部规则,所以SHRDLU在开放世界中的表现不佳,因为它依赖于预定义规则。例如,在 SHRDLU 的积木世界中,如果引入一种新的形状(比如圆柱体),而程序中没有定义相关规则,SHRDLU 将无法理解和处理这个新对象。
- **adaptability可适应性**:
- 同一套规则如果换一个事物就失效了。比如,在 SHRDLU 中,处理“放置积木”的规则是基于积木的方形几何形状设计的。如果将规则应用到一个非标准的形状(如圆柱体或不规则形状)上,程序将无法适应这种变化,就像英语的语法结构无法直接应用到中文一样。
- **closed world 虚拟世界**:无法在真实世界里工作,比如积木世界就是一个虚拟的环境,所有的物体都是标准的几何形状,并且实验室中的灯光从不会改变,但是放到真实世界的真实物体和复杂的光线中,人类编写的规则就失效了。
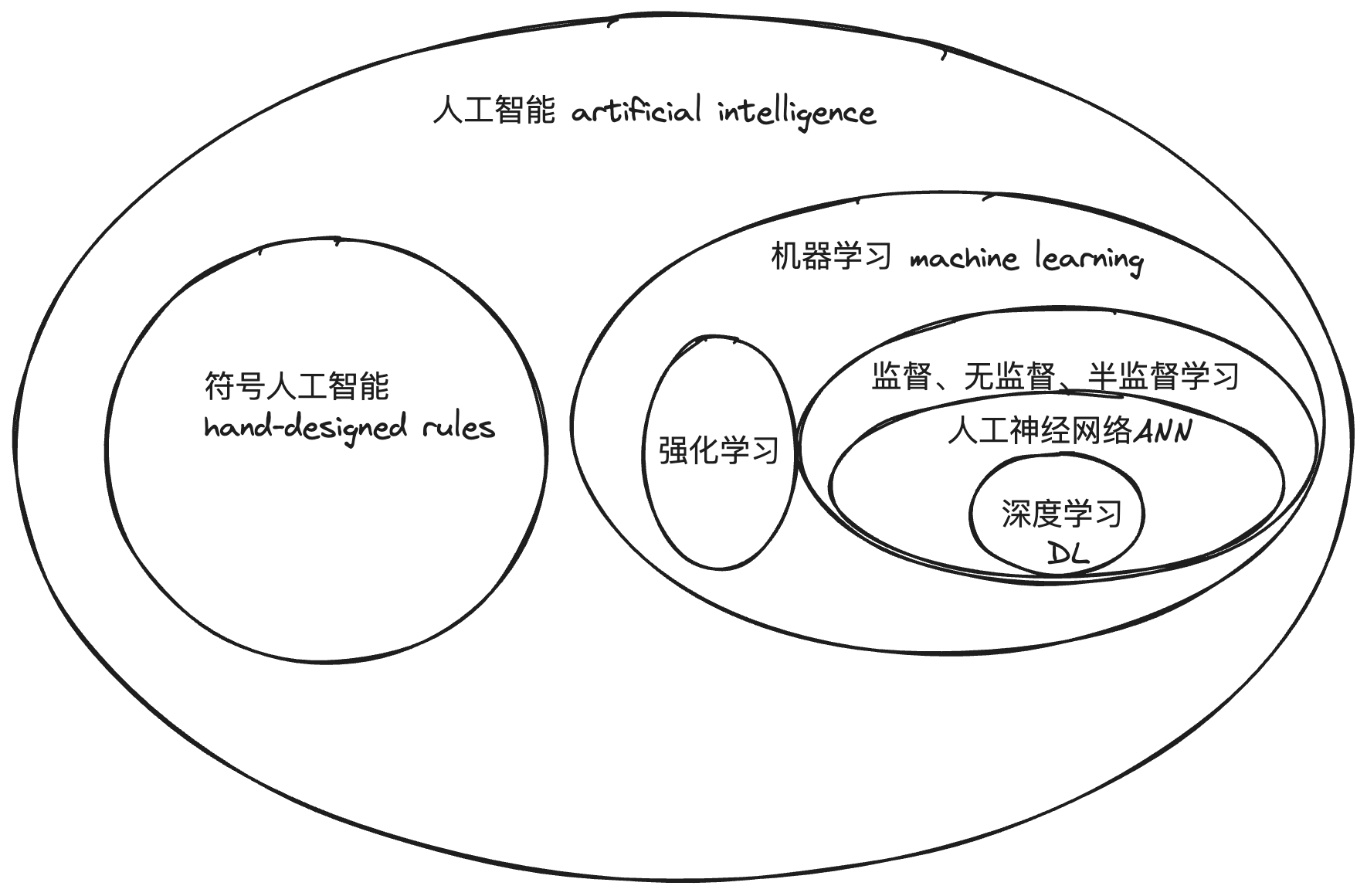
在这场人工智能派系的分歧与斗争中,代替符号人功智能的方法就是后来得到蓬勃发展的 **[[machine learning 机器学习]]** 。
## 机器学习与人工神经网络
机器学习是人工智能领域里的一个重要分支,与符号人工智能的最大区别是机器学习是用数据来训练数学模型,让机器自己学习。
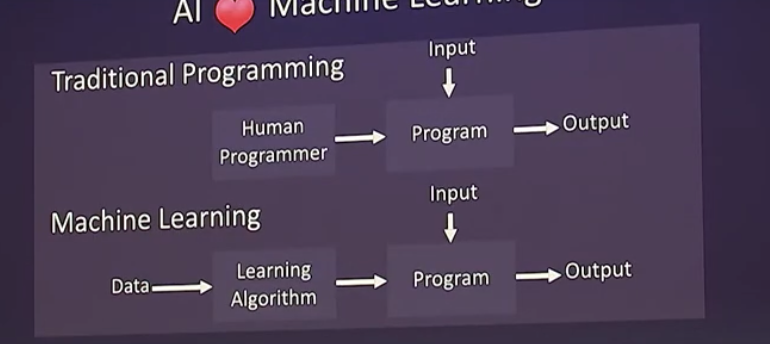
在人工智能学科成立的早期,有一部分科学家就相信人工智能机器就应像人类一样,拥有一个自主学习的系统。发明第一个人工神经元-[[perceptron 感知器]]的科学家弗兰克·罗森布拉特就是这样认为的。
感知器是人工智能历史上最早的[[ANN 人工神经网络]]之一,由弗兰克·罗森布拉特在 1957 年发明。
1960 年,感知器在一台叫做马克一号(Mark1)的计算机上使用,并展示于众。马克一号通过自主学习工程师们提供的字母卡片后,学会了识别一些英文字母。罗森布拉特还当场证明了机器是通过自主学习学会的,方法就是他拔掉了马克一号的几根电线,然后再重新上电后,机器变得很“笨”,但在看了更多的字母卡片后,又回到了断电前的水准。
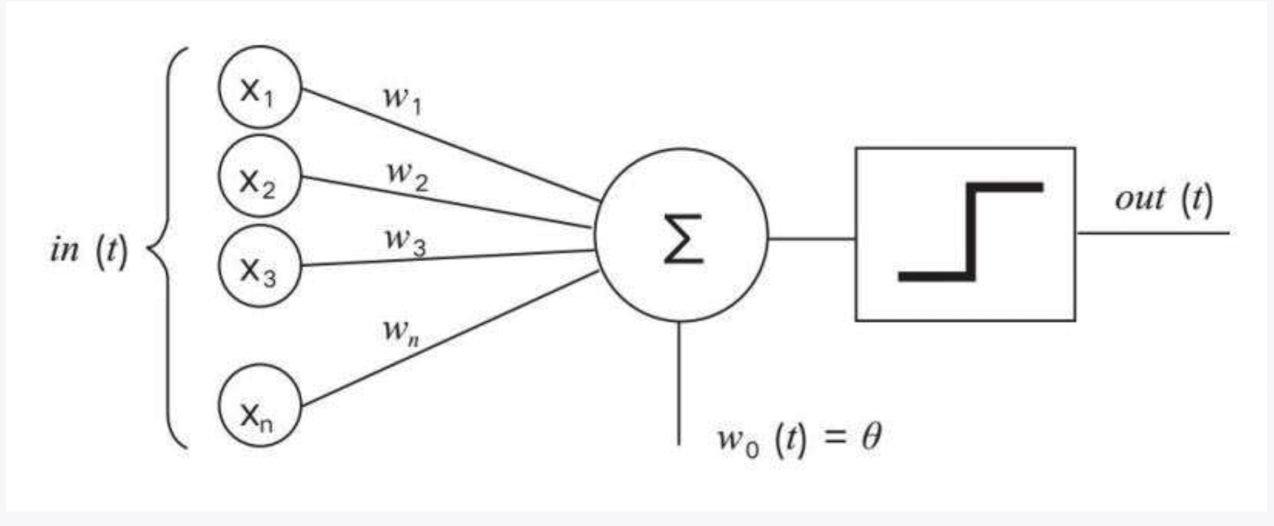
感知器是由一组输入层,和一组将输入层与输出层相连的连接组成。每个输入单元 x 与权重 w 相乘,求出的乘积的总和Σ与阈值θ进行比较后的结果传递给阶跃函数。如果总和超过阈值,阶跃函数输出 1,否则输出 0。
从感知器的工作原理我们可以得知的是,感知器仅能解决线性问题,即是或否的问题。这一问题成为了将人工神经网络送进了**第一个10年寒冬**的原因。1969 年,符号人工智能倡导者马文·明斯基与一名叫西摩·佩珀特的 MIT 同事共同撰写了《感知机》一书,书中提到感知器无法处理[[异或 XOR]] 问题(非线性可分问题)。
举个例子:当纸板上有两个点时,感知机可以告诉你两个点是否都是黑色,或者是否都是白色,但是不能告诉你“它们是不同的颜色吗?”尽管当时,包括罗森布拉特在内的研究人员已经在探索解决这一问题的方法了,但还是因为这本书出版的原因导致了许多研究者对感知器的能力产生了怀疑,资金和研究兴趣减少,最终人工神经网络领域成为了未来十年冷板凳上的常客。
## 辛顿与反向传播算法
最终,克服了罗森布拉特感知机的局限性的方法是[[Backpropagation 反向传播算法]]的发明,由[[Geoffrey Hinton 辛顿]]和大卫·鲁姆哈特共同提出。
杰弗里·辛顿是深度学习领域非常重要的开创者之一。自幼喜欢观察冷血动物的辛顿就提出过一个问题:”动物是如何思考的?“并在十几岁时,辛顿就确立了自己的兴趣,研究大脑。但是在上世纪 60 年代,人类并不是很清楚自己的大脑是如何工作的。辛顿辗转于大学里的各个学科都没有结果,于是离开了学术界,成为了一名以木工为生的木匠。直到 1972 年,他在父亲任教的爱丁堡大学参加了一个人工智能项目。**辛顿认为人工智能是测试他提出的关于大脑是如何工作的理论的一种方式。**

罗森布拉特认为,解决感知器的局限问题的方法是建立一个多层神经网络,信息能够从上一层传递到下一层,这样的系统可以学习到单层感知器无法学习的复杂事物。加州大学圣迭戈分校的大卫·鲁姆哈特提出,如果要打造一个多层神经网络,首先要解决的问题是权重问题,因为对于多层神经网络,改变一个神经元的权重,意味着要改变所有依赖于这个权重的神经元。鲁姆哈特认为,需要一种将每个权重和其他权重结合起来的方法,他给出的答案就是“反向传播”的过程,使用[[gradient descent 梯度下降]]来优化网络权重。而这种方法的另一个问题是,如果将所有的权重都设置为零,那么最终每一个权重都会落在同一个地方。
在这样的情况下,鲁姆哈特提出了新的想法:“如果初始权重随机设置会怎样?”辛顿与鲁姆哈特一起实验了这种新的方法并且成功了。反向传播算法解决了当年马文明斯基提出的异或问题,它能够回答“它们是两种不同的颜色吗?”。
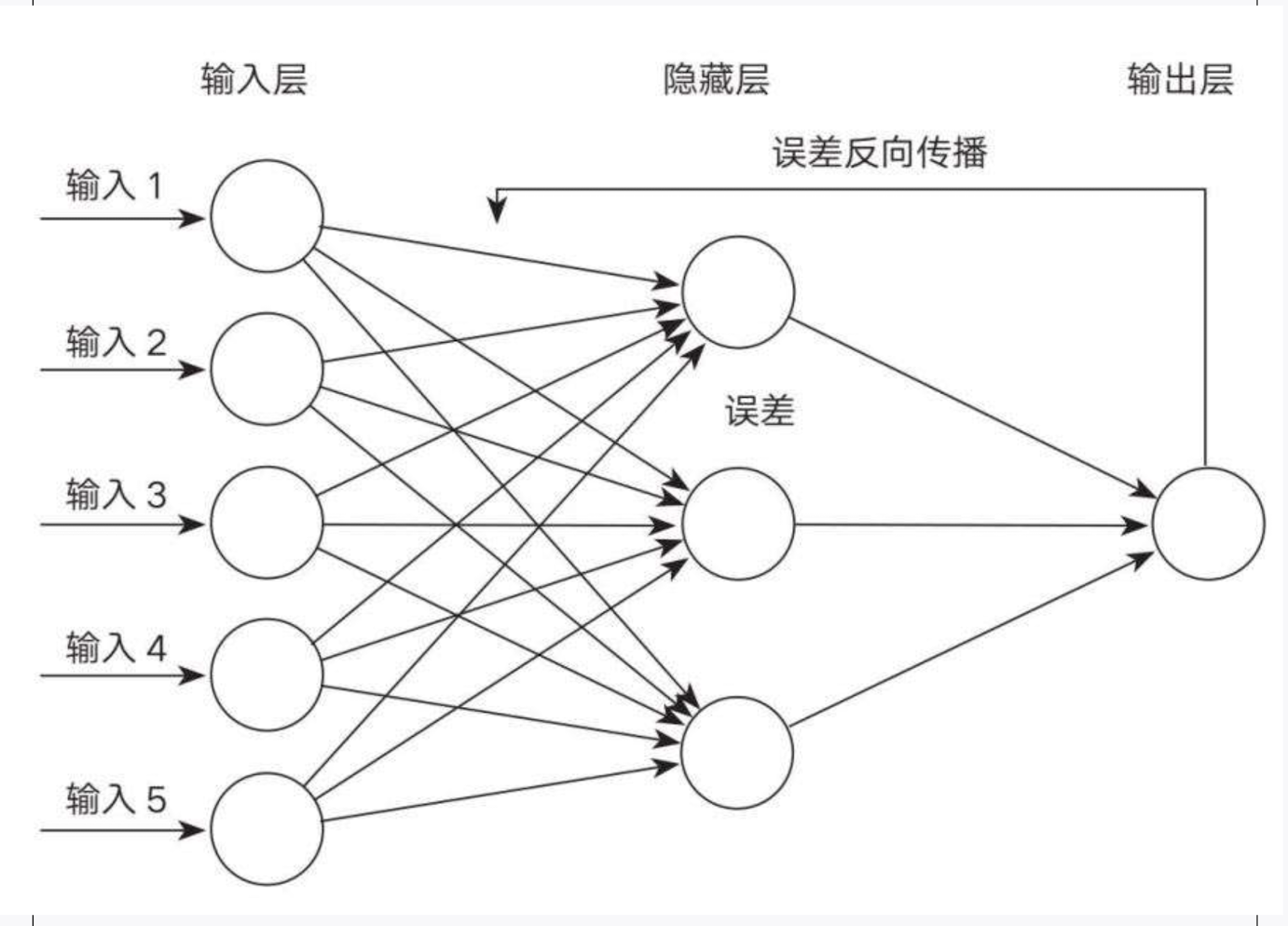
1986 年发布的反向传播论文是人工神经网络的一个重要时刻,将神经网络带入了一个短暂乐观的新时代,而且因为大量投资的引进,反向传播算法也有了实际的应用。其中最具影响的是 1989 年,辛顿的学生[[Yann LeCun 杨立昆]]利用反向传播算法和美国邮政部门提供的大量手写笔迹数据创建了 LeNet 系统。20 世纪 90 年代中期,美国超过 10%的支票读取系统是由 LeNet 完成的。
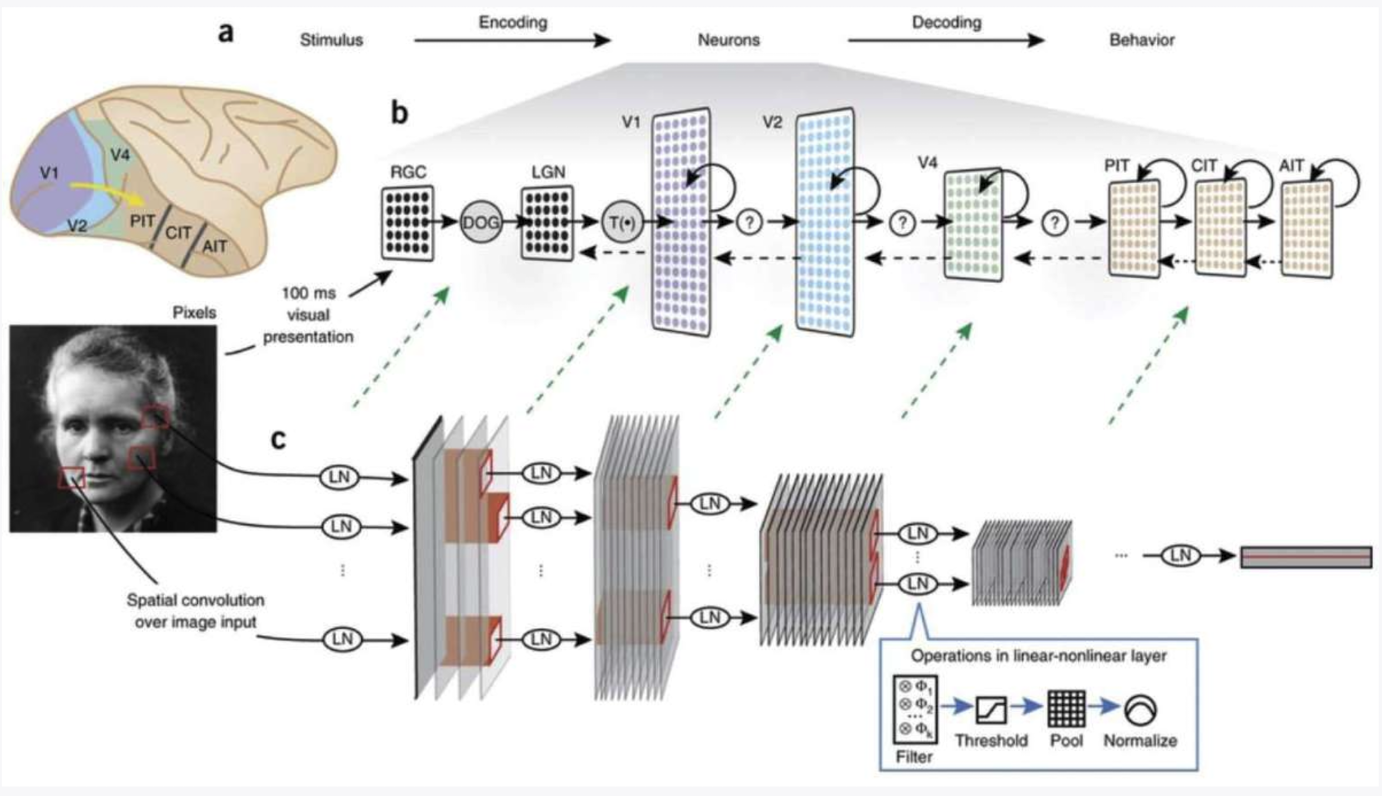
## CNN 卷积神经网络与视觉皮质
1998 年,Hinton 和杨立昆在[[Backpropagation 反向传播算法]]的基础上进行优化,发明了[[CNN 卷积神经网络]]。
卷积神经网络受到动物的视觉皮质启发,架构类似于动物视觉皮质的层次结构。视觉是我们身体当中最敏锐的感官,我们的大脑皮层中有一半的部分是负责视觉的。在 1/10 秒内,视觉皮层中的 100 亿个神经元在并行工作,能够让我们立刻识别出眼前的东西,并支配我们的判断与行为,卷积神经网络则模仿了大脑的运行方式。
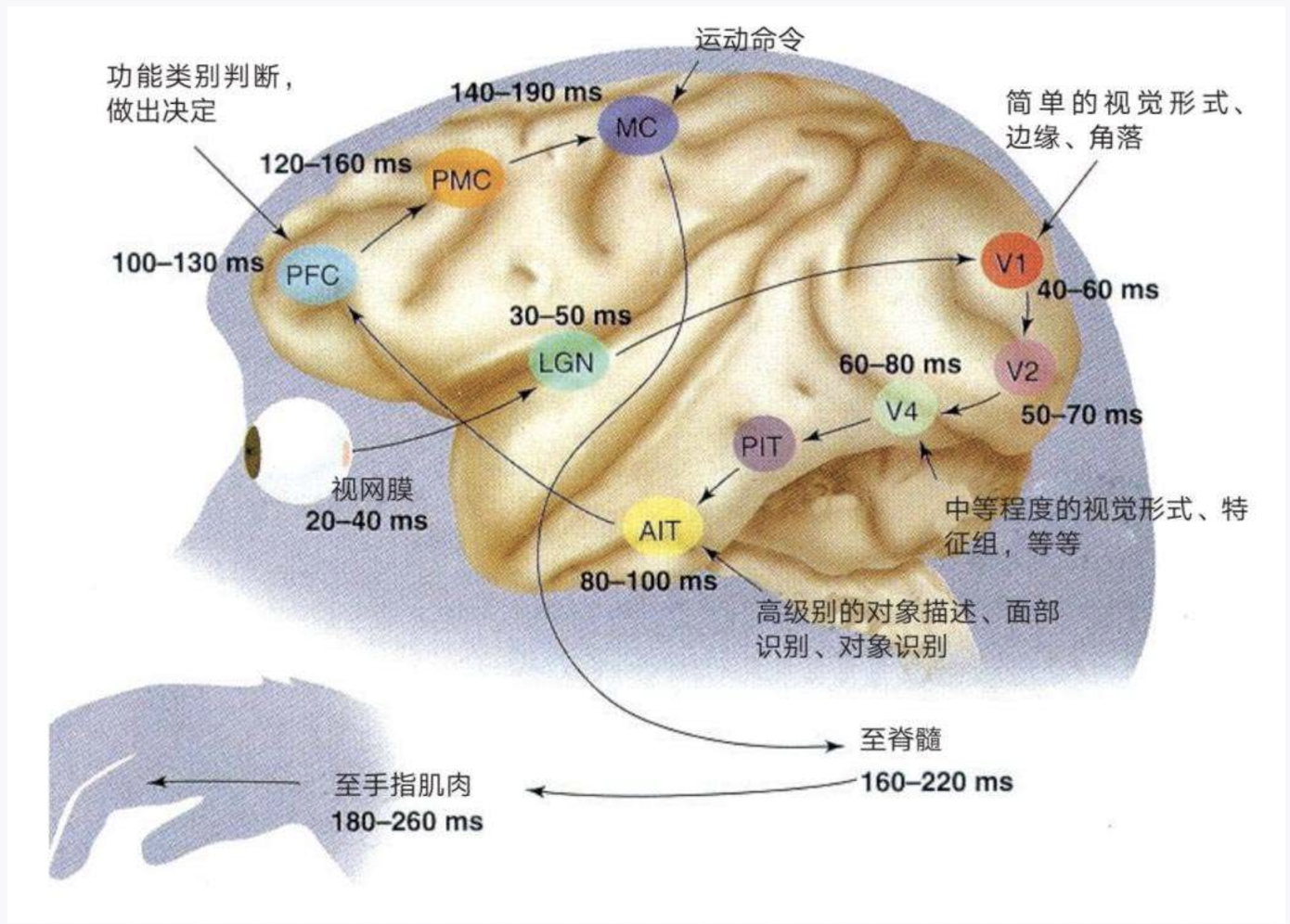
一项对猕猴下额叶皮层的研究图说明了视觉皮质是如何处理光信号的:
- **视网膜 (Retina)**:视觉处理的起点,光线在这里被转化为神经信号。处理时间为 **20-40 毫秒**。
- **V1 (初级视觉皮层)**:皮层处理视觉信息的第一个阶段,==处理简单的视觉特征,如边缘和角度==。处理时间为 **40-60 毫秒**。
- **V2**:处理更复杂的特征,如==轮廓和纹理==。这个阶段的处理时间为 **50-70 毫秒**。
- **V4**:进一步处理视觉信息,涉及==颜色和形状==。处理时间为 **60-80 毫秒**。
- **AIT (前下颞皮层)**:处理更==复杂的物体识别==任务和面部识别。处理时间为 **80-100 毫秒**。
- **PFC (前额叶皮层)**:负责决策和功能分类。处理时间为 **100-130 毫秒**。
- **MC (运动皮层)**:==发送运动命令以执行动作==。这个过程的时间为 **140-190 毫秒**。
同样,在 CNN 中有一个叫做滤波器的部分,一个滤波器为 3x3 的小方块,在图像中滑动的过程中提取特征。在一个卷积网络中会有多个滤波器,每个滤波器都会寻找不同的图像形状或特征。随着更加“深入”神经网络,滤波器越来越具备“抽象 abstract”能力。例如可识别一个房子中的窗、门、屋顶的形状,随着层级的加深,最终构建出全景图。
CNN 卷积神经网络是深度学习上的一个重要突破,但是在处理更加复杂的图像的过程当中表现并不理想,例如无法处理猫、狗、汽车的照片。从20 世纪 90 年代到 21 世纪的第一个十年,人工智能又迎来了第二次寒冬,直到 2012 年。
## 神经网络爆发
2012 年是深度学习的一个重要历史时刻,由杰夫·辛顿和他的两个学生亚历克斯·克里泽夫斯基(ilya)和伊尔亚·苏茨克维共同发表的 [[AlexNet]]参加了一个视觉识别挑战赛[[ImageNet]]竞赛。AlexNet 以错误率15.3% 胜出当年的比赛,比第二名低了 10.8个百分点。
其实AlexNet 本身就是卷积神经网络的迭代修改版本,但为什么AlexNet在 2012 年这个节点上一下子奏效了呢?这里有 3 点原因:
- 算法不断的优化和成长
- 数据的井喷
- 硬件的发展
在 AlexNet 这篇论文发表之前,辛顿刚刚从谷歌大脑(谷歌的人工智能研究实验室)回到多伦多大学,他非常清楚谷歌的[[小猫论文]]走错了路线。
小猫论文是由 Google Brain 于 2012 年发表的一篇论文,主要作者是吴恩达。论文题目为“Building High-level Features Using Large Scale Unsupervised Learning”,意在证明神经网络在大规模无监督学习的数据进行训练的潜力。小猫论文的数据来自于 YouTube 视频中的猫,并且这些图片从未被标记过。而训练神经网络的计算机芯片是 Google 数据中心的 16000 多块 CPU。
但是如果使用标记过的图像数据训练神经网络,那么模型会更加准确、可靠。 于是辛顿选择了当时数据量最大的标注视觉数据库[[ImageNet]]来训练 AlexNet,并且硬件上也选择了计算成本更高的 GPU,大幅提升了计算速度。这样的组合最终让AlexNet 获得了 2012 年 ImageNet 挑战赛的第一名。
AlexNet 改变了人们对深度学习的看法。截至 2024 年,AlexNet在谷歌学术上被引用超过 157,000 次。
不管是标记过的数据还是未标记过的数据,前提都是在互联网发明后的 20 年里积累到的足够训练神经网络的数据集:例如截至 2024 年,维基百科词条有 6000 多万条[1](https://meta.wikimedia.org/wiki/List_of_Wikipedias)[2](https://wikicount.net);截至 2023 年YouTube预估有 133 亿个视频[3](https://mp.weixin.qq.com/s/9z00U6dinw8D5Tlvawz4lw);还有截至2023 年,z-library上的 8480 万篇论文和 1335 万本书籍[4](https://en.wikipedia.org/wiki/Z-Library)。其他数据来自像 Google、Gihuhub、IMDB、Reddit 、stackoverflow等人类积累的数据也给训练神经网络提供了最佳的基础设施。
## 深度学习的命名
深度学习有过很多个名字。在 20 世纪 80 年代,没有科学家敢大声宣布自己在研究神经网络,因为这会被业内人士看作是疯了。在整个人工智能领域提交的论文中,有关神经网络的论文不足 5%,有些研究人员为了提高论文的成功率可能会使用“函数近似”,“非线性回归”等词来代替。就连杨立昆也曾把卷积神经网络中的“神经”删掉,变成“卷积网络”。还有其他的代替词包括 “PDP 平行分布式处理”、“连接主义”、“关联记忆”。
直到2007 年,辛顿在[[NIPS]]大会上对神经网络进行了一次成功的品牌重塑 - “深度学习 Deep Learning”,这里的“深度”指的是神经网络的隐藏层层数。
## 从深度学习到通用人工智能
吴恩达曾经告诉谷歌的创始人拉里佩奇:“深度学习不仅能够实现图像识别、机器翻译、自然语言处理,还能推动机器走向真正的智能。”(《深度学习革命》p74)这一宏大的理想也成为了 DeepMind 和 OpenAI 这样的公司的崇高愿景,打造通用人工智能[[AGI]]。
OpenAI的首席执行官Sam Altman 给出这样的定义:
> 一种与人类智能一样能力和灵活性的人工智能。AGI将具备学习、理解并将其智能应用于各种问题的能力,就像人类一样。
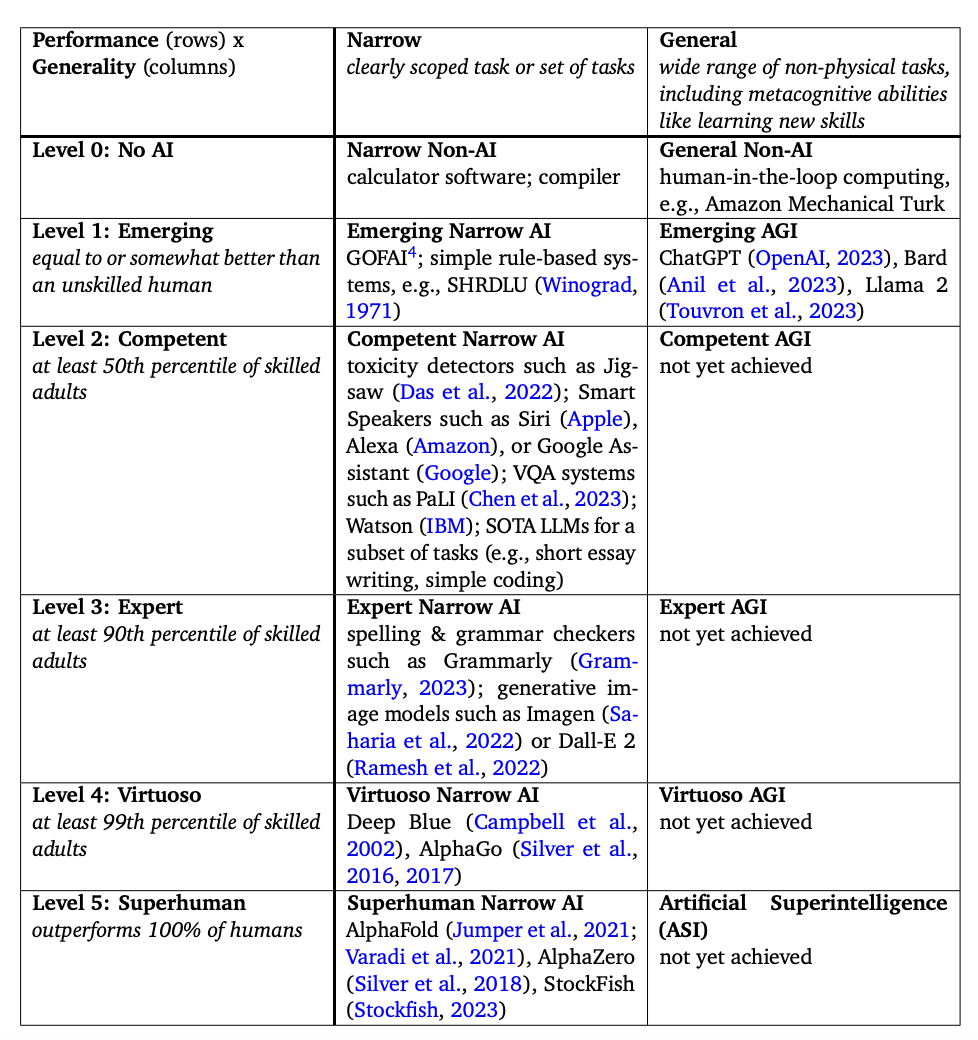
这样的人工智能与执行特定场景任务的狭义人工智能(ANI)成为对比。2023年11月4日,谷歌DeepMind联合创始人谢恩·莱格(Shane Legg)带领的DeepMind研究团队发布了论文,给出了AGI的清晰定义,并制定了AGI从L1-L5的分类框架:
- L0: 非AI
- L1 初级:等同于无技能的人类或比无技能的人类稍好;这个级别的AGI 如[[大语言模型]] ChatGPT, Bard, Llama;这个级别的 ANI 如[[SHRDLU]];
- L2 中级:超越50%有技能的成年人; 这个级别的ANI如Siri,Alexa,Waston(IBM);
- L3 专家:超越90%有技能的成年人;这个级别的ANI如 Grammarly;
- L4 大师:超越99%有技能成年人;这个级别的ANI如 [[AlphaGo]],打败人类围棋大师李世石。
- L5 超级智能:ASI(Artificial superintelligence)超过100%人类;这个级别的ANI如 AlphaFold,它在一个任务(从氨基酸序列预测蛋白质的三维结构)上的表现高于全球顶级科学家的水平。
从1956 年达特茅斯会议上确立了人工智能(AI)作为一门新的科学学科的那一刻起,一场人工智能革命已经拉开序幕。这场革命至今持续了 60 多年,2022年 11 月 30 日问世的 ChatGPT 更是这场革命的高峰时刻,让每一个人类都见证了人工智能就要来了。在这个历史变革时期,我觉得人工智能和我们每一个人都息息相关。
## 下一期预告
介绍实现了AGIL1级别的大语言模型。