# what
大语言模型(LLM)与推理模型在后训练阶段的主要区别在于,大语言模型采用的是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF),而推理模型则多采用纯强化学习(Reinforcement Learning, RL)。
# how
强化学习的灵感最初来自行为主义心理学。它通过让智能体在环境中不断尝试,通过环境给予的奖励(正反馈)或惩罚(负反馈),逐渐强化成功的行为,回避失败的行为。例如,在一个迷宫实验中,老鼠通过试错发现哪条路径有食物,哪条路径会受到电击,最终在奖励的驱使下选择正确的路径。
强化学习在机器学习领域的突破性应用由 DeepMind 在 2016 年实现。DeepMind 开发的围棋机器人 AlphaGo 击败了世界围棋冠军李世石,成为人工智能领域的重要里程碑。AlphaGo 最初使用人类棋谱进行监督学习,模仿人类职业棋手掌握基础技能,但该方法受限于人类棋谱的质量和局限性。随后推出的 AlphaZero 则完全抛弃了人类棋谱,直接通过纯粹的强化学习,自我对弈,不断探索和尝试新的棋路,最终实力远超人类棋手。
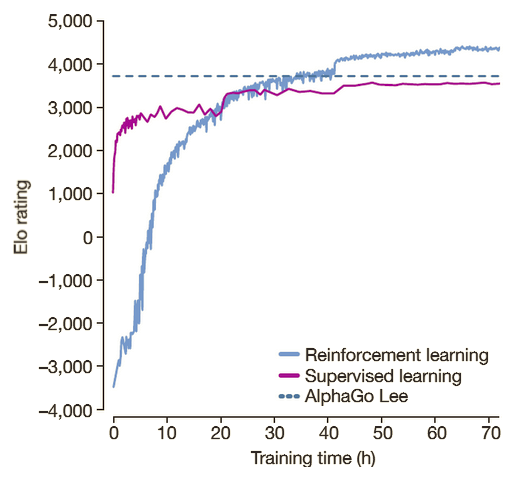
这张图来自DeepMind 在 《Mastering the Game of Go without Human Knowledge》的论文:
- **蓝色折线**:从零开始、自我对弈的 Reinforcement Learning (RL) 版本(AlphaGo Zero)。
- **紫色折线**:仅用人类棋谱做监督学习 (SL) 得到的网络。
- **青色虚线**:2016 年击败李世石的 AlphaGo Lee 固定 Elo 标杆。
- 图里 RL 曲线最初比 SL 弱,但短短 3 天(≈24 小时标记处)就追平并反超,40 小时左右已远超 AlphaGo Lee,远超任何一位人类大师。
这种强化学习的理念也被引入到推理模型的训练中。推理模型的训练过程类似人类解答数学题的过程:书中给出问题和答案,我们则需要思考并找出解题方法。解题方法通常不止一种,通过大量类似问题的练习,我们不断优化和完善解题思路,最终形成最佳方案。推理模型的强化学习就是让模型生成大量的解题思路,然后从中筛选最优的思路进行训练。
例如 DeepSeek R1 的论文中就展现了模型的整个思考过程,被称为“aha moment”。通过强化学习,模型能够自主地进行“拟人化”的思考、回溯和重新构建。这一过程中模型的思考没有人为干预,而完全由机器自主学习实现。

另一方面,推理模型与大语言模型的另一差异在于计算资源的使用阶段不同。推理模型需要在用户提供提示(prompt)后启动主动“思考”,因此更多的算力消耗发生在实际使用阶段(inference),而非训练阶段(预训练与后训练阶段)。
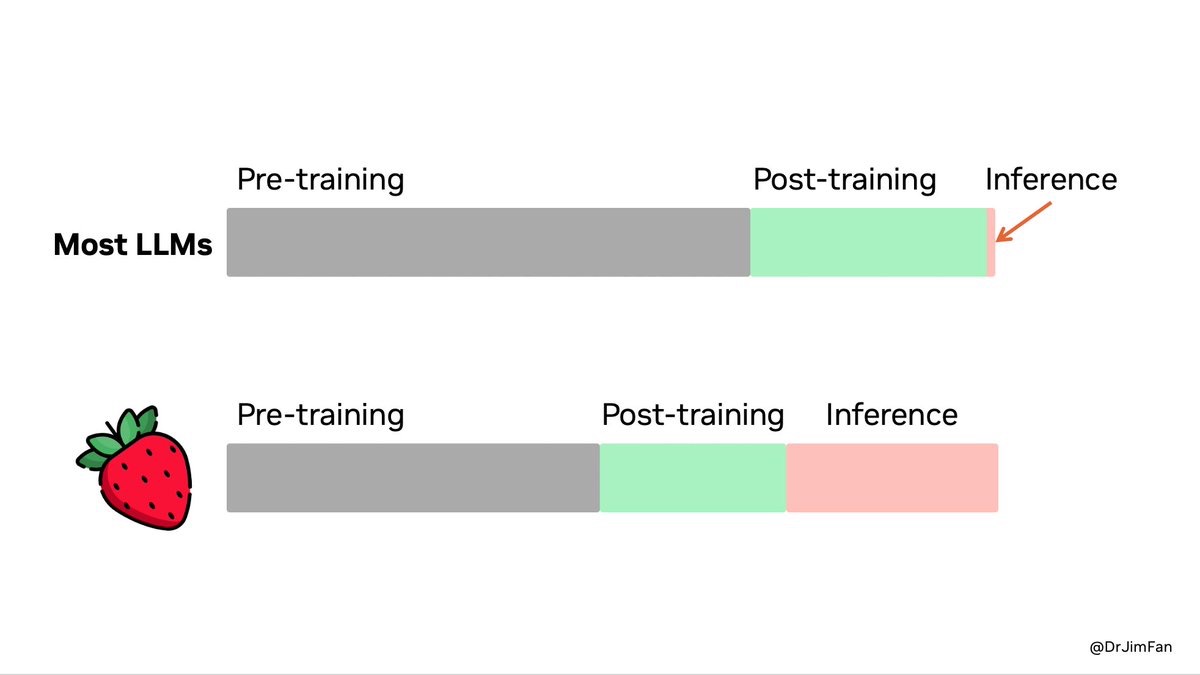
相比之下,大语言模型(LLM)的后训练阶段使用的是基于人类反馈的强化学习(RLHF)。由于语言任务中的诗歌、笑话等内容并没有客观标准答案,人类主观偏好成为判断模型输出质量的关键。因此,首先训练一个奖励模型(Reward Model, RM),模仿人类的价值观和偏好,随后模型再通过强化学习,使生成内容符合人类的偏好。正是由于这种训练方式,大语言模型不可避免地带有一定的偏见。
值得注意的是,尽管我们可以通过像“let's think step by step”这样的提示让大语言模型呈现逐步推理的表现,但这种表现并非真正的强化学习训练产物,而更类似一种即时生成的表面推理。
综合区别如下:
- 后训练阶段区别:大语言模型使用基于人类反馈的强化学习(RLHF),推理模型使用纯强化学习(RL),通过自我博弈进行优化。
- 本质任务区别:大语言模型本质上是预测下一个 token,而推理模型是预测下一条完整的思维链。
- 算力使用阶段区别:大语言模型绝大多数算力投入于预训练阶段,而推理模型的算力更多消耗在实际用户使用阶段(推理阶段)。
# 启发
基于人类反馈的强化学习(RLHF)就像是我们接受了社会主流或权威人士给出的观点与价值观偏好,这里缺乏了自己的独立思考与质疑。我们容易习惯于不假思索地接受外部的评价标准。相比之下,纯粹的强化学习(RL)更像是通过不断自主探索、反复验证,最终找到最优解的批判性思考过程。
# ref.