在学习 ChatGPT相关主题的概念时,我总是会遇到这样的问题:陌生的概念越查越多,什么是人工智能、机器学习、深度学习、神经网络、生成式 AI、大语言模型...... 最后就是饼越铺越大,越来越困惑,最后陷入概念漩涡中。
今天这篇文章的主要目的就是想要解决这个问题,在深入理解 ChatGPT 的工作原理前,先厘清ChatGPT 在整个 AI 领域中的位置,以及与它相关的上下级概念。
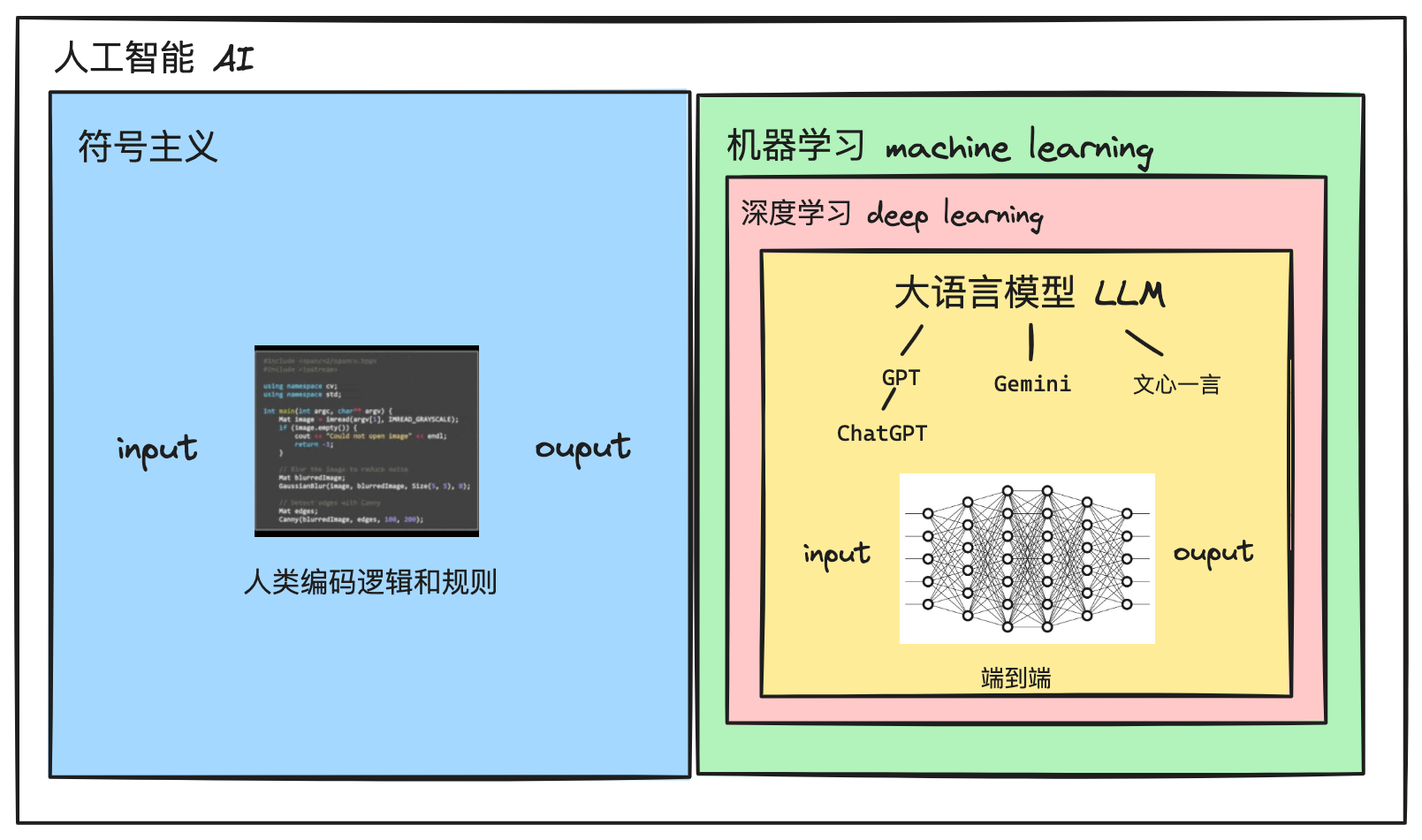
## 人工智能 AI
**人工智能**,英文的全称为Artificial Intelligence。其实AI 作为一门独立的科学学科建立的时间并不久远,它是在 1956 年由约翰·麦卡锡等人在达特茅斯学院发起的,所以也称为“**达特茅斯会议**”。会议对于人工智能的愿景是这样描述的:“我们将尝试寻找方法,让机器学会使用语言、形成抽象概念、解决只有人类才能解决的问题,并且能够自我提升。”[^1]AI这一术语也是在这次会议中首次提出的。
现在我们经常听说的narrow AI、AGI、ASI都是围绕人工智能概念的向下分级。
- narrow AI:狭义人工智能,意思是仅限于完成特定的类人任务的 AI。例如苹果手机中的 siri 助手或是达到人类大师级别的AlphaGo。在狭义人工智能领域,AI 已经超越了全人类,例如打败 AlphaGo 的[[AlphaZero]],和获得 2024 年诺贝尔奖的AlphaFold。
- AGI:全称为"通用人工智能"(Artificial General Intelligence),维基百科给出的定义是“具备与人类同等智能、或超越人类的人工智能,能表现正常人类所具有的所有智能行为。” 与 narrowAI 的区别在于,AGI 可以完成多种类人任务,而非单一任务。例如我们现在常见的各种[[LLM 大语言模型]],ChatGPT、Bard 等。
- ASI:全称为“超级智能”(Artifical Superintelligence)。人类目前对这一阶段的人工智能的设想是超越100% 人类的超级智能体。
2024 年,我们不断听到关于 AI 彻底颠覆人类世界的消息,OpenAI 的 CEO Sam Altman说 :“AGI 将在 2025 年实现,ASI 可能在“几千天内”实现。”DeepMind CEO Demis Hassabi说:“AI 离彻底改变人类社会只有 10 年。”就在刚刚结束的NeurIPS(原名为[[NIPS]])大会上,ilya也给出了他对于ASI的思考,ilya认为超级智能的实现,将重新定义人类在宇宙中的位置,我们需要思考如何与之共存。[^2]
## 深度学习 Deep Learning
在人工智能领域研究的前三十年里,AI主流的研究方向是[[符号人工智能]]、[[专家系统]],即依赖于人类编码逻辑和规则,模拟人类专家在特定领域内的推理和决策过程。例如一个典型的例子是“积木世界”。
积木世界是我们如何与世界交互的简化版本,AI 科学家通过在实验室里与积木进行交互来模拟现实世界,例如人类输入“拿起大的红色方块积木”这样的自然语言指令,然后机器执行。然而实现这些指令的背后原因,其实都是由人类提前设想到,然后人为编辑到规则里的。可是现实的世界相较积木世界要复杂得多。在现实世界中,情况非常多变,物体并不会像积木那样简单可控,光线也不可能像实验室中那样始终保持不变,所以就算是最聪明的人类也不可能把各种可能性全部想到。这就会导致依赖于人类编码规则的这种方式,缺乏在真实世界中的通用性与扩展性,这样的人工智能无法用于解决真实世界中的真实问题。
总结一下专家系统的问题 :
- 可扩展性:人类不可能把所有的规则都想到,编辑到程序里。
- 假设性世界:实验室是一个虚拟的、不真实的世界,结果并不适用于现实世界。

这一问题后来由AI 领域中的另一重要子领域 - **机器学习 Machine Learning**解决了。机器学习解决的是人类硬编码规则的问题,关注如何让计算机通过数据 **“学习”** 某种模式或规则。而**深度学习**又是机器学习领域的一个重要分支。
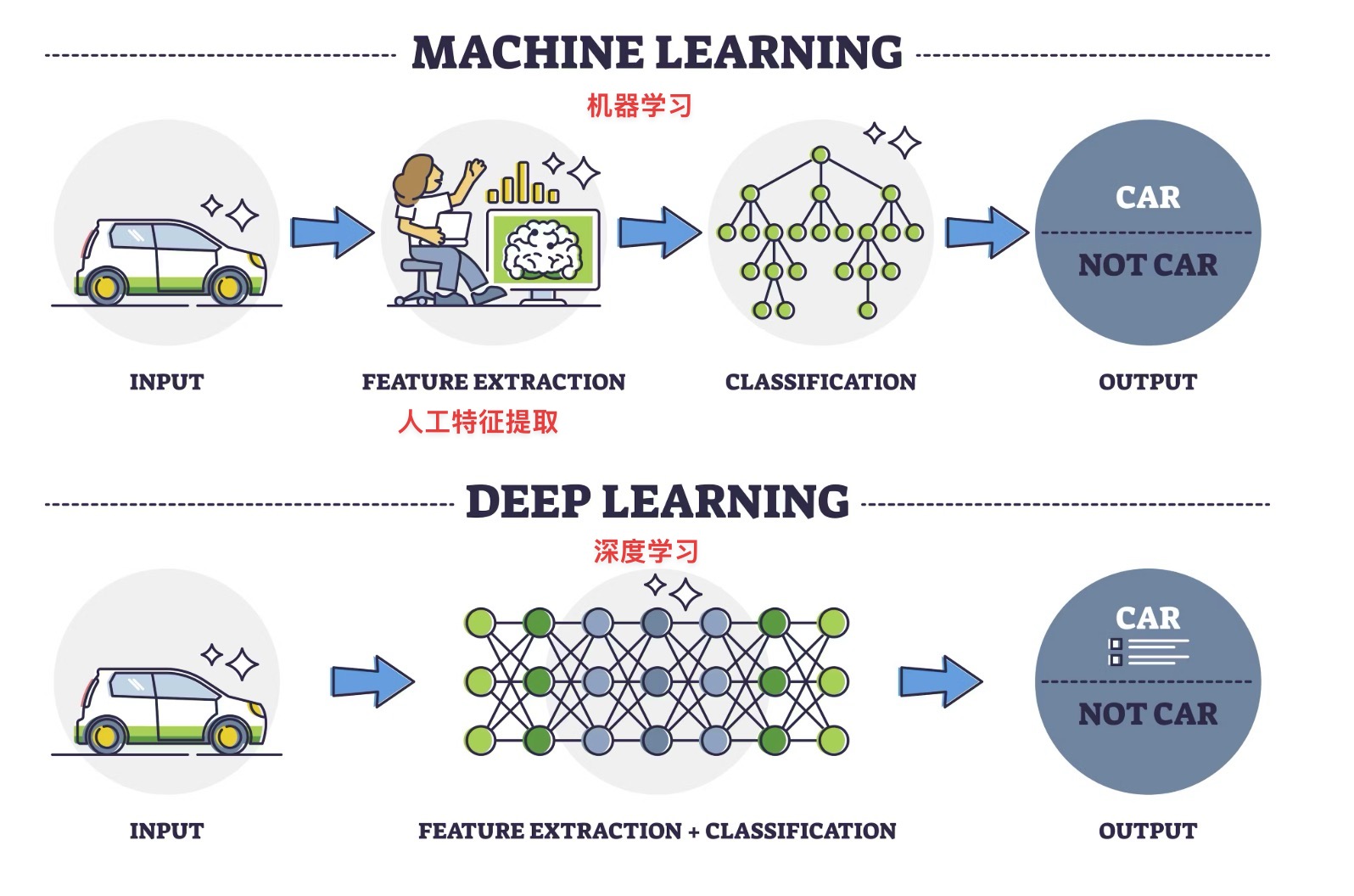
深度学习在维基百科中的定义是:“一种以[[ANN 人工神经网络]]为架构,对资料进行[[特征学习 Feature learning|表征学习]]的算法。深度学习中的形容词“深度”是指在网络中使用多层。”下面我将对这句话进行具体的解释。
**人工神经网络**:人工神经网络是深度学习的核心概念,可以说两个概念是互等的。人工神经网络是受人类大脑的启发而建立的模型,人类的大脑有 1000 亿个神经元细胞,万亿的突触联结,正是这个大脑神经网络让人类具备了强于其它物种的学习能力。人工神经网络这一概念可以追溯到上世纪 50 年代,AI诞生之时。但正如前面所说,以编写规则为主导的符号人工智能曾主宰了 AI 领域三十年,因此“神经网络”在当时并不是什么时髦的词汇,甚至如果论文中出现“神经网络”几个字都会被直接拒绝。
神经网络还有很多替代词:关联记忆、PDP平行分布式处理、连接主义。2007 年,深度学习之父[[Geoffrey Hinton 辛顿]]对这一领域进行了品牌重塑,改名为「深度学习 Deep Learning」。(**补充**:辛顿的突破性成果是“反向传播算法”(backpropagation)和“受限玻尔兹曼机”。)
**表征学习**:深度学习不同于其他机器学习的一点是,它是一种[[端到端]]的学习方式。在其他的机器学习中,数据必须由人类进行特征提取后,才能够让机器进行学习,但是深度学习的设定是让机器像人类婴儿理解周围世界那样,直接对周围的世界进行表征学习和模式识别,没有人为干预。(**补充**:可以提到卷积神经网络(CNN)和循环神经网络(RNN)作为深度学习早期的代表性架构。)
**深度**:“深度”指的是神经网络中的隐藏层,层数越多越能提取数据中的高层次特征。ilya 曾在十年前假设,如果一个神经网络拥有十层,就能瞬间完成类人任务,而现在的大语言模型都是可以达到几十层或上百层的大型神经网络。
## 大语言模型 LLM, Large Language Model
大语言模型就是当今最火的语言模型产品背后的工作原理,例如 OpenAI 公司的GPT3.5、GPT4、 Google 的Gemini和百度的文心一言等。这些模型背后的工作原理都是基于**利用海量文本数据训练的神经网络模型,通过对上下文的理解来预测文本序列的下一词(Token)**。
**token**的中文翻译是词元,即文本的最小不可分割单位,词元可以是某个单词的一部分,也可以单词、标点、数字、符号、空格; 1token≈0.75 word、0.5汉字。
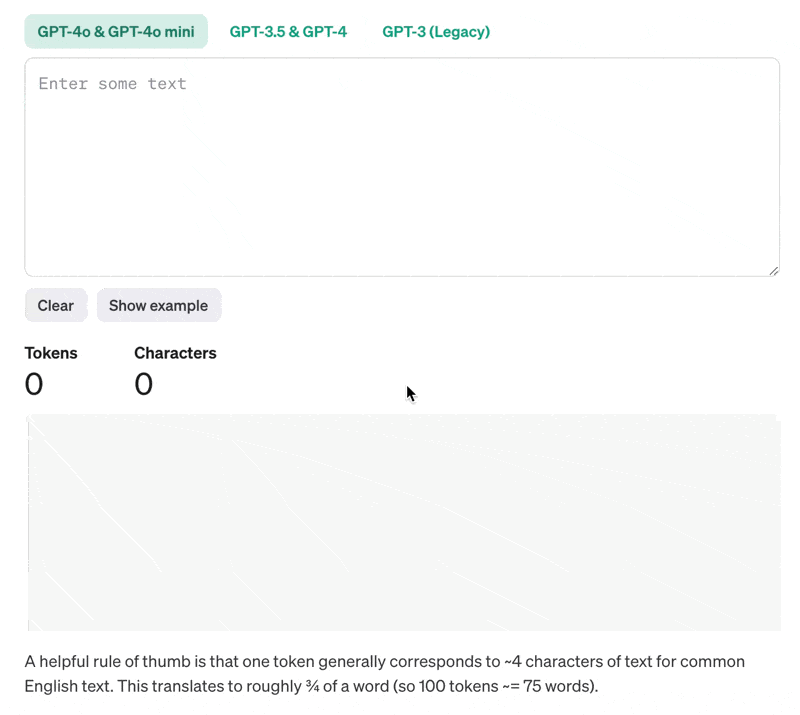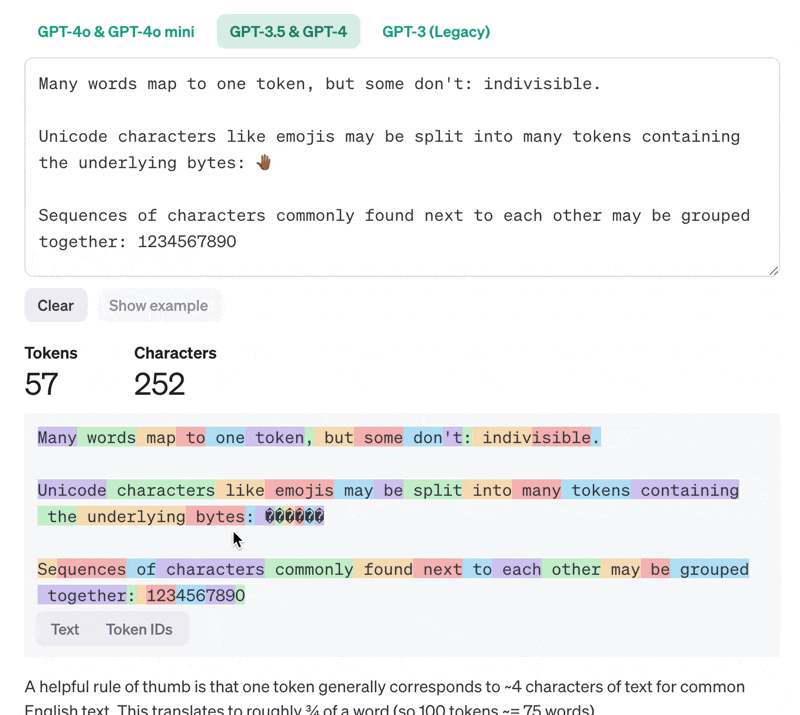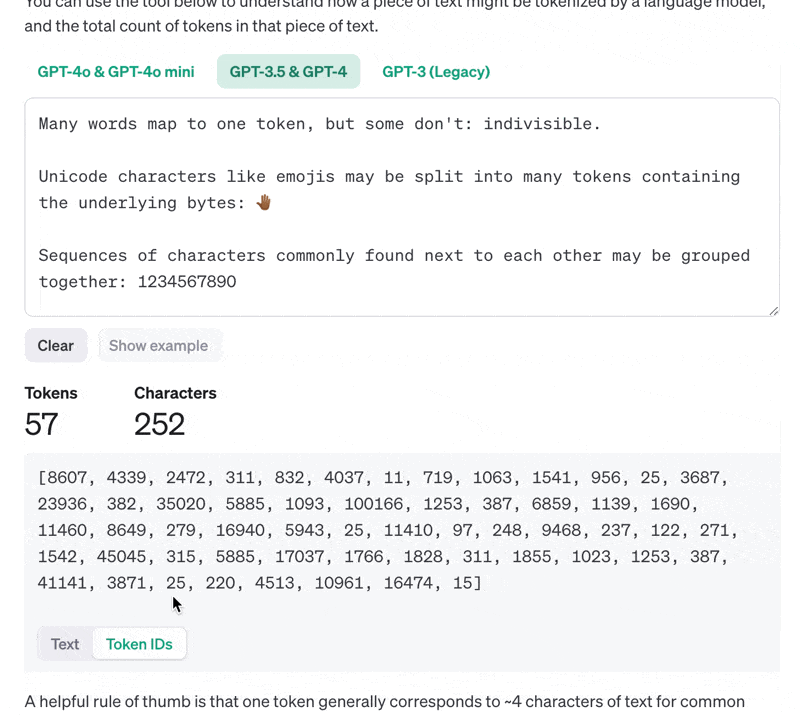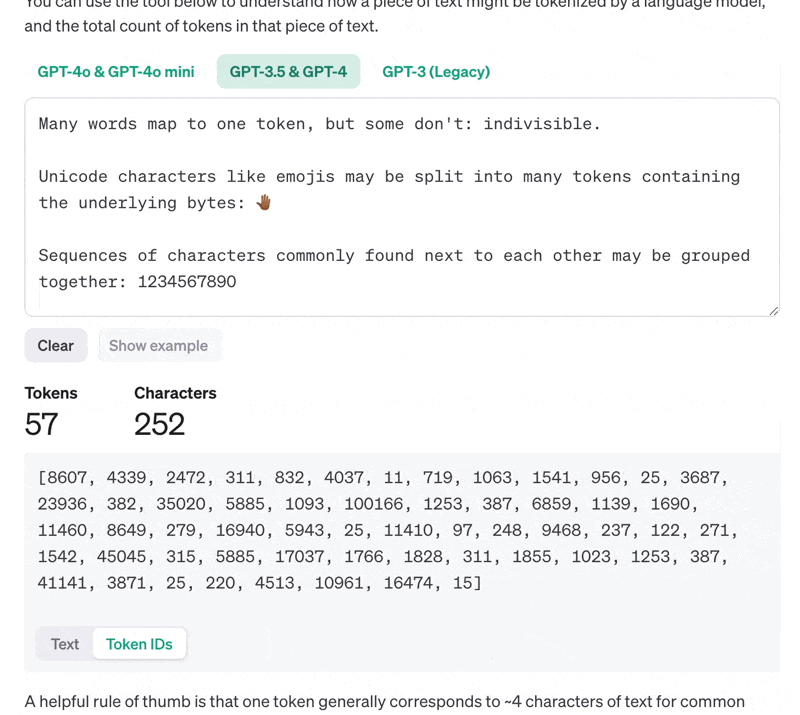
本质上,大语言模型只做一件事:”根据前面的信息,来预测下一个 token的概率分布。“这看似好像是非常简单的事情,但为什么会让大语言模型成功了?或者说为什么当下的大语言模型对语言和知识的理解能够达到人类水平?这是因为三个必不可少的条件:大数据、大模型、大算力。

### 大数据
人类获取知识的方式是通过外界的信息,这种信息可能是书籍、知识视频或者是互联网上的文章。而大模型的“阅读材料”来自于互联网上的原生文本数据,比如全部维基百科的词条,模型会经过好几轮的训练。像 GPT4 这样的大模型已经把全人类的知识都学习了很多遍了。

### 大模型
人类学习的物质基础是大脑神经网络,大模型的物质基础则是人工神经网络。数据会在这个“机器大脑”中进行“学习”,然后形成自己的“理解”,生成新的、从未见过的内容。([[自回归生成模型]],也是一种[[生成式 AI]])
当今最主流的大型神经网络就是[[transformer]]。transformer的核心优势是机器学会了通过上下文的语境和单个词的权重来理解内容。
- **并行处理**:在 transformer 之前的神经网络架构(例如 RNN 或 LSTM)在处理内容时都是顺序进行的,比如要理解“今天天气很好。”这句话,需要先知道“今天”才能生成“天气”,然后才能生成“很好”。这样一来,如果内容太长就会被模型“忘记”,而且这种一次处理一个词的顺序处理方式也非常慢。而Transformer则通过一种**并行化**的方式来解决这个问题,能够同时处理整个上下文的内容,不仅**提高了计算速度**,而且还能够更好地理解更长的内容。
- **[[自注意力机制]]**:Transformer的**核心**是**自注意力机制(Self-Attention)**。它让模型在处理一个词时,不仅只关注它前面的词,还能够**同时关注**到上下文(在 GPT-3 中,这个上下文长度为2048个token,在 GPT-4o 中是 128k token)中所有其他位置的词,从而更好地理解每个词之间的关系,并得出哪些词是重要的(需要更多注意力),哪些是不重要的。这就相当于每个词在看其他词的“重要性”。就像我们在阅读时,也会把更多的注意力放在更重要的**关键词**上。
### 大算力
其实在 1950-60 年代,基于神经网络的方法曾有过一小段时间的兴起,但很快就又衰落了,原因之一就是因为硬件还没有成熟。我在一篇文章里看到Hinton 做过这样一个假设计算:“假设在1985年,他开始不停歇地在一台高速计算机上运行一个程序。如今只需不到一秒钟的时间就可以赶上。”[^3]大语言模型的大量算力都集中在了训练过程中的[[Pre-training 预训练]](pre-trained)这个环节,需要上千块GPU,运行几个月,花费上百万美元。
### 大模型真的理解现实世界吗?
大语言模型横空出世两年以来,总是听到一种观点:“这个东西不是真的理解世界,不过是鹦鹉学舌。”
我选用了一个来自《智慧星球》[^4] 中有关于“理解“的例子:
> “街头募捐者:想不想买一面皇家全国救生船协会的旗? 过路人:不买,谢谢!我总是在伯明翰我妹妹那度假。”
作为一个从没去过英国,也不怎么读历史的中国人,我无法理解这句话,也不觉得它很幽默。
但是我问了chatGPT。chatGPT 不仅识别到了过路人的“幽默感”,而且还解释了为什么这样回答的原因,这里涉及到的知识点有:皇家全国救生船协会是什么?伯明翰在英国的地理位置是哪里?英国的街头募捐的文化背景,以及人们经常找各种理由拒绝募捐的可能性。
在这个案例上,作为人类的我因为不具备这些世界知识,所以我没能理解句子中的幽默,但是 GPT 做到了。

如今的模型,不仅可以通过文字来理解世界,还能通过音频、图片、视频甚至是在线视频的形式来理解世界。我认为这是真正的理解,不是简单的鹦鹉学舌。
## ChatGPT
所以 ChatGPT 是大语言模型的一个产品。同类型的产品除了上面提到的 Gemini、文心一言,还有Google 的 Gemini、Meta 的LLaMA等等。其中以 2022 年 11 月发布的 ChatGPT 最为典型。GPT 的全称叫做 Generative Pre-trained Transformer。从命名的角度来看 GPT 将大语言模型最重要的核心融汇成了这个名字:
- ChatGPT首先是一个生成式 AI(Generative,G)生成从未见过的新的内容;
- 大语言模型的训练过程,其中的 99% 集中在了预训练这个环节(Pre-trained,P)
- 它的核心神经网络架构是 transformer(T)
- Chat则是它与人类的交互方式。
自GPT3.5 模型问世以来,我们已经进入了AI时代。2025 年,AI将会以更加直接的方式影响我们的工作、学习与生活。对我来说,如果能够理解一些原理,在使用时也会更加高效。

# ref.
[^1]: 《奇点更近》雷·库兹韦尔
[^2]:[“AI 大神” Ilya炸裂宣判:大模型预训练时代即将终结!](https://mp.weixin.qq.com/s/Bkw59QC7hufC1FrqW3wUGQ?__readwiseLocation=)
[^3]: [30年冷板凳,诺贝尔物理学奖得主Hinton的AI往事](https://readwise.io/reader/shared/01jf6j5p1kezx8qg2s1bfpcvfx)
[^4]: https://www.candobear.com/