GPT(Generative Pre-trained Transformer)分别代表了生成式(Generative)、已预训练的(Pre-trained)和Transformer架构,这三部分共同构成了当前火热的大语言模型(LLM)。
## GPT 中的三个核心概念
- **生成式 AI**:指计算机通过学习海量数据,自主地生成文字、图片、语音甚至视频。实际的应用包括ChatGPT、GPT-4o生成图像、以及视频生成模型sora等。
- **预训练**:指大语言模型的训练通常会经历的一个基本流程,即“预训练(Pretraining)→ 指令微调(SF)→ 奖励模型(RM)→ 基于人类反馈的强化学习(RLHF)”。预训练阶段是整个流程中耗时最长、成本最高并且完全没有人工干预的阶段。
- **Transformer**:是一种由Google Brain团队在2017年论文《Attention Is All You Need》中提出的深度学习架构。Transformer最初用于语言翻译任务,但后来被广泛应用于文本理解、图像处理、语音识别、自动驾驶,甚至蛋白质结构预测等众多领域,因而也被称作“大一统AI架构”。自2020年以来,基于Transformer的生成式AI掀起了新一轮AI技术热潮。
我计划用约五篇文章,以费曼学习法的方式,深入浅出地解释“大语言模型的预训练是如何工作的”。本文作为该系列第一篇,将聚焦预训练过程中的第一步——嵌入(Embedding)。
## 大语言模型的工作流程
我们先从整体上看一下LLM是如何工作的:
1. 用户发送一段文本(Prompt);
2. 文本经过词元化(Tokenization)处理;
3. Token进入嵌入层(Embedding),转换成计算机能理解的高维向量;
4. 向量矩阵输入Transformer,经过多层注意力机制与前馈网络,模型学习并理解上下文,预测下一个单词的概率分布;
5. 输出层通过softmax函数,为词汇表中的每个token计算概率,最高概率的token即为生成的下一个词。
在预训练阶段,整个流程保持一致,只是输入数据变成了从互联网上抓取的大量文本。每生成一个词后,模型都会将其与实际文本进行对比,通过反向传播算法更新模型的权重。

## Token 化处理
预训练的第一步称为Token化。Token(词元)是文本处理的最小单位,可以是一个完整的单词、一部分单词,也可以是标点符号、数字、空格等。这些数据在经过token(词元)化后,每个 token 会被转换成一组对应的数字向量。
进行Token化的原因主要有两个:
- **机器理解**:计算机只能处理数字,通过Token化可以将原始文本转换成数字形式。
- **节约资源**:Token化能极大减少词汇表的规模,从而节省计算资源。
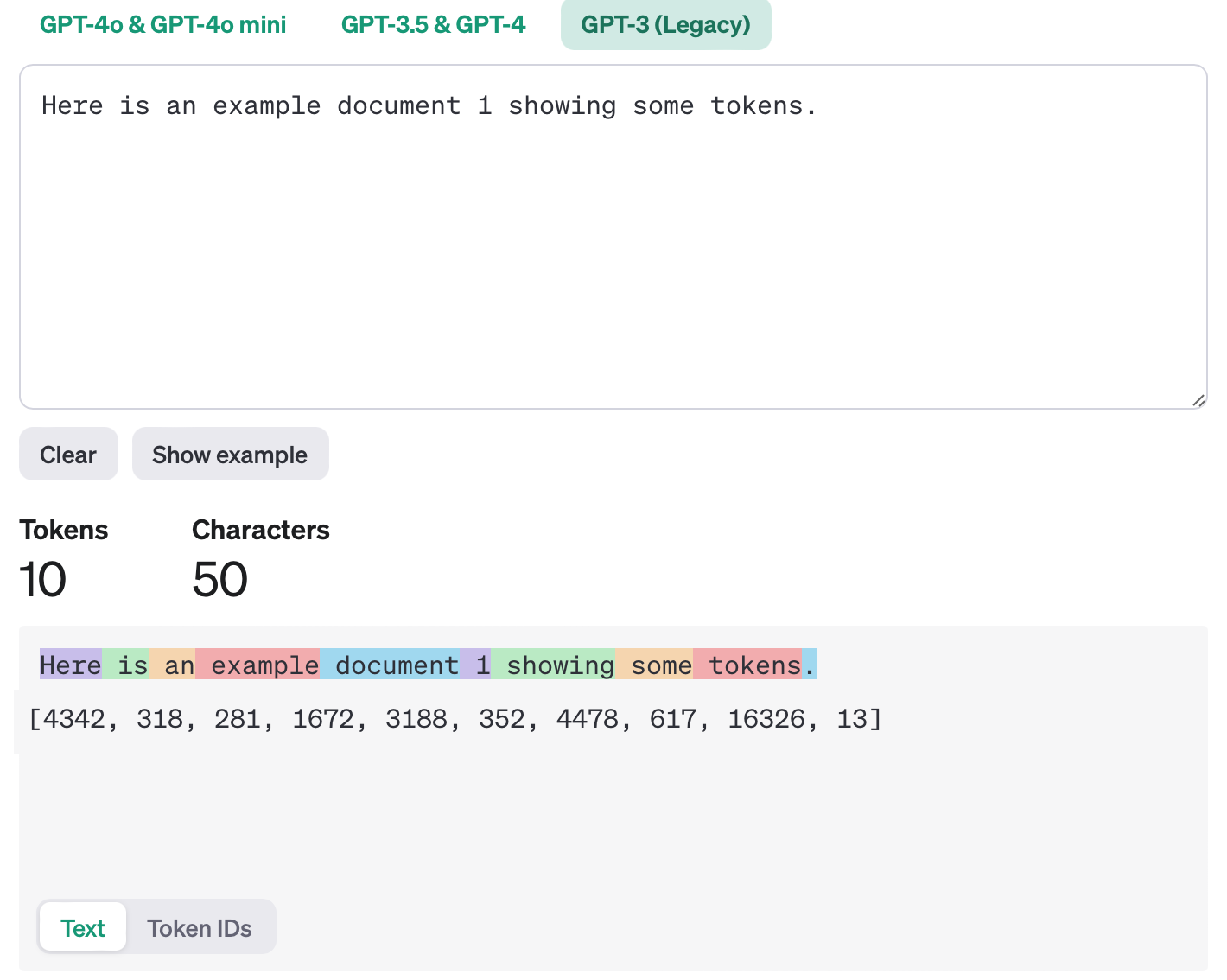
这也是为什么会出现 LLM 不知道 strawberry 中有几个 r 的原因,“strawberry”这个单词在LLM中通常被拆成“str”、“aw”、“berry”三个token,因此模型难以数清单词内有几个字母“r”。
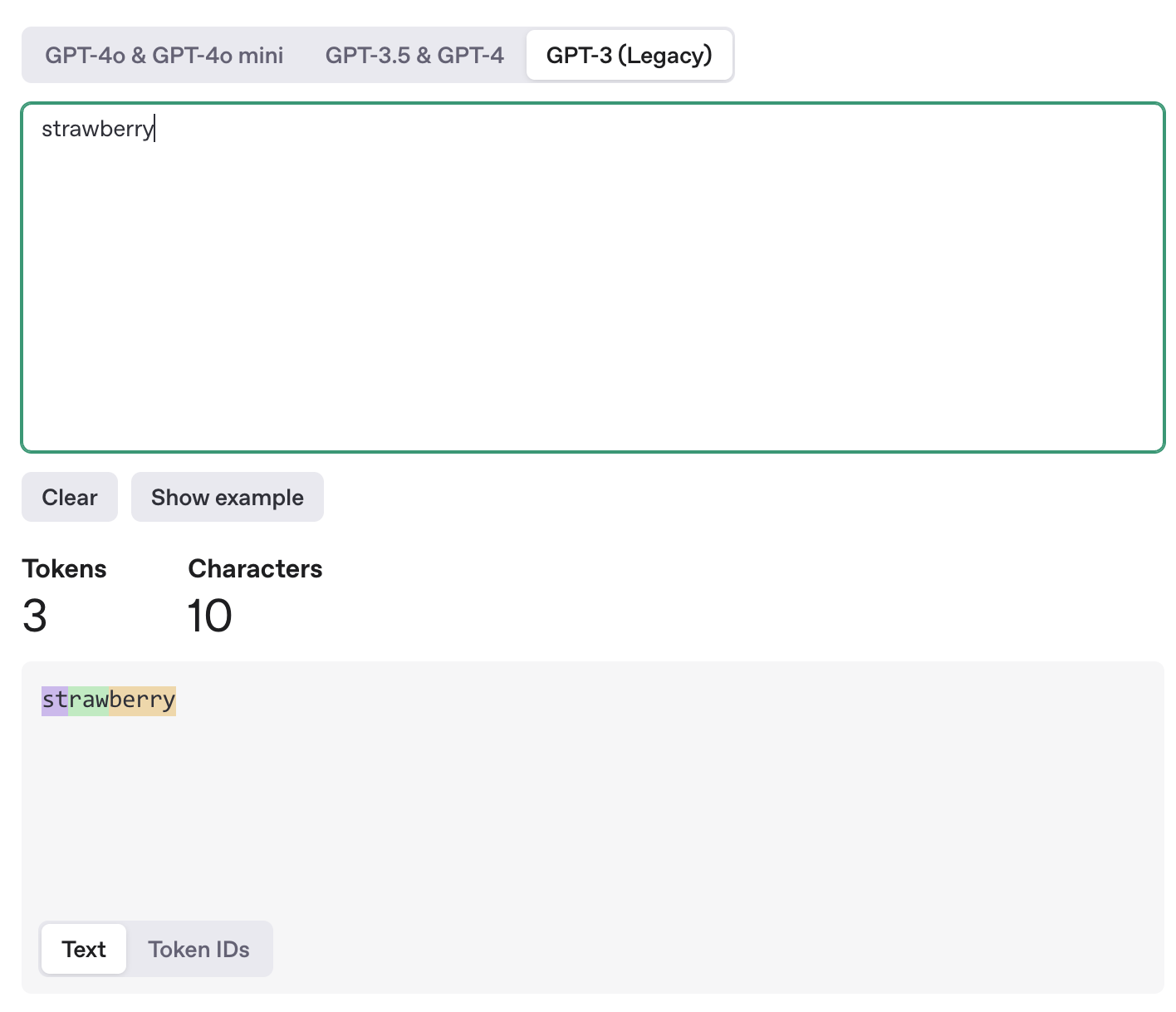
## Embedding(嵌入)的原理
嵌入由两部分组成:词嵌入(Word Embedding)和位置嵌入(Position Embedding)。
### 词嵌入(Word Embedding)
在数据进入嵌入层前,模型已定义好一个词汇表(vocabulary)及其对应的高维空间。词汇表包含了所有可能的单词,每个单词对应一组权重。这里决定了大模型的第一批权重。以GPT-3为例,词汇表大小为$V= 50257$,嵌入维度为$D=12288$。因此,这个嵌入矩阵(Embedding Matrix)共有约6.17亿个权重。
$W_E = D*V ≈ 6.17亿/1750 亿权重$
这些权重一开始是随机初始化的。你可以把它们想象成大脑中的神经元突触:它们决定了模型的初始“认知”状态。随着模型学习过输入的数据后,这些权重不断调整,使模型更准确地理解和生成文本。

### 位置嵌入(Position Embedding)
除了词嵌入,还有位置嵌入,它捕获的是每个token在文本序列中的位置信息。位置嵌入也是以随机权重开始的,长度由模型的上下文长度(context length)决定,即模型每次最多可处理的token数量。
位置嵌入之所以重要,是因为同一个单词在不同上下文中含义可能截然不同。例如,“model”在机器学习中指模型,在时尚界指模特,而在产品参数中则可能表示型号。Transformer架构具有并行处理整个序列的能力,因此必须结合位置嵌入,才能精确理解每个词在特定上下文中的具体含义。以GPT-3为例,上下文长度为 2048,也就是说超过这个长度后就不在模型的上下文理解范围中了,也会表现为“忘记”了此前的对话。但是最新的 GPT-4.5估计有40 万的上下文长度,大概相当于两本书,基本不会受上下文长度的限制了。

### 融合词嵌入和位置嵌入
在进入Transformer模型前,词嵌入和位置嵌入会以元素级相加的方式融合成最终的输入嵌入向量。这种融合方式虽然最初没有严格理论依据,但在实践中被证明是简单有效的。
## 如何直观理解Embedding?
我们可以把Embedding想象成一个巨大的高维语义空间,空间中每个词都有自己的位置和方向。语义相近的词,在空间中会靠得更近。当我们将这个高维空间压缩成二维空间时,可以更直观地观察到词语之间的关系。
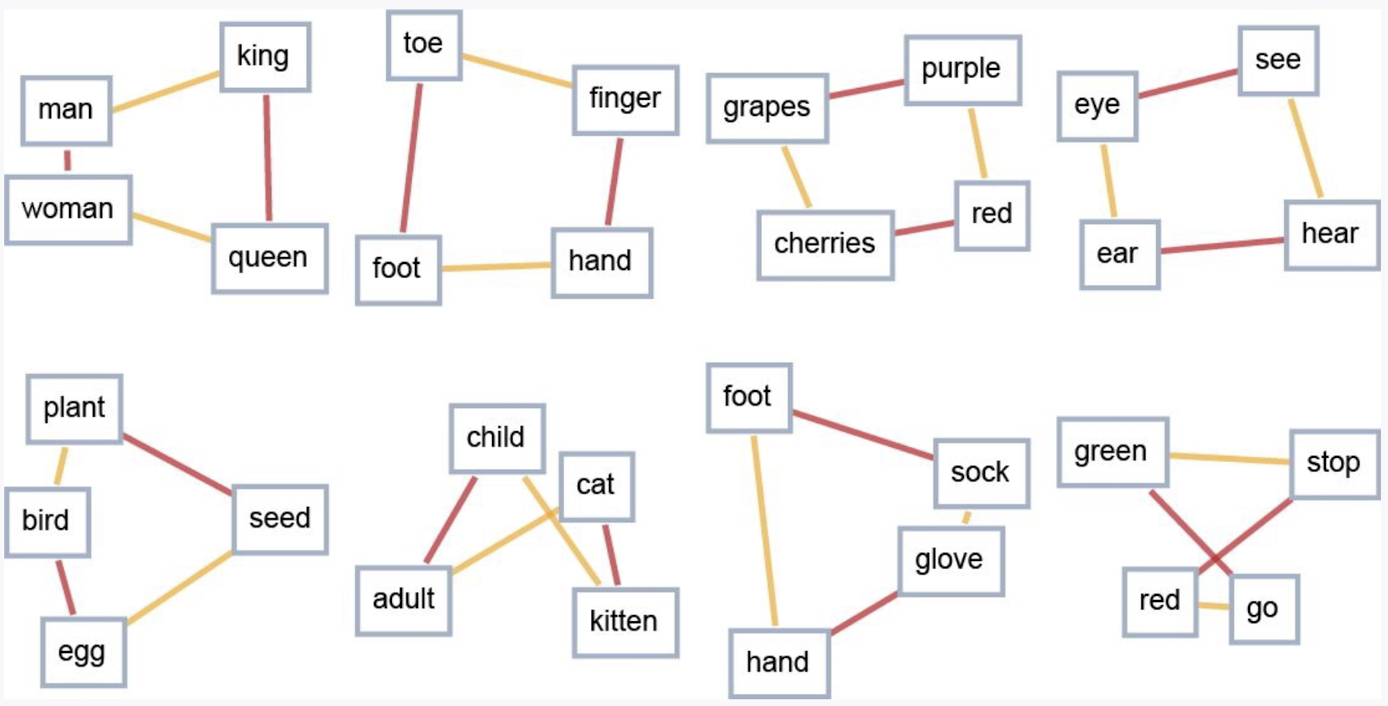
大语言模型的生成过程可以看作是在这个空间中进行的一种“语义运动”:根据前面的文本不断确定方向,进而预测并生成下一个词。
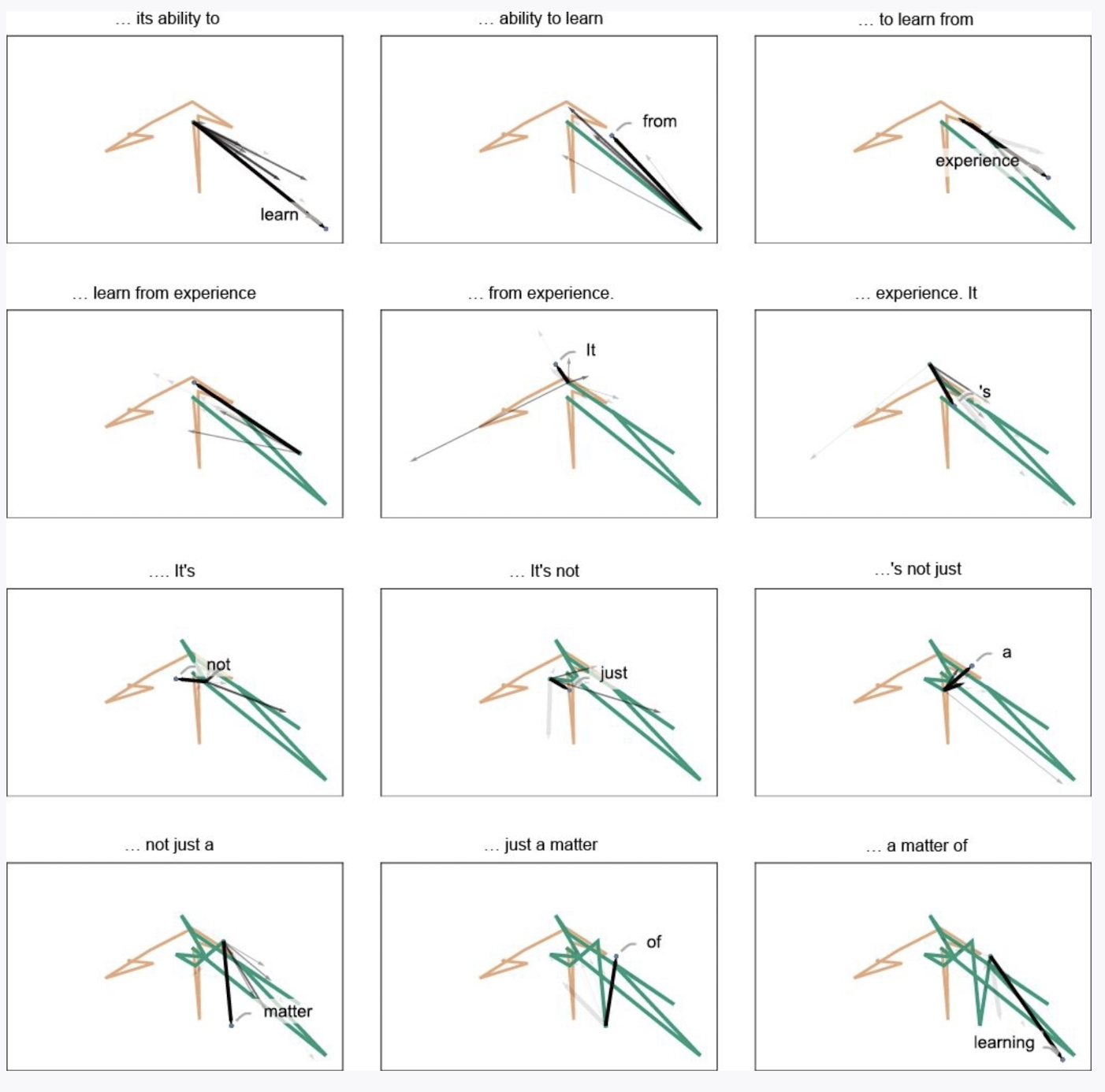
如果你想更直观地理解Embedding,可以访问[LLM visualization](https://bbycroft.net/llm)网站亲自体验,这种交互式的方式会让你更清楚地看到Embedding空间的实际效果,很有趣。

下一篇文章,我将进一步探讨Transformer内部究竟发生了什么。希望能够通过这种逐步拆解、逐层深入的方式,更轻松地理解LLM的工作原理,敬请期待下一篇的更新!
# Ref.
- [Transformers, the tech behind LLMs | Deep Learning Chapter 5](https://www.youtube.com/watch?v=wjZofJX0v4M&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=6)
- [LLM visualization](https://bbycroft.net/llm)
- 《这就是 ChatGPT》